 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Private Tests for Simple and MLR Hypotheses
Jan 29, 2026We develop a near-optimal testing procedure under the framework of Gaussian differential privacy for simple as well as one- and two-sided tests under monotone likelihood ratio conditions. Our mechanism is based on a private mean estimator with data-driven clamping bounds, whose population risk matches the private minimax rate up to logarithmic factors. Using this estimator, we construct private test statistics that achieve the same asymptotic relative efficiency as the non-private, most powerful tests while maintaining conservative type I error control. In addition to our theoretical results, our numerical experiments show that our private tests outperform competing DP methods and offer comparable power to the non-private most powerful tests, even at moderately small sample sizes and privacy loss budgets.
Optimal Survey Design for Private Mean Estimation
Jan 30, 2025This work identifies the first privacy-aware stratified sampling scheme that minimizes the variance for general private mean estimation under the Laplace, Discrete Laplace (DLap) and Truncated-Uniform-Laplace (TuLap) mechanisms within the framework of differential privacy (DP). We view stratified sampling as a subsampling operation, which amplifies the privacy guarantee; however, to have the same final privacy guarantee for each group, different nominal privacy budgets need to be used depending on the subsampling rate. Ignoring the effect of DP, traditional stratified sampling strategies risk significant variance inflation. We phrase our optimal survey design as an optimization problem, where we determine the optimal subsampling sizes for each group with the goal of minimizing the variance of the resulting estimator. We establish strong convexity of the variance objective, propose an efficient algorithm to identify the integer-optimal design, and offer insights on the structure of the optimal design.
On The Global Convergence Of Online RLHF With Neural Parametrization
Oct 21, 2024The importance of Reinforcement Learning from Human Feedback (RLHF) in aligning large language models (LLMs) with human values cannot be overstated. RLHF is a three-stage process that includes supervised fine-tuning (SFT), reward learning, and policy learning. Although there are several offline and online approaches to aligning LLMs, they often suffer from distribution shift issues. These issues arise from the inability to accurately capture the distributional interdependence between the reward learning and policy learning stages. Consequently, this has led to various approximated approaches, but the theoretical insights and motivations remain largely limited to tabular settings, which do not hold in practice. This gap between theoretical insights and practical implementations is critical. It is challenging to address this gap as it requires analyzing the performance of AI alignment algorithms in neural network-parameterized settings. Although bi-level formulations have shown promise in addressing distribution shift issues, they suffer from the hyper-gradient problem, and current approaches lack efficient algorithms to solve this. In this work, we tackle these challenges employing the bi-level formulation laid out in Kwon et al. (2024) along with the assumption \emph{Weak Gradient Domination} to demonstrate convergence in an RLHF setup, obtaining a sample complexity of $\epsilon^{-\frac{7}{2}}$ . Our key contributions are twofold: (i) We propose a bi-level formulation for AI alignment in parameterized settings and introduce a first-order approach to solve this problem. (ii) We analyze the theoretical convergence rates of the proposed algorithm and derive state-of-the-art bounds. To the best of our knowledge, this is the first work to establish convergence rate bounds and global optimality for the RLHF framework in neural network-parameterized settings.
Overlapping Batch Confidence Intervals on Statistical Functionals Constructed from Time Series: Application to Quantiles, Optimization, and Estimation
Jul 17, 2023We propose a general purpose confidence interval procedure (CIP) for statistical functionals constructed using data from a stationary time series. The procedures we propose are based on derived distribution-free analogues of the $\chi^2$ and Student's $t$ random variables for the statistical functional context, and hence apply in a wide variety of settings including quantile estimation, gradient estimation, M-estimation, CVAR-estimation, and arrival process rate estimation, apart from more traditional statistical settings. Like the method of subsampling, we use overlapping batches of time series data to estimate the underlying variance parameter; unlike subsampling and the bootstrap, however, we assume that the implied point estimator of the statistical functional obeys a central limit theorem (CLT) to help identify the weak asymptotics (called OB-x limits, x=I,II,III) of batched Studentized statistics. The OB-x limits, certain functionals of the Wiener process parameterized by the size of the batches and the extent of their overlap, form the essential machinery for characterizing dependence, and consequently the correctness of the proposed CIPs. The message from extensive numerical experimentation is that in settings where a functional CLT on the point estimator is in effect, using \emph{large overlapping batches} alongside OB-x critical values yields confidence intervals that are often of significantly higher quality than those obtained from more generic methods like subsampling or the bootstrap. We illustrate using examples from CVaR estimation, ARMA parameter estimation, and NHPP rate estimation; R and MATLAB code for OB-x critical values is available at~\texttt{web.ics.purdue.edu/~pasupath/}.
Retrospective Approximation for Smooth Stochastic Optimization
Mar 07, 2021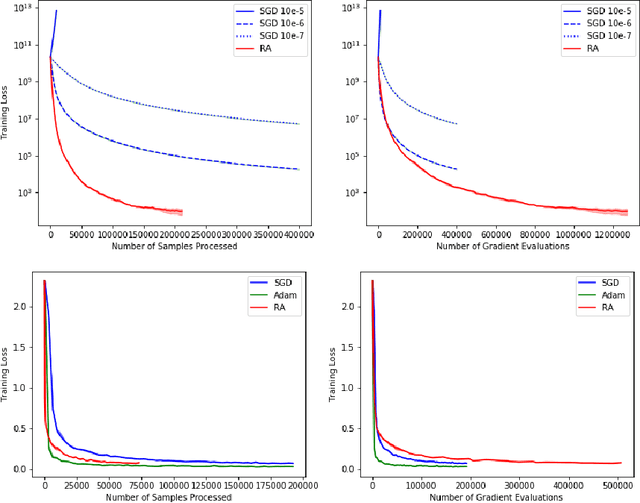
We consider stochastic optimization problems where a smooth (and potentially nonconvex) objective is to be minimized using a stochastic first-order oracle. These type of problems arise in many settings from simulation optimization to deep learning. We present Retrospective Approximation (RA) as a universal sequential sample-average approximation (SAA) paradigm where during each iteration $k$, a sample-path approximation problem is implicitly generated using an adapted sample size $M_k$, and solved (with prior solutions as "warm start") to an adapted error tolerance $\epsilon_k$, using a "deterministic method" such as the line search quasi-Newton method. The principal advantage of RA is that decouples optimization from stochastic approximation, allowing the direct adoption of existing deterministic algorithms without modification, thus mitigating the need to redesign algorithms for the stochastic context. A second advantage is the obvious manner in which RA lends itself to parallelization. We identify conditions on $\{M_k, k \geq 1\}$ and $\{\epsilon_k, k\geq 1\}$ that ensure almost sure convergence and convergence in $L_1$-norm, along with optimal iteration and work complexity rates. We illustrate the performance of RA with line-search quasi-Newton on an ill-conditioned least squares problem, as well as an image classification problem using a deep convolutional neural net.
Adaptive Sequential SAA for Solving Two-stage Stochastic Linear Programs
Dec 07, 2020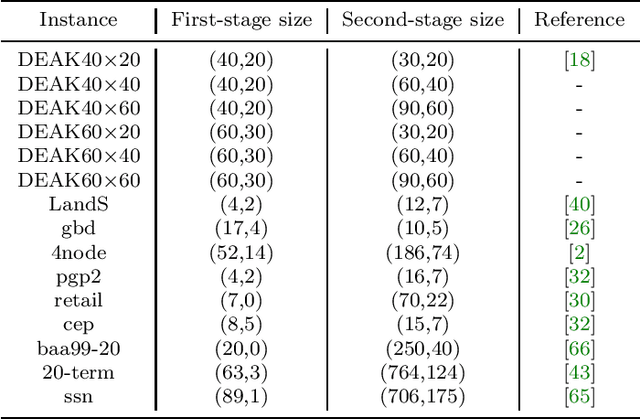
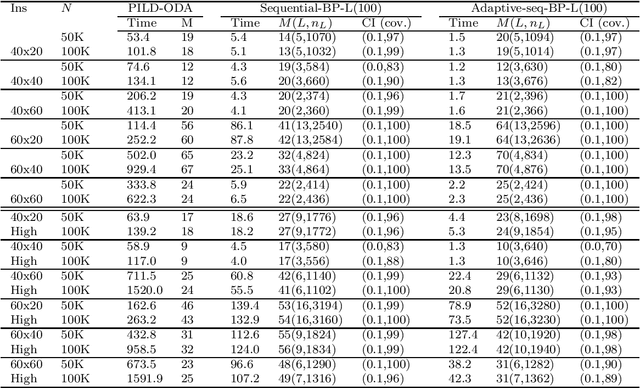

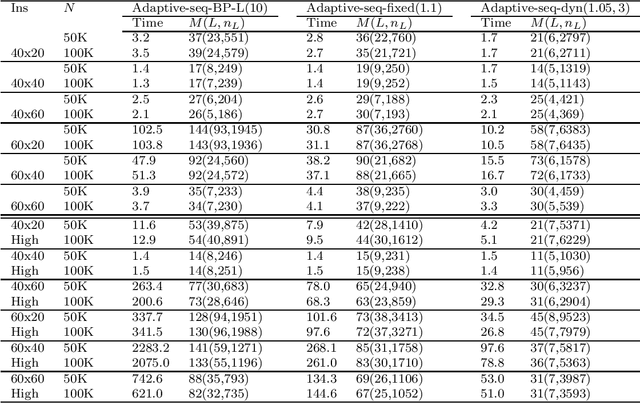
We present adaptive sequential SAA (sample average approximation) algorithms to solve large-scale two-stage stochastic linear programs. The iterative algorithm framework we propose is organized into \emph{outer} and \emph{inner} iterations as follows: during each outer iteration, a sample-path problem is implicitly generated using a sample of observations or ``scenarios," and solved only \emph{imprecisely}, to within a tolerance that is chosen \emph{adaptively}, by balancing the estimated statistical error against solution error. The solutions from prior iterations serve as \emph{warm starts} to aid efficient solution of the (piecewise linear convex) sample-path optimization problems generated on subsequent iterations. The generated scenarios can be independent and identically distributed (iid), or dependent, as in Monte Carlo generation using Latin-hypercube sampling, antithetic variates, or randomized quasi-Monte Carlo. We first characterize the almost-sure convergence (and convergence in mean) of the optimality gap and the distance of the generated stochastic iterates to the true solution set. We then characterize the corresponding iteration complexity and work complexity rates as a function of the sample size schedule, demonstrating that the best achievable work complexity rate is Monte Carlo canonical and analogous to the generic $\mathcal{O}(\epsilon^{-2})$ optimal complexity for non-smooth convex optimization. We report extensive numerical tests that indicate favorable performance, due primarily to the use of a sequential framework with an optimal sample size schedule, and the use of warm starts. The proposed algorithm can be stopped in finite-time to return a solution endowed with a probabilistic guarantee on quality.
Efficient Estimation in the Tails of Gaussian Copulas
Jul 05, 2016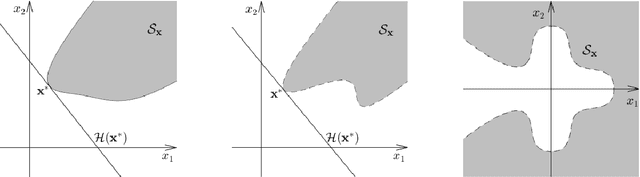
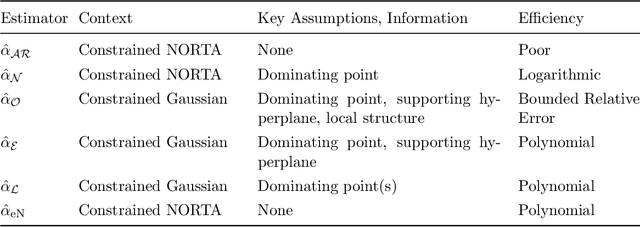
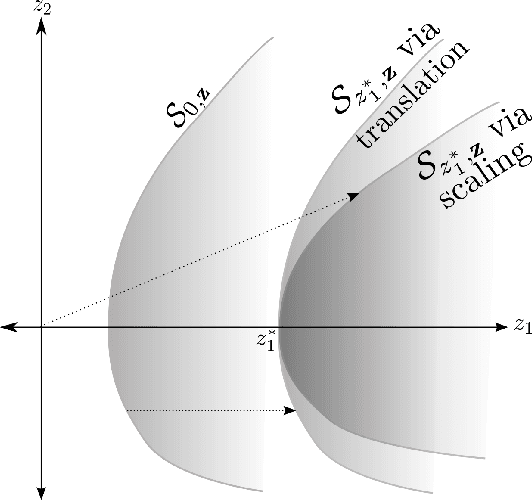
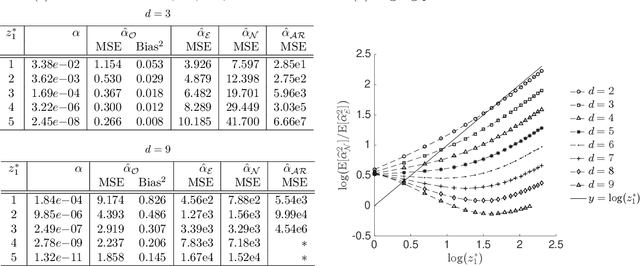
We consider the question of efficient estimation in the tails of Gaussian copulas. Our special focus is estimating expectations over multi-dimensional constrained sets that have a small implied measure under the Gaussian copula. We propose three estimators, all of which rely on a simple idea: identify certain \emph{dominating} point(s) of the feasible set, and appropriately shift and scale an exponential distribution for subsequent use within an importance sampling measure. As we show, the efficiency of such estimators depends crucially on the local structure of the feasible set around the dominating points. The first of our proposed estimators $\estOpt$ is the "full-information" estimator that actively exploits such local structure to achieve bounded relative error in Gaussian settings. The second and third estimators $\estExp$, $\estLap$ are "partial-information" estimators, for use when complete information about the constraint set is not available, they do not exhibit bounded relative error but are shown to achieve polynomial efficiency. We provide sharp asymptotics for all three estimators. For the NORTA setting where no ready information about the dominating points or the feasible set structure is assumed, we construct a multinomial mixture of the partial-information estimator $\estLap$ resulting in a fourth estimator $\estNt$ with polynomial efficiency, and implementable through the ecoNORTA algorithm. Numerical results on various example problems are remarkable, and consistent with theory.