 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveform Design for Partial-Time Superimposed ISAC Systems
Feb 23, 2026Nowadays, waveforms of integrated sensing and communication (ISAC) are almost based on conventional communication and sensing signal, which bounds both the communication and sensing performance. To deal with this issue, in this paper, a novel waveform design is presented for the partial-time superimposed (PTS) ISAC system. At the base station (BS), a parameter-adjustable linear frequency modulation (LFM) pulse signal and a continuous communication orthogonal frequency division multiplexing (OFDM) signal are employed to broadcast public information and perform sensing tasks, respectively, using a PTS scheme. Pulse compression gain enhances the system's long-range sensing capability, while OFDM ensures the system's high-speed data transmission capability. Meanwhile, the LFM signal is utilized as superimposed pilot for channel estimation, which has higher time-frequency resource utilization and stronger real-time performance compared to orthogonal pilots. We present an accurate parameter estimation method of multi-path sensing signal for reconstructing and interference cancellation in communication users. Additionally, a cyclic maximum likelihood method is introduced for channel estimation and the Cramer-Rao lower bound (CRLB) of channel estimation is derived. Simulations demonstrate the accuracy and robustness of the proposed parameter estimation algorithm as well as the improved channel estimation performance over traditional methods. The proposed waveform design method can achieve reliable data transmission and accurate target sensing.
* 15 pages, 17 figures, journal
RL based Beamforming Optimization for 3D Pinching Antenna assisted ISAC Systems
Jan 28, 2026In this paper, a three-dimensional (3D) deployment scheme of pinching antenna array is proposed, aiming to enhances the performance of integrated sensing and communication (ISAC) systems. To fully realize the potential of 3D deployment, a joint antenna positioning, time allocation and transmit power optimization problem is formulated to maximize the sum communication rate with the constraints of target sensing rates and system energy. To solve the sum rate maximization problem, we propose a heterogeneous graph neural network based reinforcement learning (HGRL) algorithm. Simulation results prove that 3D deployment of pinching antenna array outperforms 1D and 2D counterparts in ISAC systems. Moreover, the proposed HGRL algorithm surpasses other baselines in both performance and convergence speed due to the advanced observation construction of the environment.
Deep Learning based Three-stage Solution for ISAC Beamforming Optimization
Jan 28, 2026In this paper, a general ISAC system where the base station (BS) communicates with multiple users and performs target detection is considered. Then, a sum communication rate maximization problem is formulated, subjected to the constraints of transmit power and the minimum sensing rates of users. To solve this problem, we develop a framework that leverages deep learning algorithms to provide a three-stage solution for ISAC beamforming. The three-stage beamforming optimization solution includes three modules: 1) an unsupervised learning based feature extraction algorithm is proposed to extract fixed-size latent features while keeping its essential information from the variable channel state information (CSI); 2) a reinforcement learning (RL) based beampattern optimization algorithm is proposed to search the desired beampattern according to the extracted features; 3) a supervised learning based beamforming reconstruction algorithm is proposed to reconstruct the beamforming vector from beampattern given by the RL agent. Simulation results demonstrate that the proposed three-stage solution outperforms the baseline RL algorithm by optimizing the intuitional beampattern rather than beamforming.
PASS-Enhanced MEC: Joint Optimization of Task Offloading and Uplink PASS Beamforming
Oct 27, 2025A pinching-antenna system (PASS)-enhanced mobile edge computing (MEC) architecture is investigated to improve the task offloading efficiency and latency performance in dynamic wireless environments. By leveraging dielectric waveguides and flexibly adjustable pinching antennas, PASS establishes short-distance line-of-sight (LoS) links while effectively mitigating the significant path loss and potential signal blockage, making it a promising solution for high-frequency MEC systems. We formulate a network latency minimization problem to joint optimize uplink PASS beamforming and task offloading. The resulting problem is modeled as a Markov decision process (MDP) and solved via the deep reinforcement learning (DRL) method. To address the instability introduced by the $\max$ operator in the objective function, we propose a load balancing-aware proximal policy optimization (LBPPO) algorithm. LBPPO incorporates both node-level and waveguide-level load balancing information into the policy design, maintaining computational and transmission delay equilibrium, respectively. Simulation results demonstrate that the proposed PASS-enhanced MEC with adaptive uplink PASS beamforming exhibit stronger convergence capability than fixed-PA baselines and conventional MIMO-assisted MEC, especially in scenarios with a large number of UEs or high transmit power.
CRB minimization for PASS Assisted ISAC
Sep 26, 2025A multiple waveguide PASS assisted integrated sensing and communication (ISAC) system is proposed, where the base station (BS) is equipped with transmitting pinching antennas (PAs) and receiving uniform linear array (ULA) antennas. The PASS-transmitting-ULA-receiving (PTUR) BS transmits the communication and sensing signals through the stretched PAs on waveguides and collects the echo sensing signals with the mounted ULA. Based on this configuration, a target sensing Cramer Rao Bound (CRB) minimization problem is formulated under communication quality-of-service (QoS) constraints, power budget constraints, and PA deployment constraints. An alternating optimization (AO) method is employed to address the formulated non-convex optimization problem. Simulation results demonstrate that the proposed PASS assisted ISAC framework achieves superior performance over benchmark schemes.
Pinching Antenna System for Integrated Sensing and Communications
Aug 27, 2025Recently, the pinching antenna system (PASS) has attracted considerable attention due to their advantages in flexible deployment and reduction of signal propagation loss. In this work, a multiple waveguide PASS assisted integrated sensing and communication (ISAC) system is proposed, where the base station (BS) is equipped with transmitting pinching antennas (PAs) and receiving uniform linear array (ULA) antennas. The full-duplex (FD) BS transmits the communication and sensing signals through the PAs on waveguides and collects the echo sensing signals with the mounted ULA. Based on this configuration, a target sensing Cramer Rao Bound (CRB) minimization problem is formulated under communication quality-of-service (QoS) constraints, power budget constraint, and PA deployment constraints. The alternating optimization (AO) method is employed to address the formulated non-convex optimization problem. In each iteration, the overall optimization problem is decomposed into a digital beamforming sub-problem and a pinching beamforming sub-problem. The sensing covariance matrix and communication beamforming matrix at the BS are optimized by solving the digital beamforming sub-problem with semidefinite relaxation (SDR). The PA deployment is updated by solving the pinching beamforming sub-problem with the successive convex approximation (SCA) method, penalty method, and element-wise optimization. Simulation results show that the proposed PASS assisted ISAC framework achieves superior performance over benchmark schemes, is less affected by stringent communication constraints compared to conventional MIMO-ISAC, and benefits further from increasing the number of waveguides and PAs per waveguide.
Intelligent Travel Activity Monitoring: Generalized Distributed Acoustic Sensing Approaches
Jun 11, 2025Obtaining data on active travel activities such as walking, jogging, and cycling is important for refining sustainable transportation systems (STS). Effectively monitoring these activities not only requires sensing solutions to have a joint feature of being accurate, economical, and privacy-preserving, but also enough generalizability to adapt to different climate environments and deployment conditions. In order to provide a generalized sensing solution, a deep learning (DL)-enhanced distributed acoustic sensing (DAS) system for monitoring active travel activities is proposed. By leveraging the ambient vibrations captured by DAS, this scheme infers motion patterns without relying on image-based or wearable devices, thereby addressing privacy concerns. We conduct real-world experiments in two geographically distinct locations and collect comprehensive datasets to evaluate the performance of the proposed system. To address the generalization challenges posed by heterogeneous deployment environments, we propose two solutions according to network availability: 1) an Internet-of-Things (IoT) scheme based on federated learning (FL) is proposed, and it enables geographically different DAS nodes to be trained collaboratively to improve generalizability; 2) an off-line initialization approach enabled by meta-learning is proposed to develop high-generality initialization for DL models and to enable rapid model fine-tuning with limited data samples, facilitating generalization at newly established or isolated DAS nodes. Experimental results of the walking and cycling classification problem demonstrate the performance and generalizability of the proposed DL-enhanced DAS system, paving the way for practical, large-scale DAS monitoring of active travel.
Mobile Edge Generation-Enabled Digital Twin: Architecture Design and Research Opportunities
Jul 03, 2024A novel paradigm of mobile edge generation (MEG)-enabled digital twin (DT) is proposed, which enables distributed on-device generation at mobile edge networks for real-time DT applications. First, an MEG-DT architecture is put forward to decentralize generative artificial intelligence (GAI) models onto edge servers (ESs) and user equipments (UEs), which has the advantages of low latency, privacy preservation, and individual-level customization. Then, various single-user and multi-user generation mechanisms are conceived for MEG-DT, which strike trade-offs between generation latency, hardware costs, and device coordination. Furthermore, to perform efficient distributed generation, two operating protocols are explored for transmitting interpretable and latent features between ESs and UEs, namely sketch-based generation and seed-based generation, respectively. Based on the proposed protocols, the convergence between MEG and DT are highlighted. Considering the seed-based image generation scenario, numerical case studies are provided to reveal the superiority of MEG-DT over centralized generation. Finally, promising applications and research opportunities are identified.
Hybrid Reinforcement Learning for STAR-RISs: A Coupled Phase-Shift Model Based Beamformer
May 10, 2022
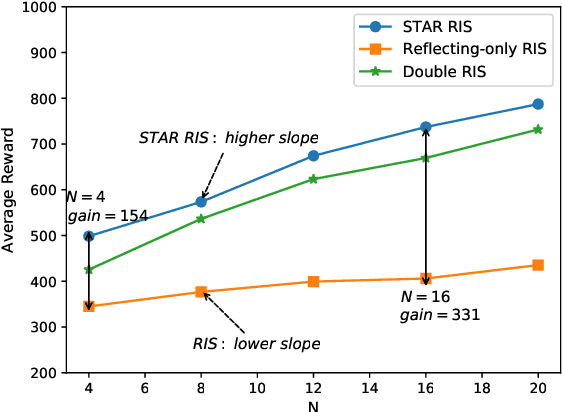
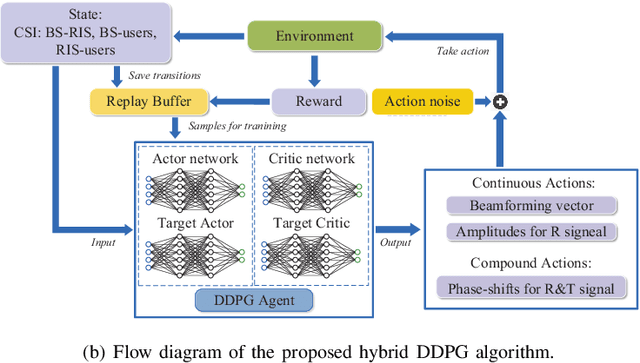

A simultaneous transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisted multi-user downlink multiple-input single-output (MISO) communication system is investigated. In contrast to the existing ideal STAR-RIS model assuming an independent transmission and reflection phase-shift control, a practical coupled phase-shift model is considered. Then, a joint active and passive beamforming optimization problem is formulated for minimizing the long-term transmission power consumption, subject to the coupled phase-shift constraint and the minimum data rate constraint. Despite the coupled nature of the phase-shift model, the formulated problem is solved by invoking a hybrid continuous and discrete phase-shift control policy. Inspired by this observation, a pair of hybrid reinforcement learning (RL) algorithms, namely the hybrid deep deterministic policy gradient (hybrid DDPG) algorithm and the joint DDPG & deep-Q network (DDPG-DQN) based algorithm are proposed. The hybrid DDPG algorithm controls the associated high-dimensional continuous and discrete actions by relying on the hybrid action mapping. By contrast, the joint DDPG-DQN algorithm constructs two Markov decision processes (MDPs) relying on an inner and an outer environment, thereby amalgamating the two agents to accomplish a joint hybrid control. Simulation results demonstrate that the STAR-RIS has superiority over other conventional RISs in terms of its energy consumption. Furthermore, both the proposed algorithms outperform the baseline DDPG algorithm, and the joint DDPG-DQN algorithm achieves a superior performance, albeit at an increased computational complexity.
Path Design and Resource Management for NOMA enhanced Indoor Intelligent Robots
Nov 26, 2020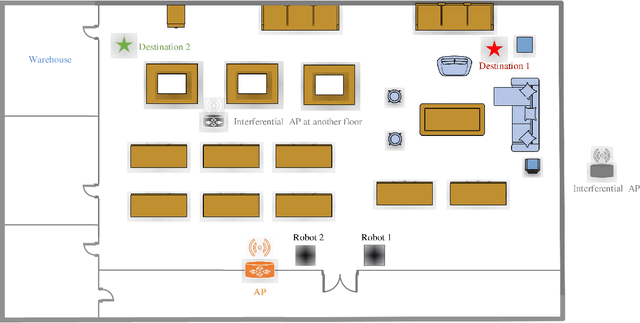
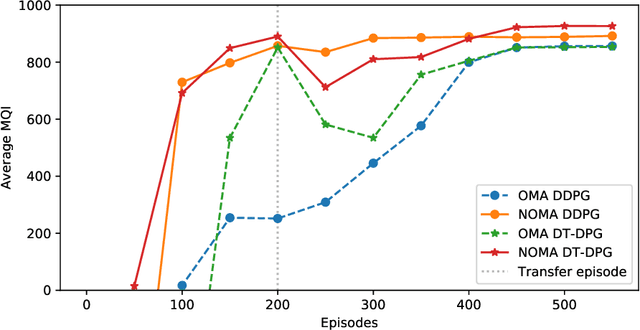
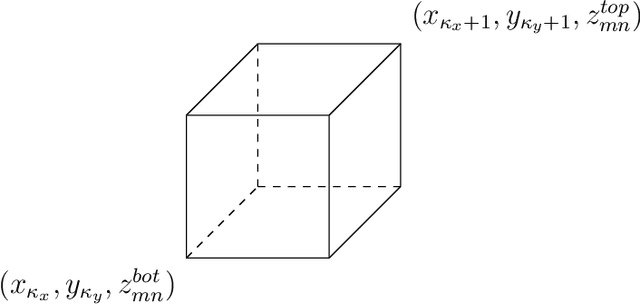
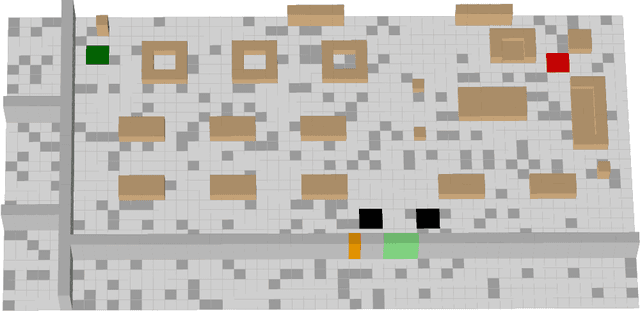
A communication enabled indoor intelligent robots (IRs) service framework is proposed, where non-orthogonal multiple access (NOMA) technique is adopted to enable highly reliable communications. In cooperation with the ultramodern indoor channel model recently proposed by the International Telecommunication Union (ITU), the Lego modeling method is proposed, which can deterministically describe the indoor layout and channel state in order to construct the radio map. The investigated radio map is invoked as a virtual environment to train the reinforcement learning agent, which can save training time and hardware costs. Build on the proposed communication model, motions of IRs who need to reach designated mission destinations and their corresponding down-link power allocation policy are jointly optimized to maximize the mission efficiency and communication reliability of IRs. In an effort to solve this optimization problem, a novel reinforcement learning approach named deep transfer deterministic policy gradient (DT-DPG) algorithm is proposed. Our simulation results demonstrate that 1) With the aid of NOMA techniques, the communication reliability of IRs is effectively improved; 2) The radio map is qualified to be a virtual training environment, and its statistical channel state information improves training efficiency by about 30%; 3) The proposed DT-DPG algorithm is superior to the conventional deep deterministic policy gradient (DDPG) algorithm in terms of optimization performance, training time, and anti-local optimum ability.