 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-point Quantization of Convolutional Neural Networks for Quantized Inference on Embedded Platforms
Feb 03, 2021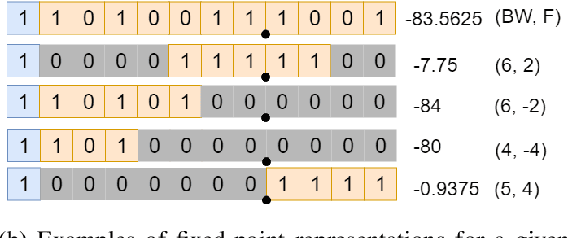
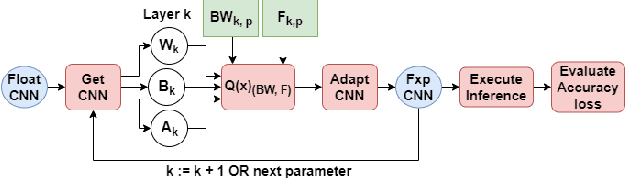

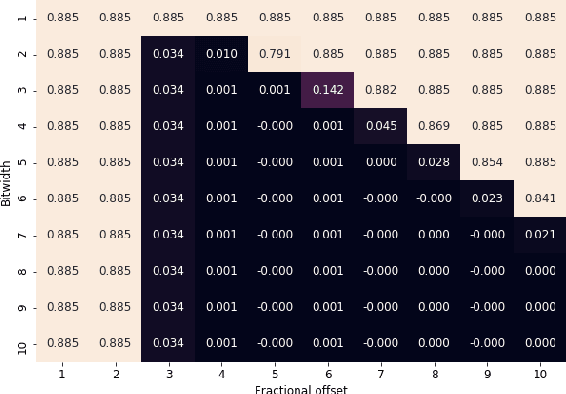
Convolutional Neural Networks (CNNs) have proven to be a powerful state-of-the-art method for image classification tasks. One drawback however is the high computational complexity and high memory consumption of CNNs which makes them unfeasible for execution on embedded platforms which are constrained on physical resources needed to support CNNs. Quantization has often been used to efficiently optimize CNNs for memory and computational complexity at the cost of a loss of prediction accuracy. We therefore propose a method to optimally quantize the weights, biases and activations of each layer of a pre-trained CNN while controlling the loss in inference accuracy to enable quantized inference. We quantize the 32-bit floating-point precision parameters to low bitwidth fixed-point representations thereby finding optimal bitwidths and fractional offsets for parameters of each layer of a given CNN. We quantize parameters of a CNN post-training without re-training it. Our method is designed to quantize parameters of a CNN taking into account how other parameters are quantized because ignoring quantization errors due to other quantized parameters leads to a low precision CNN with accuracy losses of up to 50% which is far beyond what is acceptable. Our final method therefore gives a low precision CNN with accuracy losses of less than 1%. As compared to a method used by commercial tools that quantize all parameters to 8-bits, our approach provides quantized CNN with averages of 53% lower memory consumption and 77.5% lower cost of executing multiplications for the two CNNs trained on the four datasets that we tested our work on. We find that layer-wise quantization of parameters significantly helps in this process.