 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Grounded Multi-Agent Synthetic Data Generation for Tool-Augmented LLMs
Jun 15, 2026Training tool-augmented LLM agents requires large corpora of multi-turn, tool-grounded conversational data that is expensive to annotate, privacy-constrained in production settings, and largely absent from public datasets. We present StateGen, a synthetic data generation platform that produces scored, reasoning-trace-rich training conversations by orchestrating a four-role LLM loop: a persona-conditioned user simulator, an agent under test, a state-grounded tool simulator, and a multi-axis LLM judge. The key architectural contribution is an authoritative state manager that maintains a structured world-state object across turns, enforcing a backend-is-truth invariant that eliminates the dominant class of tool-call hallucinations by construction. StateGen extends naturally to hierarchical multi-agent settings by declaring sub-agents as tools, all sharing a single state object. We report results on 64,698 evaluated conversations across three production corpora: tool-call hallucination scores reach 9.66/10, the system supports persona-driven variation via a 23-dimensional trait vector, and a cleanly separated train and golden evaluation set split confirms the data is not memorization bait (per-criterion gap analysis). Comparison with eight external systems shows that no single publicly available platform combines multi-turn generation, state-grounded tool simulation, hierarchical multi-agent support, and built-in judge scoring.
Ada-RS: Adaptive Rejection Sampling for Selective Thinking
Feb 23, 2026Large language models (LLMs) are increasingly being deployed in cost and latency-sensitive settings. While chain-of-thought improves reasoning, it can waste tokens on simple requests. We study selective thinking for tool-using LLMs and introduce Adaptive Rejection Sampling (Ada-RS), an algorithm-agnostic sample filtering framework for learning selective and efficient reasoning. For each given context, Ada-RS scores multiple sampled completions with an adaptive length-penalized reward then applies stochastic rejection sampling to retain only high-reward candidates (or preference pairs) for downstream optimization. We demonstrate how Ada-RS plugs into both preference pair (e.g. DPO) or grouped policy optimization strategies (e.g. DAPO). Using Qwen3-8B with LoRA on a synthetic tool call-oriented e-commerce benchmark, Ada-RS improves the accuracy-efficiency frontier over standard algorithms by reducing average output tokens by up to 80% and reducing thinking rate by up to 95% while maintaining or improving tool call accuracy. These results highlight that training-signal selection is a powerful lever for efficient reasoning in latency-sensitive deployments.
Toward Scalable Verifiable Reward: Proxy State-Based Evaluation for Multi-turn Tool-Calling LLM Agents
Feb 18, 2026Interactive large language model (LLM) agents operating via multi-turn dialogue and multi-step tool calling are increasingly used in production. Benchmarks for these agents must both reliably compare models and yield on-policy training data. Prior agentic benchmarks (e.g., tau-bench, tau2-bench, AppWorld) rely on fully deterministic backends, which are costly to build and iterate. We propose Proxy State-Based Evaluation, an LLM-driven simulation framework that preserves final state-based evaluation without a deterministic database. Specifically, a scenario specifies the user goal, user/system facts, expected final state, and expected agent behavior, and an LLM state tracker infers a structured proxy state from the full interaction trace. LLM judges then verify goal completion and detect tool/user hallucinations against scenario constraints. Empirically, our benchmark produces stable, model-differentiating rankings across families and inference-time reasoning efforts, and its on-/off-policy rollouts provide supervision that transfers to unseen scenarios. Careful scenario specification yields near-zero simulator hallucination rates as supported by ablation studies. The framework also supports sensitivity analyses over user personas. Human-LLM judge agreement exceeds 90%, indicating reliable automated evaluation. Overall, proxy state-based evaluation offers a practical, scalable alternative to deterministic agentic benchmarks for industrial LLM agents.
NEMO-4-PAYPAL: Leveraging NVIDIA's Nemo Framework for empowering PayPal's Commerce Agent
Dec 25, 2025We present the development and optimization of PayPal's Commerce Agent, powered by NEMO-4-PAYPAL, a multi-agent system designed to revolutionize agentic commerce on the PayPal platform. Through our strategic partnership with NVIDIA, we leveraged the NeMo Framework for LLM model fine-tuning to enhance agent performance. Specifically, we optimized the Search and Discovery agent by replacing our base model with a fine-tuned Nemotron small language model (SLM). We conducted comprehensive experiments using the llama3.1-nemotron-nano-8B-v1 architecture, training LoRA-based models through systematic hyperparameter sweeps across learning rates, optimizers (Adam, AdamW), cosine annealing schedules, and LoRA ranks. Our contributions include: (1) the first application of NVIDIA's NeMo Framework to commerce-specific agent optimization, (2) LLM powered fine-tuning strategy for retrieval-focused commerce tasks, (3) demonstration of significant improvements in latency and cost while maintaining agent quality, and (4) a scalable framework for multi-agent system optimization in production e-commerce environments. Our results demonstrate that the fine-tuned Nemotron SLM effectively resolves the key performance issue in the retrieval component, which represents over 50\% of total agent response time, while maintaining or enhancing overall system performance.
HierCat: Hierarchical Query Categorization from Weakly Supervised Data at Facebook Marketplace
Feb 22, 2023Query categorization at customer-to-customer e-commerce platforms like Facebook Marketplace is challenging due to the vagueness of search intent, noise in real-world data, and imbalanced training data across languages. Its deployment also needs to consider challenges in scalability and downstream integration in order to translate modeling advances into better search result relevance. In this paper we present HierCat, the query categorization system at Facebook Marketplace. HierCat addresses these challenges by leveraging multi-task pre-training of dual-encoder architectures with a hierarchical inference step to effectively learn from weakly supervised training data mined from searcher engagement. We show that HierCat not only outperforms popular methods in offline experiments, but also leads to 1.4% improvement in NDCG and 4.3% increase in searcher engagement at Facebook Marketplace Search in online A/B testing.
Min-similarity association rules for identifying past comorbidities of recurrent ED and inpatient patients
Oct 26, 2021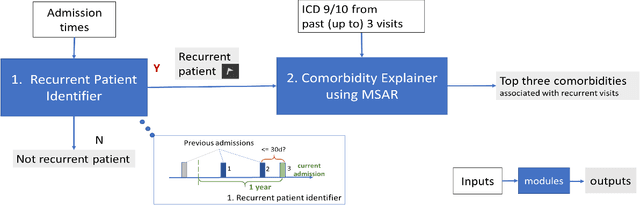
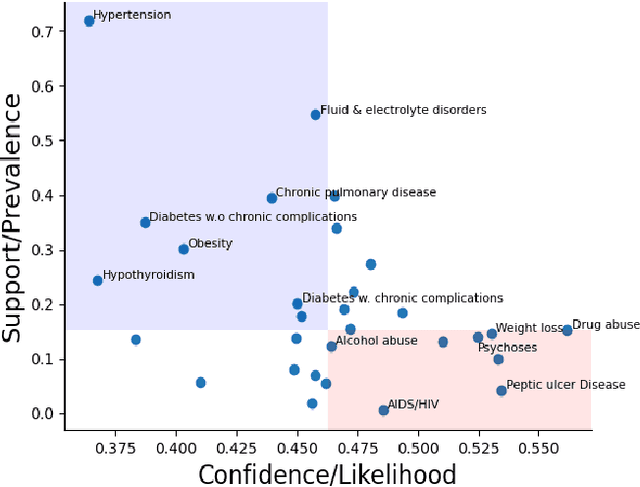
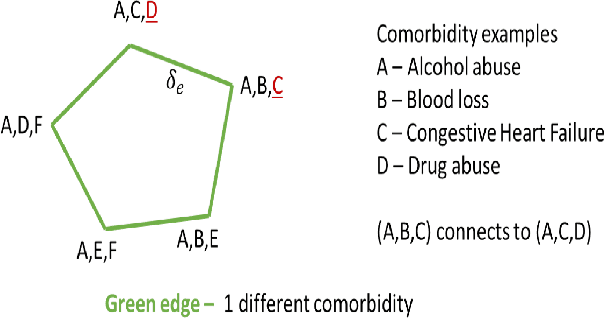
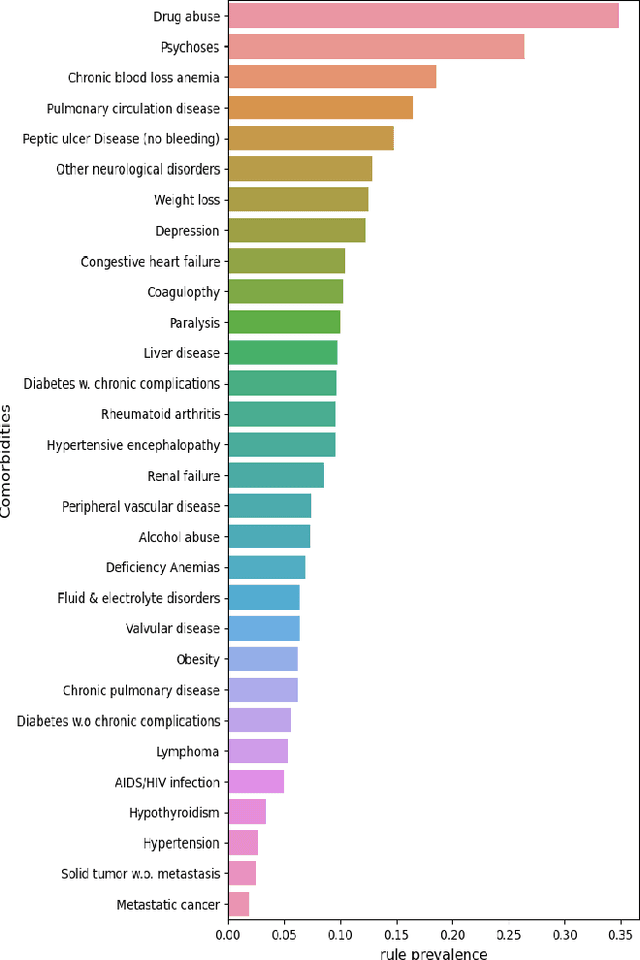
In the hospital setting, a small percentage of recurrent frequent patients contribute to a disproportional amount of healthcare resource usage. Moreover, in many of these cases, patient outcomes can be greatly improved by reducing reoccurring visits, especially when they are associated with substance abuse, mental health, and medical factors that could be improved by social-behavioral interventions, outpatient or preventative care. To address this, we developed a computationally efficient and interpretable framework that both identifies recurrent patients with high utilization and determines which comorbidities contribute most to their recurrent visits. Specifically, we present a novel algorithm, called the minimum similarity association rules (MSAR), balancing confidence-support trade-off, to determine the conditions most associated with reoccurring Emergency department (ED) and inpatient visits. We validate MSAR on a large Electric Health Record (EHR) dataset. Part of the solution is deployed in Philips product Patient Flow Capacity Suite (PFCS).
An Annotated Corpus for Machine Reading of Instructions in Wet Lab Protocols
May 01, 2018


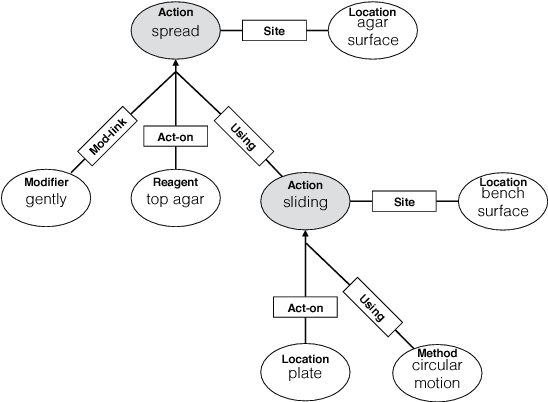
We describe an effort to annotate a corpus of natural language instructions consisting of 622 wet lab protocols to facilitate automatic or semi-automatic conversion of protocols into a machine-readable format and benefit biological research. Experimental results demonstrate the utility of our corpus for developing machine learning approaches to shallow semantic parsing of instructional texts. We make our annotated Wet Lab Protocol Corpus available to the research community.