 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum-based minimization of the Ginzburg-Landau functional on Euclidean spaces and graphs
Dec 31, 2024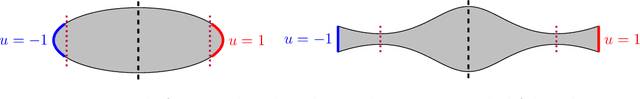

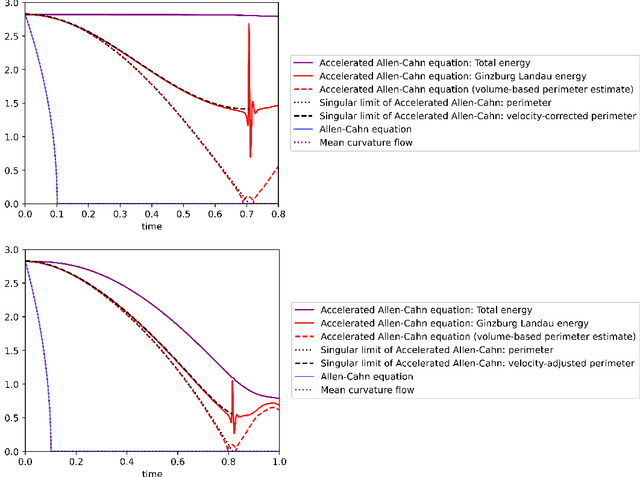
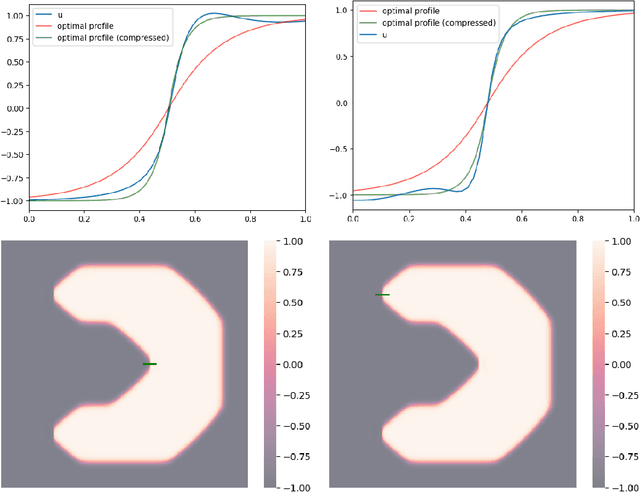
We study the momentum-based minimization of a diffuse perimeter functional on Euclidean spaces and on graphs with applications to semi-supervised classification tasks in machine learning. While the gradient flow in the task at hand is a parabolic partial differential equation, the momentum-method corresponds to a damped hyperbolic PDE, leading to qualitatively and quantitatively different trajectories. Using a convex-concave splitting-based FISTA-type time discretization, we demonstrate empirically that momentum can lead to faster convergence if the time step size is large but not too large. With large time steps, the PDE analysis offers only limited insight into the geometric behavior of solutions and typical hyperbolic phenomena like loss of regularity are not be observed in sample simulations.
Nesterov acceleration in benignly non-convex landscapes
Oct 10, 2024While momentum-based optimization algorithms are commonly used in the notoriously non-convex optimization problems of deep learning, their analysis has historically been restricted to the convex and strongly convex setting. In this article, we partially close this gap between theory and practice and demonstrate that virtually identical guarantees can be obtained in optimization problems with a `benign' non-convexity. We show that these weaker geometric assumptions are well justified in overparametrized deep learning, at least locally. Variations of this result are obtained for a continuous time model of Nesterov's accelerated gradient descent algorithm (NAG), the classical discrete time version of NAG, and versions of NAG with stochastic gradient estimates with purely additive noise and with noise that exhibits both additive and multiplicative scaling.
Achieving acceleration despite very noisy gradients
Feb 10, 2023We present a novel momentum-based first order optimization method (AGNES) which provably achieves acceleration for convex minimization, even if the stochastic noise in the gradient estimates is many orders of magnitude larger than the gradient itself. Here we model the noise as having a variance which is proportional to the magnitude of the underlying gradient. We argue, based upon empirical evidence, that this is appropriate for mini-batch gradients in overparameterized deep learning. Furthermore, we demonstrate that the method achieves competitive performance in the training of CNNs on MNIST and CIFAR-10.