 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Multimodal Foundation Models Understand Enterprise Workflows? A Benchmark for Business Process Management Tasks
Jun 19, 2024



Existing ML benchmarks lack the depth and diversity of annotations needed for evaluating models on business process management (BPM) tasks. BPM is the practice of documenting, measuring, improving, and automating enterprise workflows. However, research has focused almost exclusively on one task - full end-to-end automation using agents based on multimodal foundation models (FMs) like GPT-4. This focus on automation ignores the reality of how most BPM tools are applied today - simply documenting the relevant workflow takes 60% of the time of the typical process optimization project. To address this gap we present WONDERBREAD, the first benchmark for evaluating multimodal FMs on BPM tasks beyond automation. Our contributions are: (1) a dataset containing 2928 documented workflow demonstrations; (2) 6 novel BPM tasks sourced from real-world applications ranging from workflow documentation to knowledge transfer to process improvement; and (3) an automated evaluation harness. Our benchmark shows that while state-of-the-art FMs can automatically generate documentation (e.g. recalling 88% of the steps taken in a video demonstration of a workflow), they struggle to re-apply that knowledge towards finer-grained validation of workflow completion (F1 < 0.3). We hope WONDERBREAD encourages the development of more "human-centered" AI tooling for enterprise applications and furthers the exploration of multimodal FMs for the broader universe of BPM tasks. We publish our dataset and experiments here: https://github.com/HazyResearch/wonderbread
Intention and Context Elicitation with Large Language Models in the Legal Aid Intake Process
Nov 22, 2023
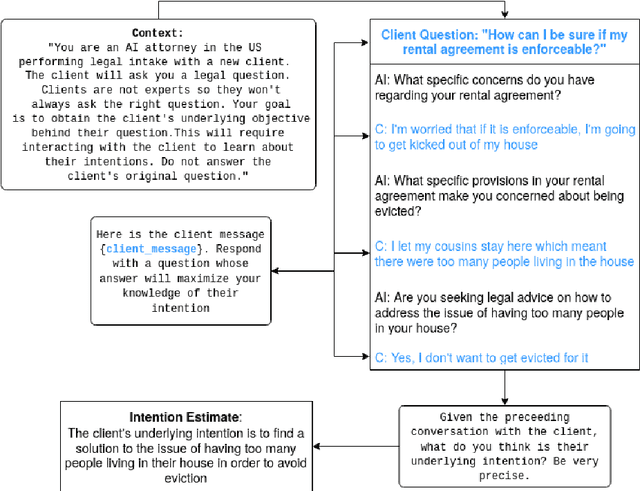
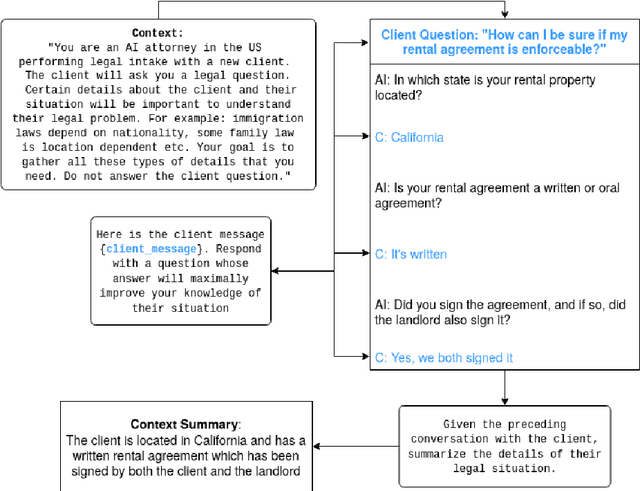
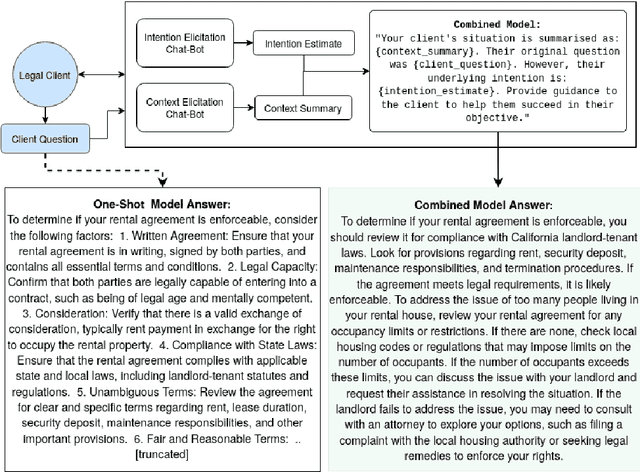
Large Language Models (LLMs) and chatbots show significant promise in streamlining the legal intake process. This advancement can greatly reduce the workload and costs for legal aid organizations, improving availability while making legal assistance more accessible to a broader audience. However, a key challenge with current LLMs is their tendency to overconfidently deliver an immediate 'best guess' to a client's question based on the output distribution learned over the training data. This approach often overlooks the client's actual intentions or the specifics of their legal situation. As a result, clients may not realize the importance of providing essential additional context or expressing their underlying intentions, which are crucial for their legal cases. Traditionally, logic based decision trees have been used to automate intake for specific access to justice issues, such as immigration and eviction. But those solutions lack scalability. We demonstrate a proof-of-concept using LLMs to elicit and infer clients' underlying intentions and specific legal circumstances through free-form, language-based interactions. We also propose future research directions to use supervised fine-tuning or offline reinforcement learning to automatically incorporate intention and context elicitation in chatbots without explicit prompting.
DABS: A Domain-Agnostic Benchmark for Self-Supervised Learning
Nov 23, 2021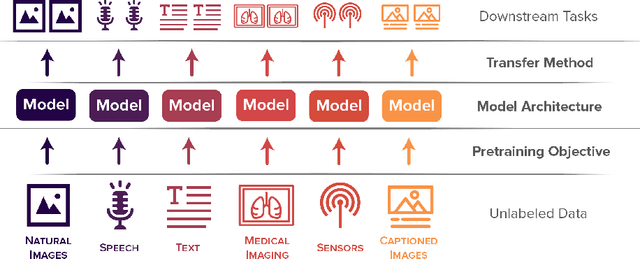

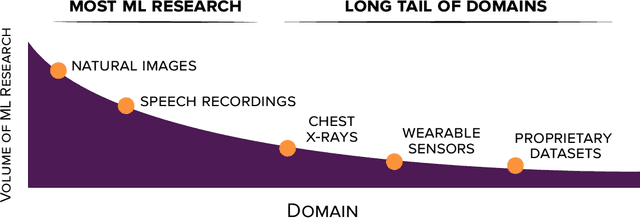
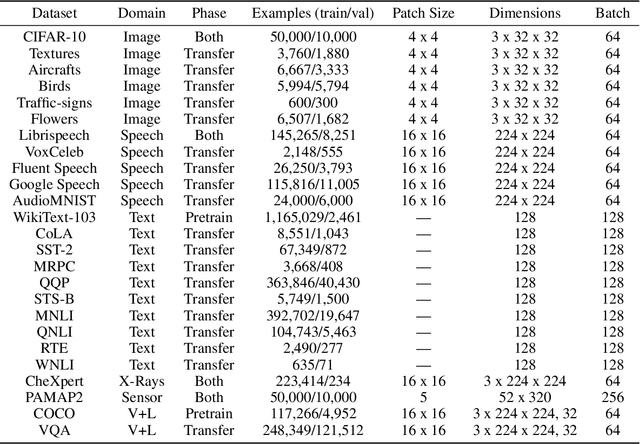
Self-supervised learning algorithms, including BERT and SimCLR, have enabled significant strides in fields like natural language processing, computer vision, and speech processing. However, these algorithms are domain-specific, meaning that new self-supervised learning algorithms must be developed for each new setting, including myriad healthcare, scientific, and multimodal domains. To catalyze progress toward domain-agnostic methods, we introduce DABS: a Domain-Agnostic Benchmark for Self-supervised learning. To perform well on DABS, an algorithm is evaluated on seven diverse domains: natural images, multichannel sensor data, English text, speech recordings, multilingual text, chest x-rays, and images with text descriptions. Each domain contains an unlabeled dataset for pretraining; the model is then is scored based on its downstream performance on a set of labeled tasks in the domain. We also present e-Mix and ShED: two baseline domain-agnostic algorithms; their relatively modest performance demonstrates that significant progress is needed before self-supervised learning is an out-of-the-box solution for arbitrary domains. Code for benchmark datasets and baseline algorithms is available at https://github.com/alextamkin/dabs.