 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLouvreSAE: Sparse Autoencoders for Interpretable and Controllable Style Transfer
Dec 22, 2025Artistic style transfer in generative models remains a significant challenge, as existing methods often introduce style only via model fine-tuning, additional adapters, or prompt engineering, all of which can be computationally expensive and may still entangle style with subject matter. In this paper, we introduce a training- and inference-light, interpretable method for representing and transferring artistic style. Our approach leverages an art-specific Sparse Autoencoder (SAE) on top of latent embeddings of generative image models. Trained on artistic data, our SAE learns an emergent, largely disentangled set of stylistic and compositional concepts, corresponding to style-related elements pertaining brushwork, texture, and color palette, as well as semantic and structural concepts. We call it LouvreSAE and use it to construct style profiles: compact, decomposable steering vectors that enable style transfer without any model updates or optimization. Unlike prior concept-based style transfer methods, our method requires no fine-tuning, no LoRA training, and no additional inference passes, enabling direct steering of artistic styles from only a few reference images. We validate our method on ArtBench10, achieving or surpassing existing methods on style evaluations (VGG Style Loss and CLIP Score Style) while being 1.7-20x faster and, critically, interpretable.
DABS: A Domain-Agnostic Benchmark for Self-Supervised Learning
Nov 23, 2021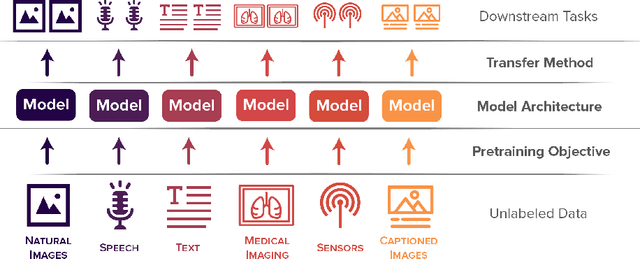

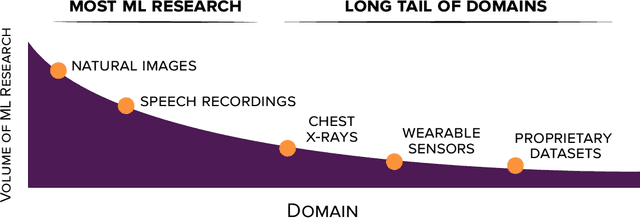
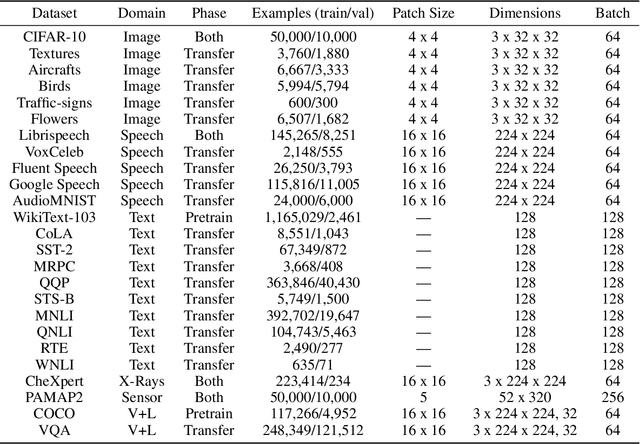
Self-supervised learning algorithms, including BERT and SimCLR, have enabled significant strides in fields like natural language processing, computer vision, and speech processing. However, these algorithms are domain-specific, meaning that new self-supervised learning algorithms must be developed for each new setting, including myriad healthcare, scientific, and multimodal domains. To catalyze progress toward domain-agnostic methods, we introduce DABS: a Domain-Agnostic Benchmark for Self-supervised learning. To perform well on DABS, an algorithm is evaluated on seven diverse domains: natural images, multichannel sensor data, English text, speech recordings, multilingual text, chest x-rays, and images with text descriptions. Each domain contains an unlabeled dataset for pretraining; the model is then is scored based on its downstream performance on a set of labeled tasks in the domain. We also present e-Mix and ShED: two baseline domain-agnostic algorithms; their relatively modest performance demonstrates that significant progress is needed before self-supervised learning is an out-of-the-box solution for arbitrary domains. Code for benchmark datasets and baseline algorithms is available at https://github.com/alextamkin/dabs.