 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurSAMERE: Reliable Adversarial Purification via Sharpness-Aware Minimization of Expected Reconstruction Error
Feb 06, 2026We propose a novel deterministic purification method to improve adversarial robustness by mapping a potentially adversarial sample toward a nearby sample that lies close to a mode of the data distribution, where classifiers are more reliable. We design the method to be deterministic to ensure reliable test accuracy and to prevent the degradation of effective robustness observed in stochastic purification approaches when the adversary has full knowledge of the system and its randomness. We employ a score model trained by minimizing the expected reconstruction error of noise-corrupted data, thereby learning the structural characteristics of the input data distribution. Given a potentially adversarial input, the method searches within its local neighborhood for a purified sample that minimizes the expected reconstruction error under noise corruption and then feeds this purified sample to the classifier. During purification, sharpness-aware minimization is used to guide the purified samples toward flat regions of the expected reconstruction error landscape, thereby enhancing robustness. We further show that, as the noise level decreases, minimizing the expected reconstruction error biases the purified sample toward local maximizers of the Gaussian-smoothed density; under additional local assumptions on the score model, we prove recovery of a local maximizer in the small-noise limit. Experimental results demonstrate significant gains in adversarial robustness over state-of-the-art methods under strong deterministic white-box attacks.
Sparse Bayesian Learning for Label Efficiency in Cardiac Real-Time MRI
Mar 27, 2025



Cardiac real-time magnetic resonance imaging (MRI) is an emerging technology that images the heart at up to 50 frames per second, offering insight into the respiratory effects on the heartbeat. However, this method significantly increases the number of images that must be segmented to derive critical health indicators. Although neural networks perform well on inner slices, predictions on outer slices are often unreliable. This work proposes sparse Bayesian learning (SBL) to predict the ventricular volume on outer slices with minimal manual labeling to address this challenge. The ventricular volume over time is assumed to be dominated by sparse frequencies corresponding to the heart and respiratory rates. Moreover, SBL identifies these sparse frequencies on well-segmented inner slices by optimizing hyperparameters via type -II likelihood, automatically pruning irrelevant components. The identified sparse frequencies guide the selection of outer slice images for labeling, minimizing posterior variance. This work provides performance guarantees for the greedy algorithm. Testing on patient data demonstrates that only a few labeled images are necessary for accurate volume prediction. The labeling procedure effectively avoids selecting inefficient images. Furthermore, the Bayesian approach provides uncertainty estimates, highlighting unreliable predictions (e.g., when choosing suboptimal labels).
Filtered Markovian Projection: Dimensionality Reduction in Filtering for Stochastic Reaction Networks
Feb 11, 2025Stochastic reaction networks (SRNs) model stochastic effects for various applications, including intracellular chemical or biological processes and epidemiology. A typical challenge in practical problems modeled by SRNs is that only a few state variables can be dynamically observed. Given the measurement trajectories, one can estimate the conditional probability distribution of unobserved (hidden) state variables by solving a stochastic filtering problem. In this setting, the conditional distribution evolves over time according to an extensive or potentially infinite-dimensional system of coupled ordinary differential equations with jumps, known as the filtering equation. The current numerical filtering techniques, such as the Filtered Finite State Projection (DAmbrosio et al., 2022), are hindered by the curse of dimensionality, significantly affecting their computational performance. To address these limitations, we propose to use a dimensionality reduction technique based on the Markovian projection (MP), initially introduced for forward problems (Ben Hammouda et al., 2024). In this work, we explore how to adapt the existing MP approach to the filtering problem and introduce a novel version of the MP, the Filtered MP, that guarantees the consistency of the resulting estimator. The novel method combines a particle filter with reduced variance and solving the filtering equations in a low-dimensional space, exploiting the advantages of both approaches. The analysis and empirical results highlight the superior computational efficiency of projection methods compared to the existing filtered finite state projection in the large dimensional setting.
Adaptive Random Fourier Features Training Stabilized By Resampling With Applications in Image Regression
Oct 08, 2024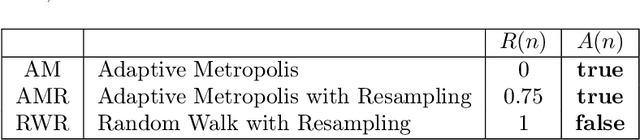
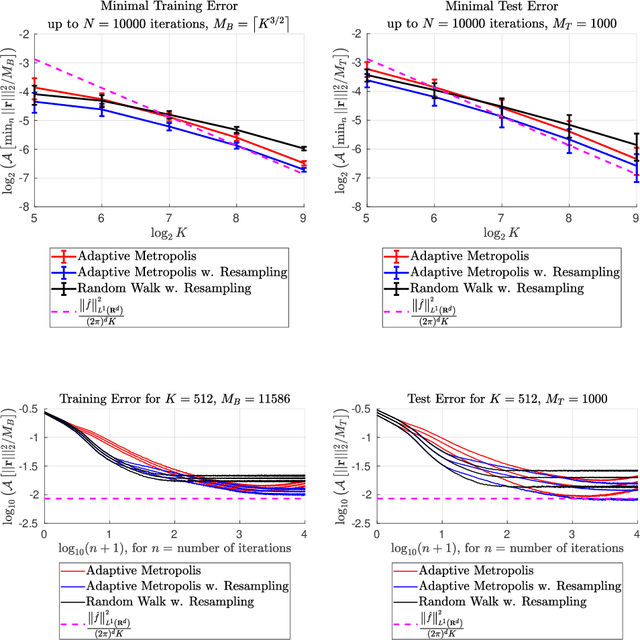

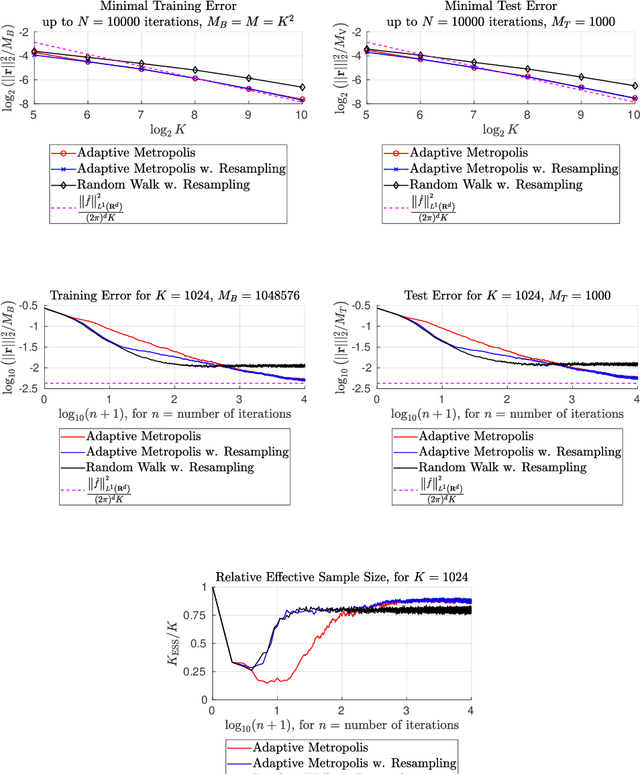
This paper presents an enhanced adaptive random Fourier features (ARFF) training algorithm for shallow neural networks, building upon the work introduced in "Adaptive Random Fourier Features with Metropolis Sampling", Kammonen et al., Foundations of Data Science, 2(3):309--332, 2020. This improved method uses a particle filter type resampling technique to stabilize the training process and reduce sensitivity to parameter choices. With resampling, the Metropolis test may also be omitted, reducing the number of hyperparameters and reducing the computational cost per iteration, compared to ARFF. We present comprehensive numerical experiments demonstrating the efficacy of our proposed algorithm in function regression tasks, both as a standalone method and as a pre-training step before gradient-based optimization, here Adam. Furthermore, we apply our algorithm to a simple image regression problem, showcasing its utility in sampling frequencies for the random Fourier features (RFF) layer of coordinate-based multilayer perceptrons (MLPs). In this context, we use the proposed algorithm to sample the parameters of the RFF layer in an automated manner.
Comparing Spectral Bias and Robustness For Two-Layer Neural Networks: SGD vs Adaptive Random Fourier Features
Feb 01, 2024We present experimental results highlighting two key differences resulting from the choice of training algorithm for two-layer neural networks. The spectral bias of neural networks is well known, while the spectral bias dependence on the choice of training algorithm is less studied. Our experiments demonstrate that an adaptive random Fourier features algorithm (ARFF) can yield a spectral bias closer to zero compared to the stochastic gradient descent optimizer (SGD). Additionally, we train two identically structured classifiers, employing SGD and ARFF, to the same accuracy levels and empirically assess their robustness against adversarial noise attacks.
Scalable method for Bayesian experimental design without integrating over posterior distribution
Jun 30, 2023We address the computational efficiency in solving the A-optimal Bayesian design of experiments problems for which the observational model is based on partial differential equations and, consequently, is computationally expensive to evaluate. A-optimality is a widely used and easy-to-interpret criterion for the Bayesian design of experiments. The criterion seeks the optimal experiment design by minimizing the expected conditional variance, also known as the expected posterior variance. This work presents a novel likelihood-free method for seeking the A-optimal design of experiments without sampling or integrating the Bayesian posterior distribution. In our approach, the expected conditional variance is obtained via the variance of the conditional expectation using the law of total variance, while we take advantage of the orthogonal projection property to approximate the conditional expectation. Through an asymptotic error estimation, we show that the intractability of the posterior does not affect the performance of our approach. We use an artificial neural network (ANN) to approximate the nonlinear conditional expectation to implement our method. For dealing with continuous experimental design parameters, we integrate the training process of the ANN into minimizing the expected conditional variance. Specifically, we propose a non-local approximation of the conditional expectation and apply transfer learning to reduce the number of evaluations of the observation model. Through numerical experiments, we demonstrate that our method significantly reduces the number of observational model evaluations compared with common importance sampling-based approaches. This reduction is crucial, considering the computationally expensive nature of these models.
Nonlinear Isometric Manifold Learning for Injective Normalizing Flows
Mar 08, 2022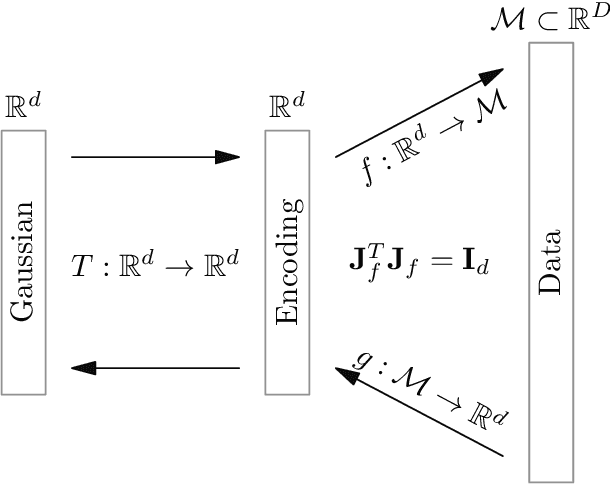



To model manifold data using normalizing flows, we propose to employ the isometric autoencoder to design nonlinear encodings with explicit inverses. The isometry allows us to separate manifold learning and density estimation and train both parts to high accuracy. Applied to the MNIST data set, the combined approach generates high-quality images.
On the equivalence of different adaptive batch size selection strategies for stochastic gradient descent methods
Sep 22, 2021


In this study, we demonstrate that the norm test and inner product/orthogonality test presented in \cite{Bol18} are equivalent in terms of the convergence rates associated with Stochastic Gradient Descent (SGD) methods if $\epsilon^2=\theta^2+\nu^2$ with specific choices of $\theta$ and $\nu$. Here, $\epsilon$ controls the relative statistical error of the norm of the gradient while $\theta$ and $\nu$ control the relative statistical error of the gradient in the direction of the gradient and in the direction orthogonal to the gradient, respectively. Furthermore, we demonstrate that the inner product/orthogonality test can be as inexpensive as the norm test in the best case scenario if $\theta$ and $\nu$ are optimally selected, but the inner product/orthogonality test will never be more computationally affordable than the norm test if $\epsilon^2=\theta^2+\nu^2$. Finally, we present two stochastic optimization problems to illustrate our results.
Machine learning-based conditional mean filter: a generalization of the ensemble Kalman filter for nonlinear data assimilation
Jun 15, 2021



Filtering is a data assimilation technique that performs the sequential inference of dynamical systems states from noisy observations. Herein, we propose a machine learning-based ensemble conditional mean filter (ML-EnCMF) for tracking possibly high-dimensional non-Gaussian state models with nonlinear dynamics based on sparse observations. The proposed filtering method is developed based on the conditional expectation and numerically implemented using machine learning (ML) techniques combined with the ensemble method. The contribution of this work is twofold. First, we demonstrate that the ensembles assimilated using the ensemble conditional mean filter (EnCMF) provide an unbiased estimator of the Bayesian posterior mean, and their variance matches the expected conditional variance. Second, we implement the EnCMF using artificial neural networks, which have a significant advantage in representing nonlinear functions over high-dimensional domains such as the conditional mean. Finally, we demonstrate the effectiveness of the ML-EnCMF for tracking the states of Lorenz-63 and Lorenz-96 systems under the chaotic regime. Numerical results show that the ML-EnCMF outperforms the ensemble Kalman filter.
Wind Field Reconstruction with Adaptive Random Fourier Features
Feb 04, 2021
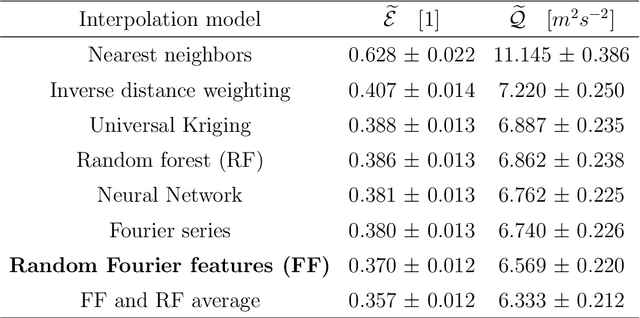
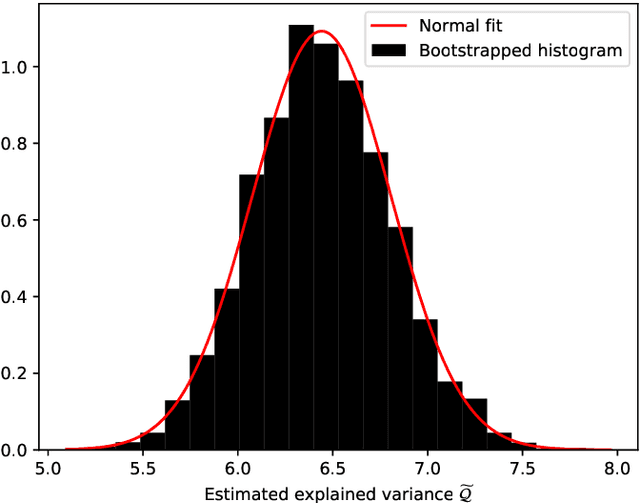
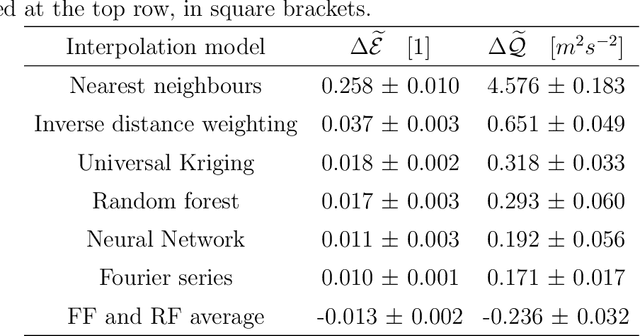
We investigate the use of spatial interpolation methods for reconstructing the horizontal near-surface wind field given a sparse set of measurements. In particular, random Fourier features is compared to a set of benchmark methods including Kriging and Inverse distance weighting. Random Fourier features is a linear model $\beta(\pmb x) = \sum_{k=1}^K \beta_k e^{i\omega_k \pmb x}$ approximating the velocity field, with frequencies $\omega_k$ randomly sampled and amplitudes $\beta_k$ trained to minimize a loss function. We include a physically motivated divergence penalty term $|\nabla \cdot \beta(\pmb x)|^2$, as well as a penalty on the Sobolev norm. We derive a bound on the generalization error and derive a sampling density that minimizes the bound. Following (arXiv:2007.10683 [math.NA]), we devise an adaptive Metropolis-Hastings algorithm for sampling the frequencies of the optimal distribution. In our experiments, our random Fourier features model outperforms the benchmark models.