 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Principle Solution for Enroll-Test Mismatch in Speaker Recognition
Dec 23, 2020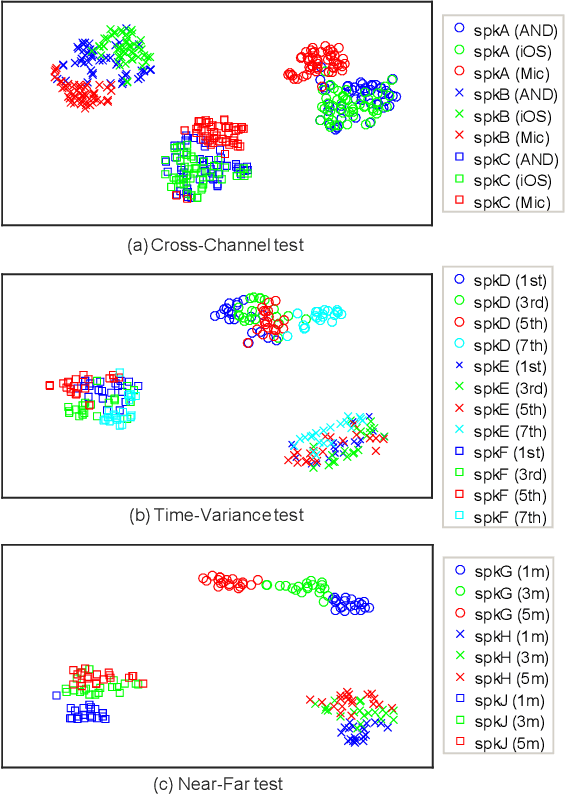
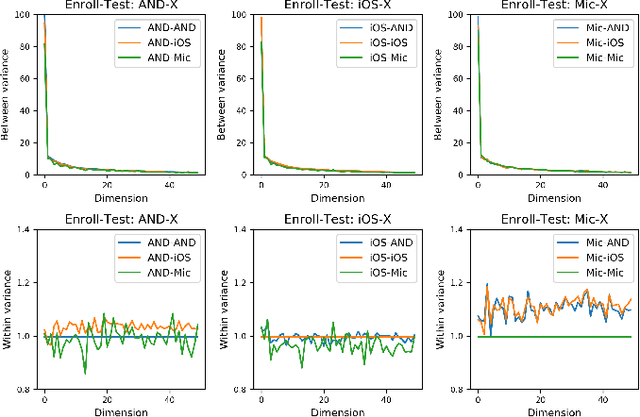
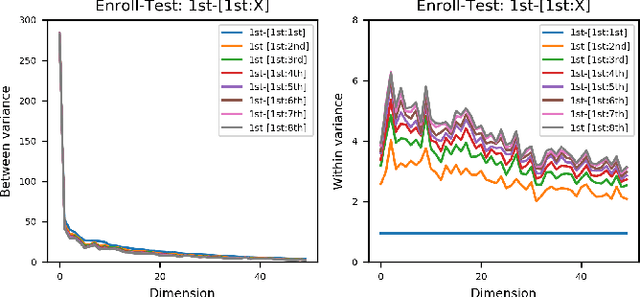
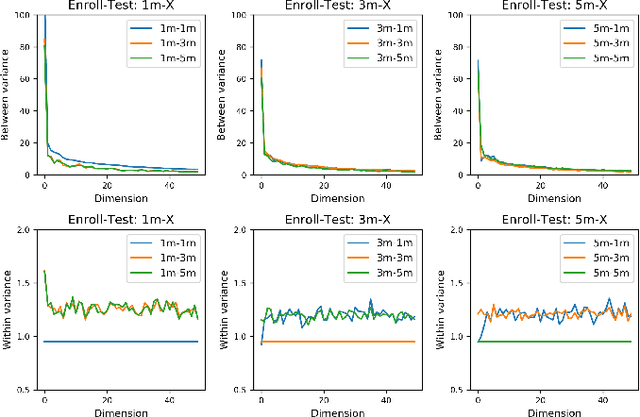
Mismatch between enrollment and test conditions causes serious performance degradation on speaker recognition systems. This paper presents a statistics decomposition (SD) approach to solve this problem. This approach is based on the normalized likelihood (NL) scoring framework, and is theoretically optimal if the statistics on both the enrollment and test conditions are accurate. A comprehensive experimental study was conducted on three datasets with different types of mismatch: (1) physical channel mismatch, (2) speaking style mismatch, (3) near-far recording mismatch. The results demonstrated that the proposed SD approach is highly effective, and outperforms the ad-hoc multi-condition training approach that is commonly adopted but not optimal in theory.
The HUAWEI Speaker Diarisation System for the VoxCeleb Speaker Diarisation Challenge
Oct 23, 2020
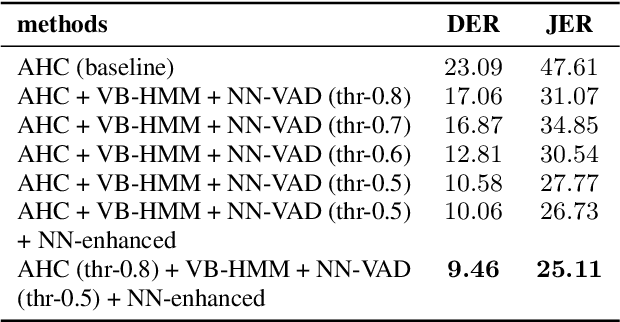


This paper describes system setup of our submission to speaker diarisation track (Track 4) of VoxCeleb Speaker Recognition Challenge 2020. Our diarisation system consists of a well-trained neural network based speech enhancement model as pre-processing front-end of input speech signals. We replace conventional energy-based voice activity detection (VAD) with a neural network based VAD. The neural network based VAD provides more accurate annotation of speech segments containing only background music, noise, and other interference, which is crucial to diarisation performance. We apply agglomerative hierarchical clustering (AHC) of x-vectors and variational Bayesian hidden Markov model (VB-HMM) based iterative clustering for speaker clustering. Experimental results demonstrate that our proposed system achieves substantial improvements over the baseline system, yielding diarisation error rate (DER) of 10.45%, and Jacard error rate (JER) of 22.46% on the evaluation set.
Decision Making Based on Cohort Scores for Speaker Verification
Sep 27, 2016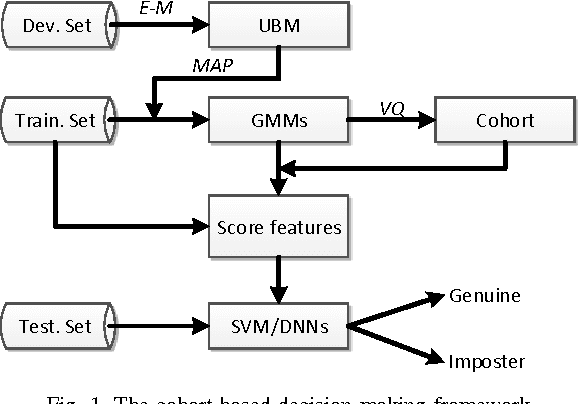
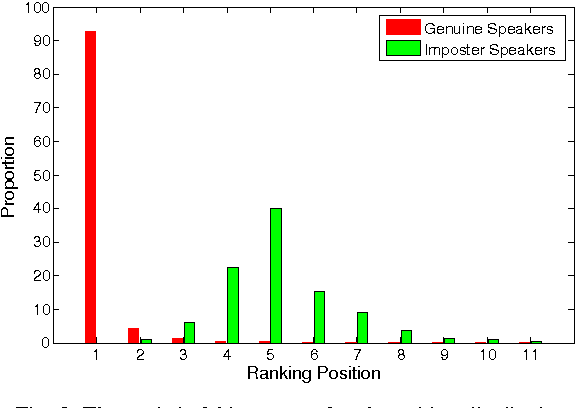
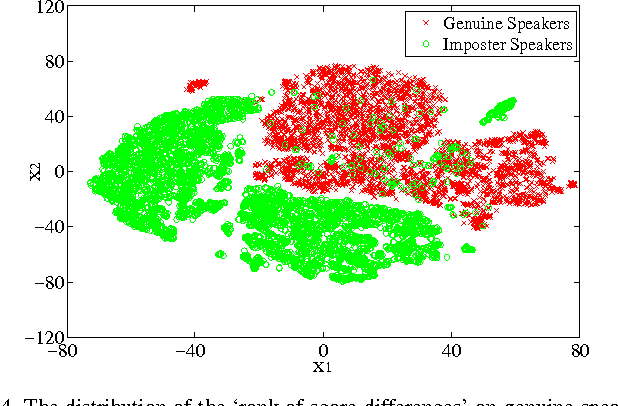
Decision making is an important component in a speaker verification system. For the conventional GMM-UBM architecture, the decision is usually conducted based on the log likelihood ratio of the test utterance against the GMM of the claimed speaker and the UBM. This single-score decision is simple but tends to be sensitive to the complex variations in speech signals (e.g. text content, channel, speaking style, etc.). In this paper, we propose a decision making approach based on multiple scores derived from a set of cohort GMMs (cohort scores). Importantly, these cohort scores are not simply averaged as in conventional cohort methods; instead, we employ a powerful discriminative model as the decision maker. Experimental results show that the proposed method delivers substantial performance improvement over the baseline system, especially when a deep neural network (DNN) is used as the decision maker, and the DNN input involves some statistical features derived from the cohort scores.