 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust The Typical
Feb 04, 2026Current approaches to LLM safety fundamentally rely on a brittle cat-and-mouse game of identifying and blocking known threats via guardrails. We argue for a fresh approach: robust safety comes not from enumerating what is harmful, but from deeply understanding what is safe. We introduce Trust The Typical (T3), a framework that operationalizes this principle by treating safety as an out-of-distribution (OOD) detection problem. T3 learns the distribution of acceptable prompts in a semantic space and flags any significant deviation as a potential threat. Unlike prior methods, it requires no training on harmful examples, yet achieves state-of-the-art performance across 18 benchmarks spanning toxicity, hate speech, jailbreaking, multilingual harms, and over-refusal, reducing false positive rates by up to 40x relative to specialized safety models. A single model trained only on safe English text transfers effectively to diverse domains and over 14 languages without retraining. Finally, we demonstrate production readiness by integrating a GPU-optimized version into vLLM, enabling continuous guardrailing during token generation with less than 6% overhead even under dense evaluation intervals on large-scale workloads.
Improving Compound Activity Classification via Deep Transfer and Representation Learning
Nov 14, 2021


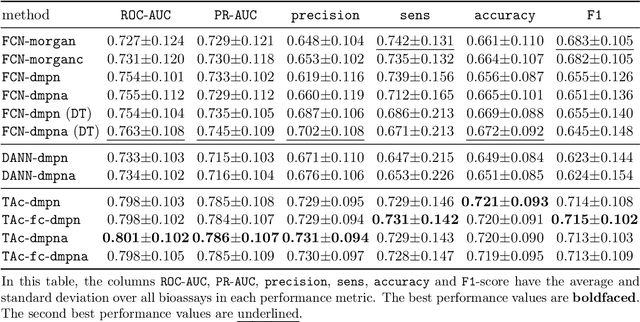
Recent advances in molecular machine learning, especially deep neural networks such as Graph Neural Networks (GNNs) for predicting structure activity relationships (SAR) have shown tremendous potential in computer-aided drug discovery. However, the applicability of such deep neural networks are limited by the requirement of large amounts of training data. In order to cope with limited training data for a target task, transfer learning for SAR modeling has been recently adopted to leverage information from data of related tasks. In this work, in contrast to the popular parameter-based transfer learning such as pretraining, we develop novel deep transfer learning methods TAc and TAc-fc to leverage source domain data and transfer useful information to the target domain. TAc learns to generate effective molecular features that can generalize well from one domain to another, and increase the classification performance in the target domain. Additionally, TAc-fc extends TAc by incorporating novel components to selectively learn feature-wise and compound-wise transferability. We used the bioassay screening data from PubChem, and identified 120 pairs of bioassays such that the active compounds in each pair are more similar to each other compared to its inactive compounds. Overall, TAc achieves the best performance with average ROC-AUC of 0.801; it significantly improves ROC-AUC of 83% target tasks with average task-wise performance improvement of 7.102%, compared to the best baseline FCN-dmpna (DT). Our experiments clearly demonstrate that TAc achieves significant improvement over all baselines across a large number of target tasks. Furthermore, although TAc-fc achieves slightly worse ROC-AUC on average compared to TAc (0.798 vs 0.801), TAc-fc still achieves the best performance on more tasks in terms of PR-AUC and F1 compared to other methods.
An Annotated Corpus for Machine Reading of Instructions in Wet Lab Protocols
May 01, 2018


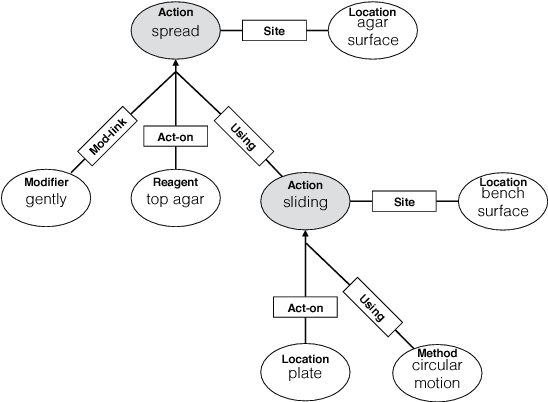
We describe an effort to annotate a corpus of natural language instructions consisting of 622 wet lab protocols to facilitate automatic or semi-automatic conversion of protocols into a machine-readable format and benefit biological research. Experimental results demonstrate the utility of our corpus for developing machine learning approaches to shallow semantic parsing of instructional texts. We make our annotated Wet Lab Protocol Corpus available to the research community.