 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-of-the-Art Arabic Language Modeling with Sparse MoE Fine-Tuning and Chain-of-Thought Distillation
Apr 07, 2026This paper introduces Arabic-DeepSeek-R1, an application-driven open-source Arabic LLM that leverages a sparse MoE backbone to address the digital equity gap for under-represented languages, and establishes a new SOTA across the entire Open Arabic LLM Leaderboard (OALL). Our four-phase CoT distillation scheme integrates Arabic-specific linguistic verification and regional ethical norms into a 372M-token, contamination-controlled 80/20 Arabic-English training mixture. Arabic-DeepSeek-R1 achieves the highest average score across the seven-benchmark OALL suite while establishing SOTA or near-SOTA, including dominant results on grammar-focused MadinahQA (surpassing both GPT-5.1 and the OALL leader by substantial margins), safety-oriented AraTrust, multi-ability AlGhafa, and retrieval-augmented ALRAGE. Our results indicate that the combination of sparse MoE architecture, culturally-informed CoT distillation with explicit Arabic linguistic checks, and strategic bilingual data curation enables an open-source adapted model to systematically outperform the proprietary frontier system GPT-5.1 on the majority of benchmarks evaluating comprehensive language-specific tasks: the first such demonstration for Arabic LLMs. These findings indicate that much of Arabic's performance deficit in current LLM ecosystems stems from under-specialization rather than architectural limitations, and that parameter-efficient adaptation of open reasoning models can yield breakthrough SOTA performance without industrial-scale pretraining costs. Arabic-DeepSeek-R1 establishes a validated and replicable framework for sovereign and domain-specific language technologies, demonstrating that strategic, culturally-grounded adaptation of sparse MoE backbones offers a viable and cost-effective pathway to achieving record-breaking performance across standardized benchmarks for low-resource languages.
Application-Driven Pedagogical Knowledge Optimization of Open-Source LLMs via Reinforcement Learning and Supervised Fine-Tuning
Apr 07, 2026We present an innovative multi-stage optimization strategy combining reinforcement learning (RL) and supervised fine-tuning (SFT) to enhance the pedagogical knowledge of large language models (LLMs), as illustrated by EduQwen 32B-RL1, EduQwen 32B-SFT, and an optional third-stage model EduQwen 32B-SFT-RL2: (1) RL optimization that implements progressive difficulty training, focuses on challenging examples, and employs extended reasoning rollouts; (2) a subsequent SFT phase that leverages the RL-trained model to synthesize high-quality training data with difficulty-weighted sampling; and (3) an optional second round of RL optimization. EduQwen 32B-RL1, EduQwen 32B-SFT, and EduQwen 32B-SFT-RL2 are an application-driven family of open-source pedagogical LLMs built on a dense Qwen3-32B backbone. These models remarkably achieve high enough accuracy on the Cross-Domain Pedagogical Knowledge (CDPK) Benchmark to establish new state-of-the-art (SOTA) results across the interactive Pedagogy Benchmark Leaderboard and surpass significantly larger proprietary systems such as the previous benchmark leader Gemini-3 Pro. These dense 32-billion-parameter models demonstrate that domain-specialized optimization can transform mid-sized open-source LLMs into true pedagogical domain experts that outperform much larger general-purpose systems, while preserving the transparency, customizability, and cost-efficiency required for responsible educational AI deployment.
OpenMedLM: Prompt engineering can out-perform fine-tuning in medical question-answering with open-source large language models
Feb 29, 2024LLMs have become increasingly capable at accomplishing a range of specialized-tasks and can be utilized to expand equitable access to medical knowledge. Most medical LLMs have involved extensive fine-tuning, leveraging specialized medical data and significant, thus costly, amounts of computational power. Many of the top performing LLMs are proprietary and their access is limited to very few research groups. However, open-source (OS) models represent a key area of growth for medical LLMs due to significant improvements in performance and an inherent ability to provide the transparency and compliance required in healthcare. We present OpenMedLM, a prompting platform which delivers state-of-the-art (SOTA) performance for OS LLMs on medical benchmarks. We evaluated a range of OS foundation LLMs (7B-70B) on four medical benchmarks (MedQA, MedMCQA, PubMedQA, MMLU medical-subset). We employed a series of prompting strategies, including zero-shot, few-shot, chain-of-thought (random selection and kNN selection), and ensemble/self-consistency voting. We found that OpenMedLM delivers OS SOTA results on three common medical LLM benchmarks, surpassing the previous best performing OS models that leveraged computationally costly extensive fine-tuning. The model delivers a 72.6% accuracy on the MedQA benchmark, outperforming the previous SOTA by 2.4%, and achieves 81.7% accuracy on the MMLU medical-subset, establishing itself as the first OS LLM to surpass 80% accuracy on this benchmark. Our results highlight medical-specific emergent properties in OS LLMs which have not yet been documented to date elsewhere, and showcase the benefits of further leveraging prompt engineering to improve the performance of accessible LLMs for medical applications.
Perspective: Energy Landscapes for Machine Learning
Mar 23, 2017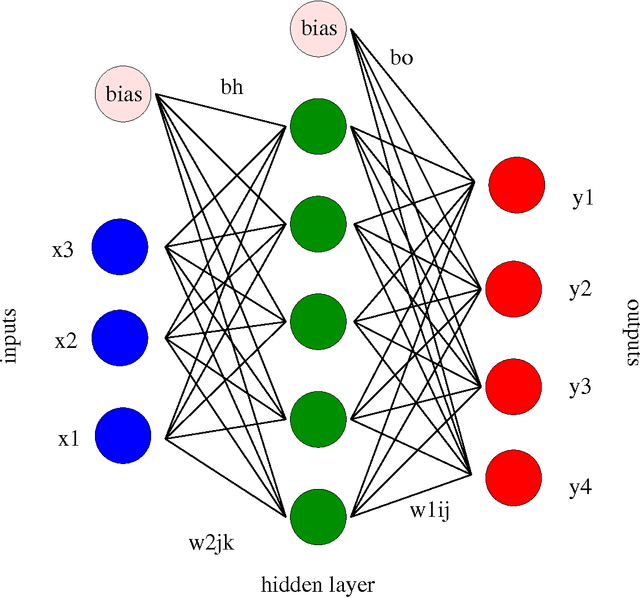
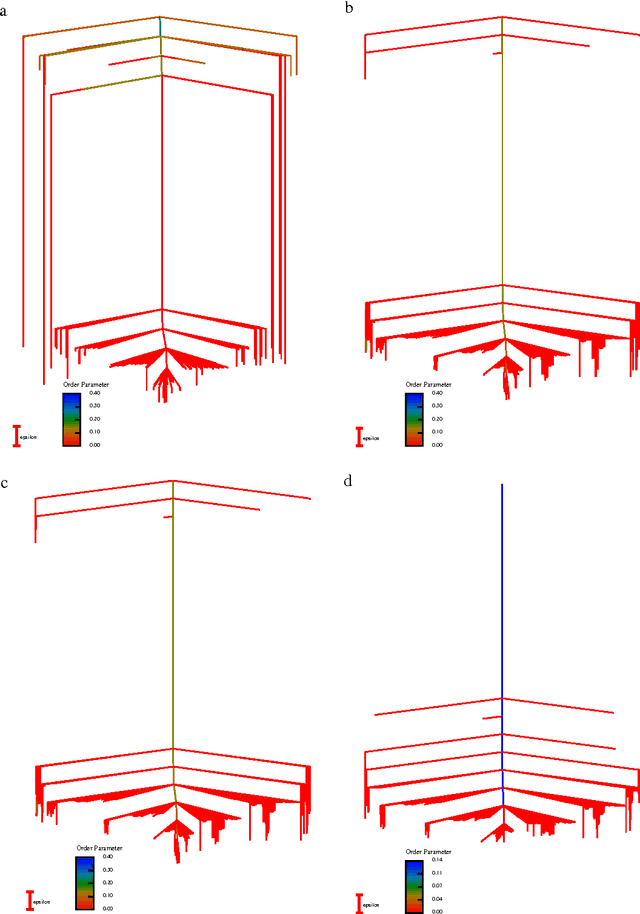
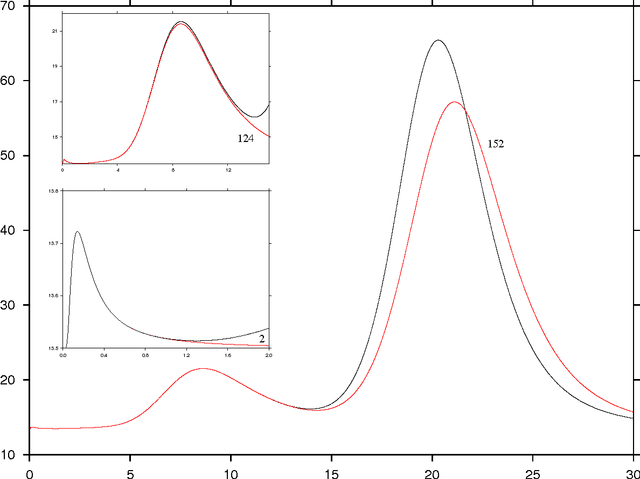

Machine learning techniques are being increasingly used as flexible non-linear fitting and prediction tools in the physical sciences. Fitting functions that exhibit multiple solutions as local minima can be analysed in terms of the corresponding machine learning landscape. Methods to explore and visualise molecular potential energy landscapes can be applied to these machine learning landscapes to gain new insight into the solution space involved in training and the nature of the corresponding predictions. In particular, we can define quantities analogous to molecular structure, thermodynamics, and kinetics, and relate these emergent properties to the structure of the underlying landscape. This Perspective aims to describe these analogies with examples from recent applications, and suggest avenues for new interdisciplinary research.