 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Principle Solution for Enroll-Test Mismatch in Speaker Recognition
Paper and Code
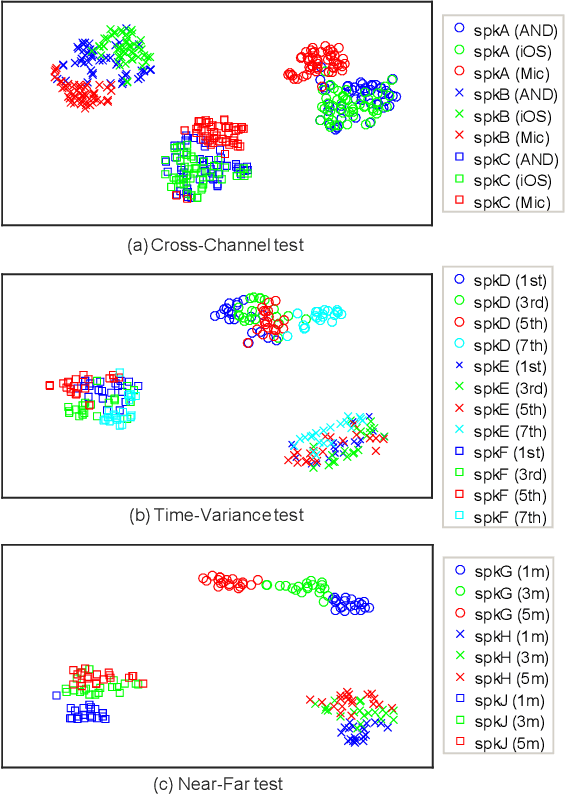
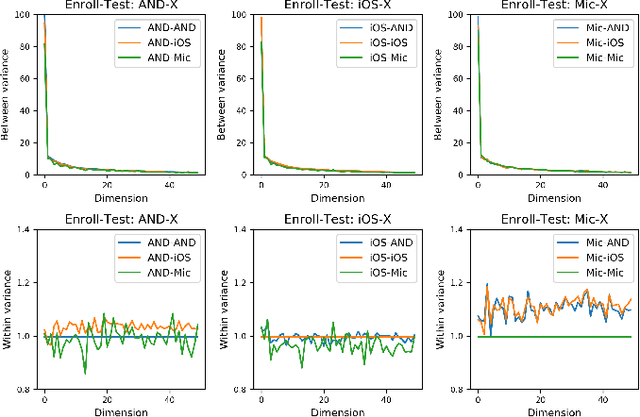
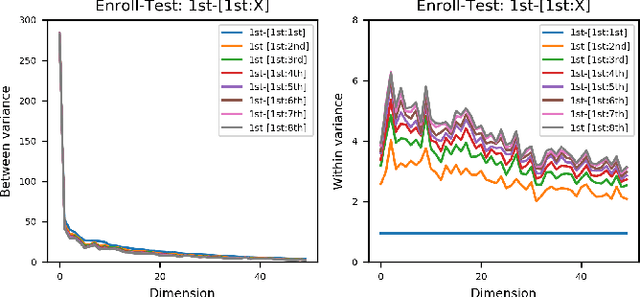
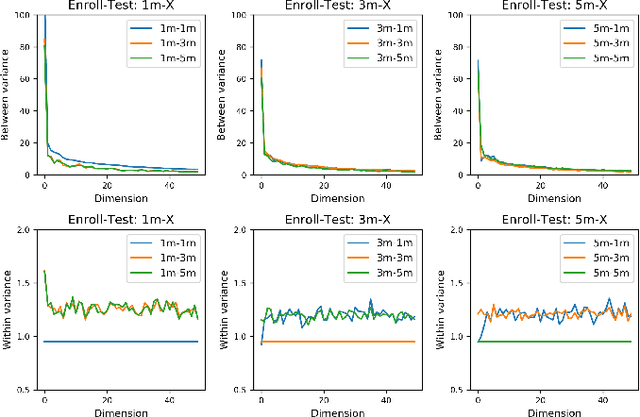
Mismatch between enrollment and test conditions causes serious performance degradation on speaker recognition systems. This paper presents a statistics decomposition (SD) approach to solve this problem. This approach is based on the normalized likelihood (NL) scoring framework, and is theoretically optimal if the statistics on both the enrollment and test conditions are accurate. A comprehensive experimental study was conducted on three datasets with different types of mismatch: (1) physical channel mismatch, (2) speaking style mismatch, (3) near-far recording mismatch. The results demonstrated that the proposed SD approach is highly effective, and outperforms the ad-hoc multi-condition training approach that is commonly adopted but not optimal in theory.