 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sequential SAA for Solving Two-stage Stochastic Linear Programs
Dec 07, 2020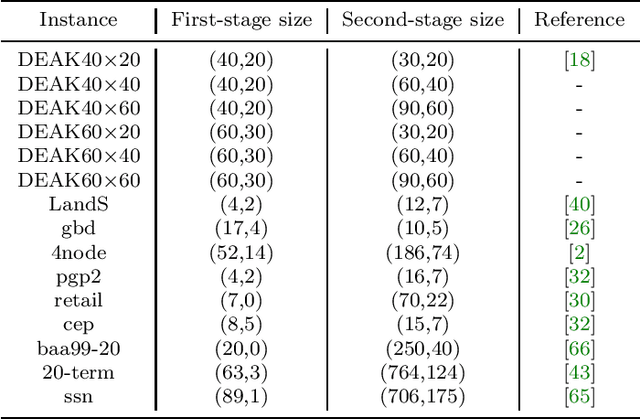
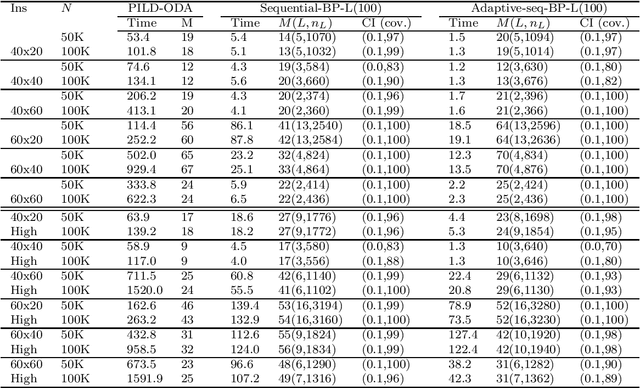

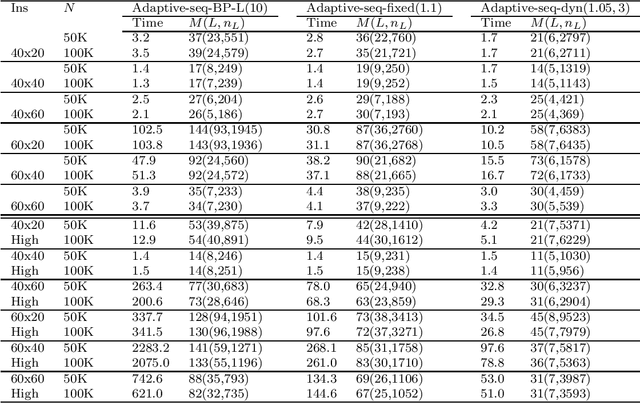
We present adaptive sequential SAA (sample average approximation) algorithms to solve large-scale two-stage stochastic linear programs. The iterative algorithm framework we propose is organized into \emph{outer} and \emph{inner} iterations as follows: during each outer iteration, a sample-path problem is implicitly generated using a sample of observations or ``scenarios," and solved only \emph{imprecisely}, to within a tolerance that is chosen \emph{adaptively}, by balancing the estimated statistical error against solution error. The solutions from prior iterations serve as \emph{warm starts} to aid efficient solution of the (piecewise linear convex) sample-path optimization problems generated on subsequent iterations. The generated scenarios can be independent and identically distributed (iid), or dependent, as in Monte Carlo generation using Latin-hypercube sampling, antithetic variates, or randomized quasi-Monte Carlo. We first characterize the almost-sure convergence (and convergence in mean) of the optimality gap and the distance of the generated stochastic iterates to the true solution set. We then characterize the corresponding iteration complexity and work complexity rates as a function of the sample size schedule, demonstrating that the best achievable work complexity rate is Monte Carlo canonical and analogous to the generic $\mathcal{O}(\epsilon^{-2})$ optimal complexity for non-smooth convex optimization. We report extensive numerical tests that indicate favorable performance, due primarily to the use of a sequential framework with an optimal sample size schedule, and the use of warm starts. The proposed algorithm can be stopped in finite-time to return a solution endowed with a probabilistic guarantee on quality.