 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrospective Approximation for Smooth Stochastic Optimization
Mar 07, 2021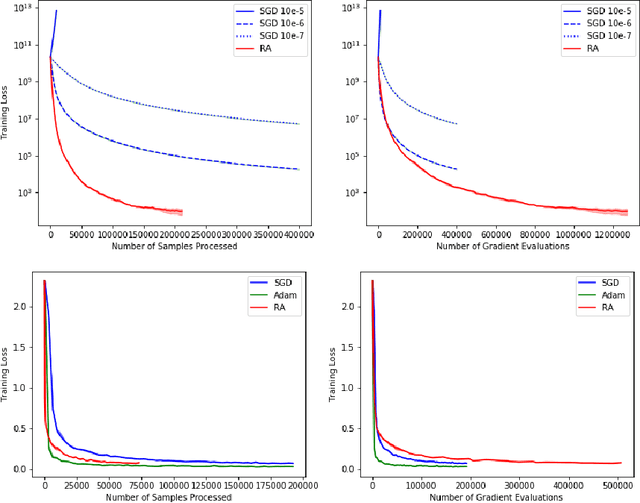
We consider stochastic optimization problems where a smooth (and potentially nonconvex) objective is to be minimized using a stochastic first-order oracle. These type of problems arise in many settings from simulation optimization to deep learning. We present Retrospective Approximation (RA) as a universal sequential sample-average approximation (SAA) paradigm where during each iteration $k$, a sample-path approximation problem is implicitly generated using an adapted sample size $M_k$, and solved (with prior solutions as "warm start") to an adapted error tolerance $\epsilon_k$, using a "deterministic method" such as the line search quasi-Newton method. The principal advantage of RA is that decouples optimization from stochastic approximation, allowing the direct adoption of existing deterministic algorithms without modification, thus mitigating the need to redesign algorithms for the stochastic context. A second advantage is the obvious manner in which RA lends itself to parallelization. We identify conditions on $\{M_k, k \geq 1\}$ and $\{\epsilon_k, k\geq 1\}$ that ensure almost sure convergence and convergence in $L_1$-norm, along with optimal iteration and work complexity rates. We illustrate the performance of RA with line-search quasi-Newton on an ill-conditioned least squares problem, as well as an image classification problem using a deep convolutional neural net.
Towards an Understanding of Residual Networks Using Neural Tangent Hierarchy (NTH)
Jul 07, 2020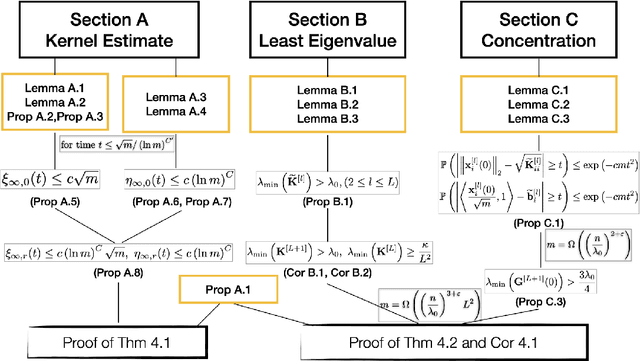
Gradient descent yields zero training loss in polynomial time for deep neural networks despite non-convex nature of the objective function. The behavior of network in the infinite width limit trained by gradient descent can be described by the Neural Tangent Kernel (NTK) introduced in \cite{Jacot2018Neural}. In this paper, we study dynamics of the NTK for finite width Deep Residual Network (ResNet) using the neural tangent hierarchy (NTH) proposed in \cite{Huang2019Dynamics}. For a ResNet with smooth and Lipschitz activation function, we reduce the requirement on the layer width $m$ with respect to the number of training samples $n$ from quartic to cubic. Our analysis suggests strongly that the particular skip-connection structure of ResNet is the main reason for its triumph over fully-connected network.