 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
SOL-ExecBench: Speed-of-Light Benchmarking for Real-World GPU Kernels Against Hardware Limits
Mar 19, 2026As agentic AI systems become increasingly capable of generating and optimizing GPU kernels, progress is constrained by benchmarks that reward speedup over software baselines rather than proximity to hardware-efficient execution. We present SOL-ExecBench, a benchmark of 235 CUDA kernel optimization problems extracted from 124 production and emerging AI models spanning language, diffusion, vision, audio, video, and hybrid architectures, targeting NVIDIA Blackwell GPUs. The benchmark covers forward and backward workloads across BF16, FP8, and NVFP4, including kernels whose best performance is expected to rely on Blackwell-specific capabilities. Unlike prior benchmarks that evaluate kernels primarily relative to software implementations, SOL-ExecBench measures performance against analytically derived Speed-of-Light (SOL) bounds computed by SOLAR, our pipeline for deriving hardware-grounded SOL bounds, yielding a fixed target for hardware-efficient optimization. We report a SOL Score that quantifies how much of the gap between a release-defined scoring baseline and the hardware SOL bound a candidate kernel closes. To support robust evaluation of agentic optimizers, we additionally provide a sandboxed harness with GPU clock locking, L2 cache clearing, isolated subprocess execution, and static analysis based checks against common reward-hacking strategies. SOL-ExecBench reframes GPU kernel benchmarking from beating a mutable software baseline to closing the remaining gap to hardware Speed-of-Light.
KernelBlaster: Continual Cross-Task CUDA Optimization via Memory-Augmented In-Context Reinforcement Learning
Feb 15, 2026Optimizing CUDA code across multiple generations of GPU architectures is challenging, as achieving peak performance requires an extensive exploration of an increasingly complex, hardware-specific optimization space. Traditional compilers are constrained by fixed heuristics, whereas finetuning Large Language Models (LLMs) can be expensive. However, agentic workflows for CUDA code optimization have limited ability to aggregate knowledge from prior exploration, leading to biased sampling and suboptimal solutions. We propose KernelBlaster, a Memory-Augmented In-context Reinforcement Learning (MAIC-RL) framework designed to improve CUDA optimization search capabilities of LLM-based GPU coding agents. KernelBlaster enables agents to learn from experience and make systematically informed decisions on future tasks by accumulating knowledge into a retrievable Persistent CUDA Knowledge Base. We propose a novel profile-guided, textual-gradient-based agentic flow for CUDA generation and optimization to achieve high performance across generations of GPU architectures. KernelBlaster guides LLM agents to systematically explore high-potential optimization strategies beyond naive rewrites. Compared to the PyTorch baseline, our method achieves geometric mean speedups of 1.43x, 2.50x, and 1.50x on KernelBench Levels 1, 2, and 3, respectively. We release KernelBlaster as an open-source agentic framework, accompanied by a test harness, verification components, and a reproducible evaluation pipeline.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Wobble control of a pendulum actuated spherical robot
Jan 16, 2023



Spherical robots can conduct surveillance in hostile, cluttered environments without being damaged, as their protective shell can safely house sensors such as cameras. However, lateral oscillations, also known as wobble, occur when these sphere-shaped robots operate at low speeds, leading to shaky camera feedback. These oscillations in a pendulum-actuated spherical robot are caused by the coupling between the forward and steering motions due to nonholonomic constraints. Designing a controller to limit wobbling in these robots is challenging due to their underactuated nature. We propose a model-based controller to navigate a pendulum-actuated spherical robot using wobble-free turning maneuvers consisting of circular arcs and straight lines. The model is developed using Lagrange-D'Alembert equations and accounts for the coupled forward and steering motions. The model is further analyzed to derive expressions for radius of curvature, precession rate, wobble amplitude, and wobble frequency during circular motions. Finally, we design an input-output feedback linearization-based controller to control the robot's heading direction and wobble. Overall, the proposed controller enables a teleoperator to command a specific forward velocity and pendulum angle as per the desired turning radius while limiting the robot's lateral oscillations to enhance the quality of camera feedback.
Pendulum Actuated Spherical Robot: Dynamic Modeling & Analysis for Wobble & Precession
Jan 14, 2023



A spherical robot has many practical advantages as the entire electronics are protected within a hull and can be carried easily by any Unmanned Aerial Vehicle (UAV). However, its use is limited due to finding mounts for sensors. Pendulum actuated spherical robot provides space for mounting sensors at the yoke. We study the non-linear dynamics of a pendulum-actuated spherical robot to analyze the dynamics of internal assembly (yoke) for mounting sensors. For such robots, we provide a coupled dynamic model that takes care of the relationship between forward and sideways motion. We further demonstrate the effects of wobbling and precession captured by our model when the bot is controlled to execute a turning maneuver while moving with a moderate forward velocity, a practical situation encountered by spherical robots moving in an indoor setting. A simulation setup based on the developed model provides visualization of the spherical robot motion.
Human Hands as Probes for Interactive Object Understanding
Dec 16, 2021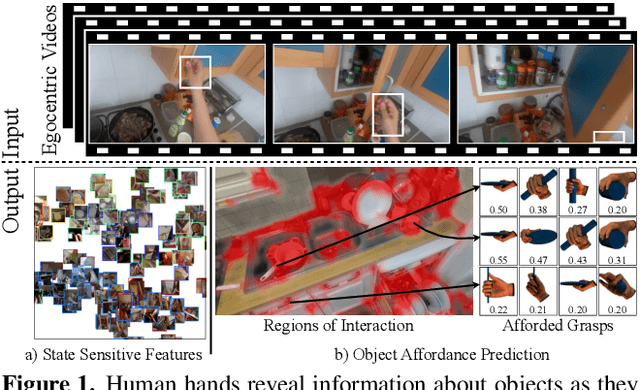
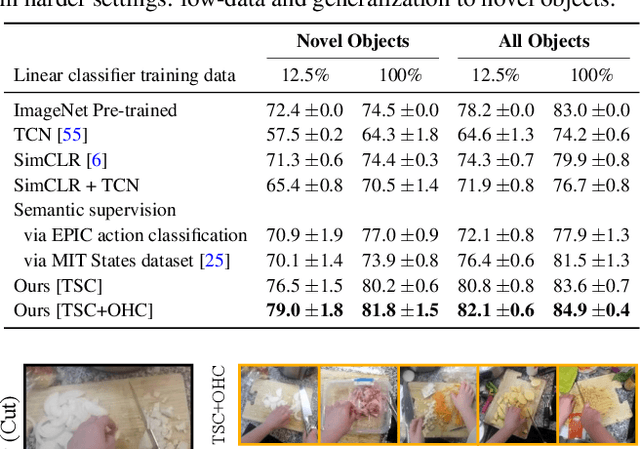
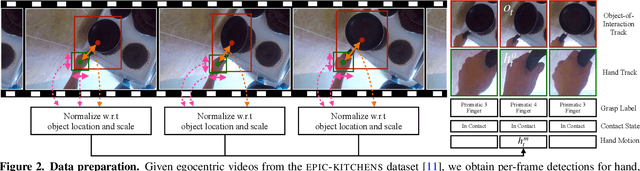
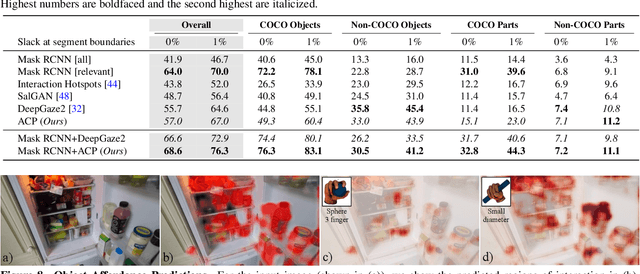
Interactive object understanding, or what we can do to objects and how is a long-standing goal of computer vision. In this paper, we tackle this problem through observation of human hands in in-the-wild egocentric videos. We demonstrate that observation of what human hands interact with and how can provide both the relevant data and the necessary supervision. Attending to hands, readily localizes and stabilizes active objects for learning and reveals places where interactions with objects occur. Analyzing the hands shows what we can do to objects and how. We apply these basic principles on the EPIC-KITCHENS dataset, and successfully learn state-sensitive features, and object affordances (regions of interaction and afforded grasps), purely by observing hands in egocentric videos.
Learned Visual Navigation for Under-Canopy Agricultural Robots
Jul 06, 2021
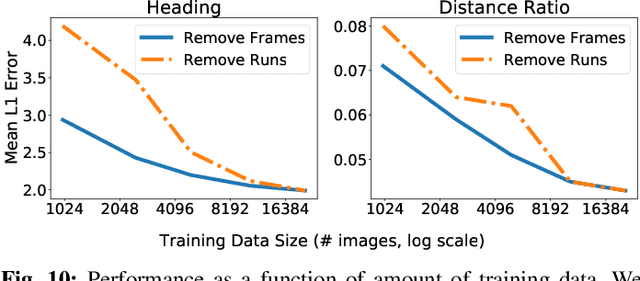
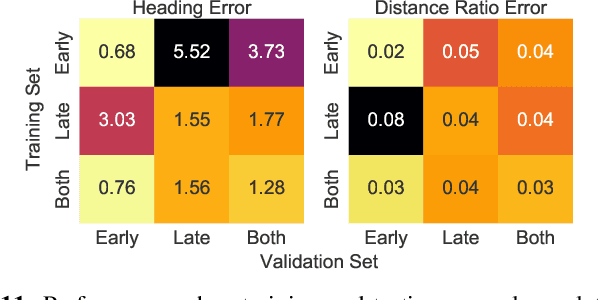

We describe a system for visually guided autonomous navigation of under-canopy farm robots. Low-cost under-canopy robots can drive between crop rows under the plant canopy and accomplish tasks that are infeasible for over-the-canopy drones or larger agricultural equipment. However, autonomously navigating them under the canopy presents a number of challenges: unreliable GPS and LiDAR, high cost of sensing, challenging farm terrain, clutter due to leaves and weeds, and large variability in appearance over the season and across crop types. We address these challenges by building a modular system that leverages machine learning for robust and generalizable perception from monocular RGB images from low-cost cameras, and model predictive control for accurate control in challenging terrain. Our system, CropFollow, is able to autonomously drive 485 meters per intervention on average, outperforming a state-of-the-art LiDAR based system (286 meters per intervention) in extensive field testing spanning over 25 km.