 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Hands as Probes for Interactive Object Understanding
Dec 16, 2021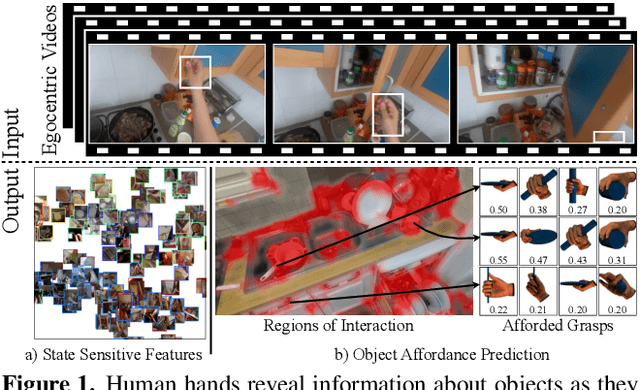
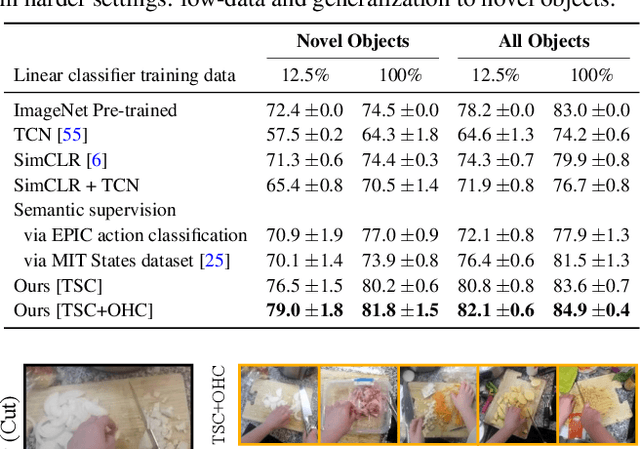
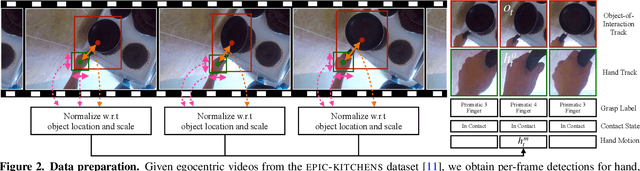
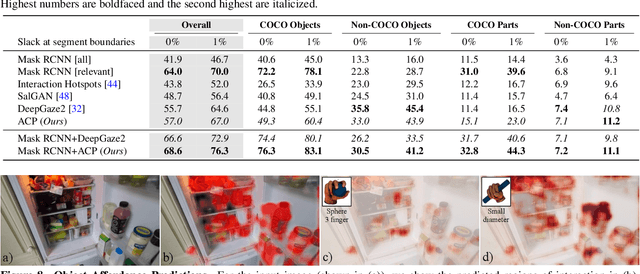
Interactive object understanding, or what we can do to objects and how is a long-standing goal of computer vision. In this paper, we tackle this problem through observation of human hands in in-the-wild egocentric videos. We demonstrate that observation of what human hands interact with and how can provide both the relevant data and the necessary supervision. Attending to hands, readily localizes and stabilizes active objects for learning and reveals places where interactions with objects occur. Analyzing the hands shows what we can do to objects and how. We apply these basic principles on the EPIC-KITCHENS dataset, and successfully learn state-sensitive features, and object affordances (regions of interaction and afforded grasps), purely by observing hands in egocentric videos.
Fixed-point Quantization of Convolutional Neural Networks for Quantized Inference on Embedded Platforms
Feb 03, 2021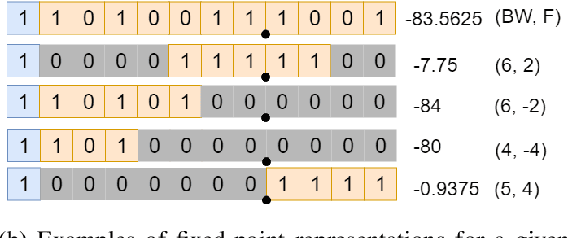
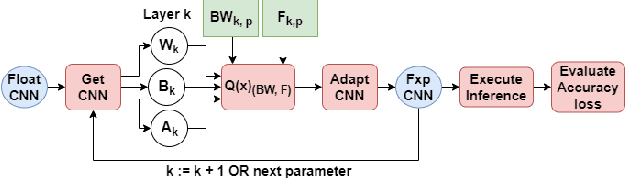

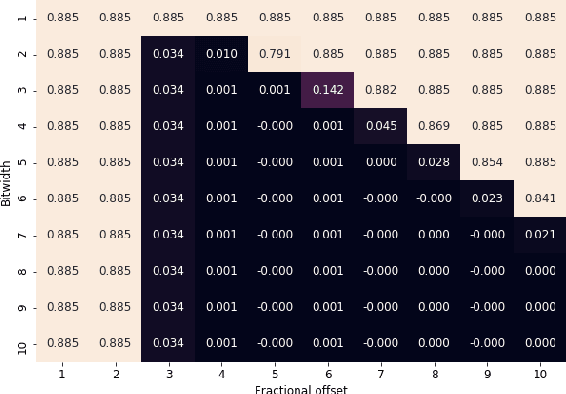
Convolutional Neural Networks (CNNs) have proven to be a powerful state-of-the-art method for image classification tasks. One drawback however is the high computational complexity and high memory consumption of CNNs which makes them unfeasible for execution on embedded platforms which are constrained on physical resources needed to support CNNs. Quantization has often been used to efficiently optimize CNNs for memory and computational complexity at the cost of a loss of prediction accuracy. We therefore propose a method to optimally quantize the weights, biases and activations of each layer of a pre-trained CNN while controlling the loss in inference accuracy to enable quantized inference. We quantize the 32-bit floating-point precision parameters to low bitwidth fixed-point representations thereby finding optimal bitwidths and fractional offsets for parameters of each layer of a given CNN. We quantize parameters of a CNN post-training without re-training it. Our method is designed to quantize parameters of a CNN taking into account how other parameters are quantized because ignoring quantization errors due to other quantized parameters leads to a low precision CNN with accuracy losses of up to 50% which is far beyond what is acceptable. Our final method therefore gives a low precision CNN with accuracy losses of less than 1%. As compared to a method used by commercial tools that quantize all parameters to 8-bits, our approach provides quantized CNN with averages of 53% lower memory consumption and 77.5% lower cost of executing multiplications for the two CNNs trained on the four datasets that we tested our work on. We find that layer-wise quantization of parameters significantly helps in this process.
Neural Shape Parsers for Constructive Solid Geometry
Dec 22, 2019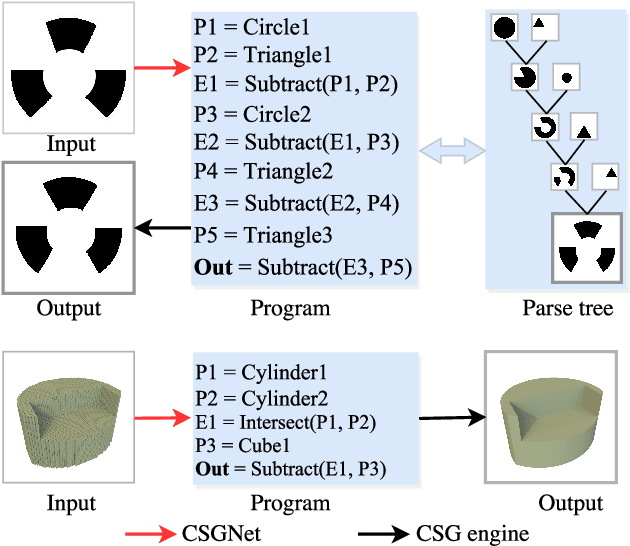
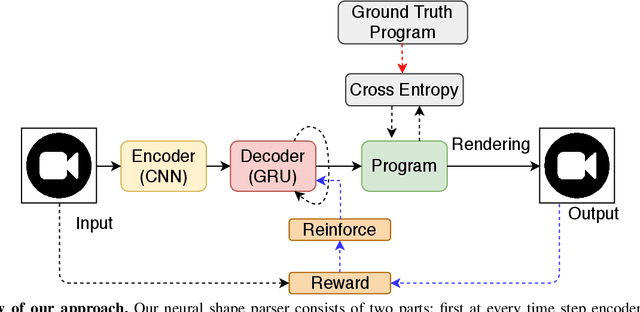
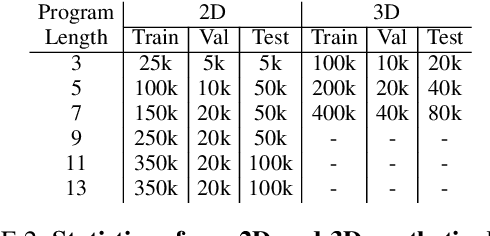
Constructive Solid Geometry (CSG) is a geometric modeling technique that defines complex shapes by recursively applying boolean operations on primitives such as spheres and cylinders. We present CSGNe, a deep network architecture that takes as input a 2D or 3D shape and outputs a CSG program that models it. Parsing shapes into CSG programs is desirable as it yields a compact and interpretable generative model. However, the task is challenging since the space of primitives and their combinations can be prohibitively large. CSGNe uses a convolutional encoder and recurrent decoder based on deep networks to map shapes to modeling instructions in a feed-forward manner and is significantly faster than bottom-up approaches. We investigate two architectures for this task --- a vanilla encoder (CNN) - decoder (RNN) and another architecture that augments the encoder with an explicit memory module based on the program execution stack. The stack augmentation improves the reconstruction quality of the generated shape and learning efficiency. Our approach is also more effective as a shape primitive detector compared to a state-of-the-art object detector. Finally, we demonstrate CSGNet can be trained on novel datasets without program annotations through policy gradient techniques.
CSGNet: Neural Shape Parser for Constructive Solid Geometry
Mar 31, 2018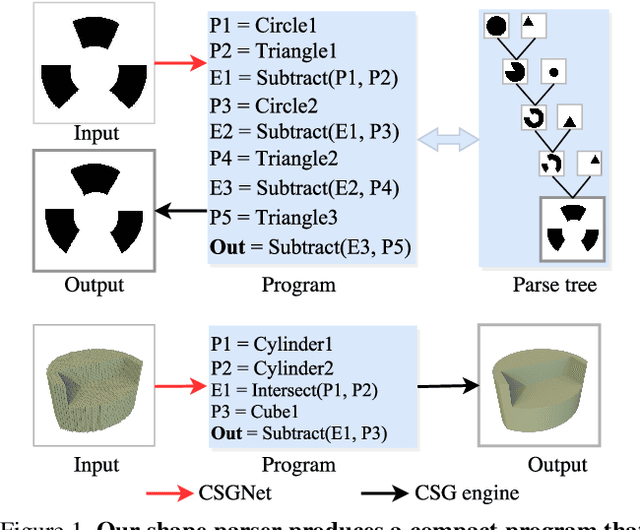
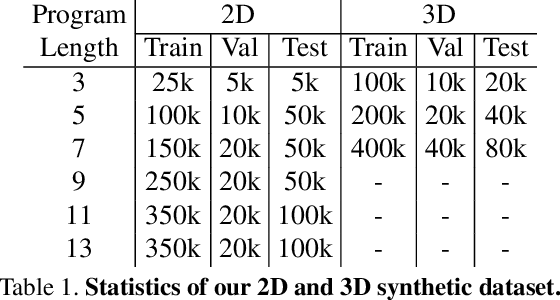
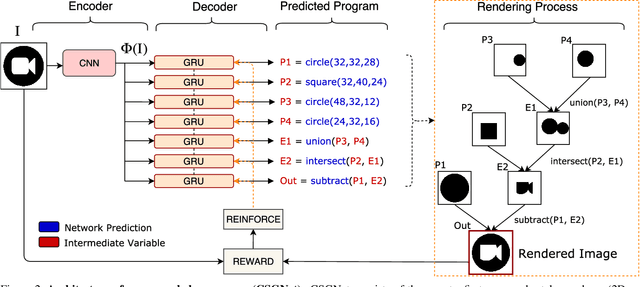
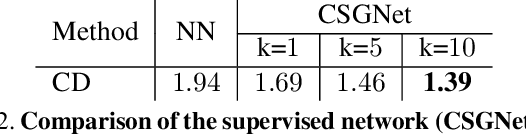
We present a neural architecture that takes as input a 2D or 3D shape and outputs a program that generates the shape. The instructions in our program are based on constructive solid geometry principles, i.e., a set of boolean operations on shape primitives defined recursively. Bottom-up techniques for this shape parsing task rely on primitive detection and are inherently slow since the search space over possible primitive combinations is large. In contrast, our model uses a recurrent neural network that parses the input shape in a top-down manner, which is significantly faster and yields a compact and easy-to-interpret sequence of modeling instructions. Our model is also more effective as a shape detector compared to existing state-of-the-art detection techniques. We finally demonstrate that our network can be trained on novel datasets without ground-truth program annotations through policy gradient techniques.