 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable method for Bayesian experimental design without integrating over posterior distribution
Jun 30, 2023We address the computational efficiency in solving the A-optimal Bayesian design of experiments problems for which the observational model is based on partial differential equations and, consequently, is computationally expensive to evaluate. A-optimality is a widely used and easy-to-interpret criterion for the Bayesian design of experiments. The criterion seeks the optimal experiment design by minimizing the expected conditional variance, also known as the expected posterior variance. This work presents a novel likelihood-free method for seeking the A-optimal design of experiments without sampling or integrating the Bayesian posterior distribution. In our approach, the expected conditional variance is obtained via the variance of the conditional expectation using the law of total variance, while we take advantage of the orthogonal projection property to approximate the conditional expectation. Through an asymptotic error estimation, we show that the intractability of the posterior does not affect the performance of our approach. We use an artificial neural network (ANN) to approximate the nonlinear conditional expectation to implement our method. For dealing with continuous experimental design parameters, we integrate the training process of the ANN into minimizing the expected conditional variance. Specifically, we propose a non-local approximation of the conditional expectation and apply transfer learning to reduce the number of evaluations of the observation model. Through numerical experiments, we demonstrate that our method significantly reduces the number of observational model evaluations compared with common importance sampling-based approaches. This reduction is crucial, considering the computationally expensive nature of these models.
Physics-informed Spectral Learning: the Discrete Helmholtz--Hodge Decomposition
Feb 21, 2023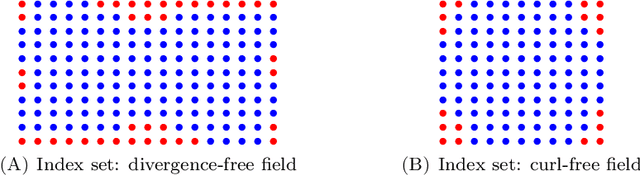
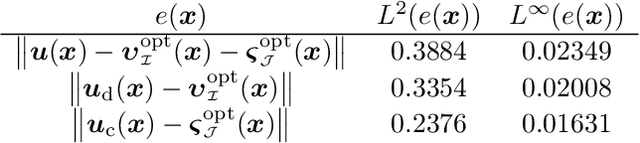
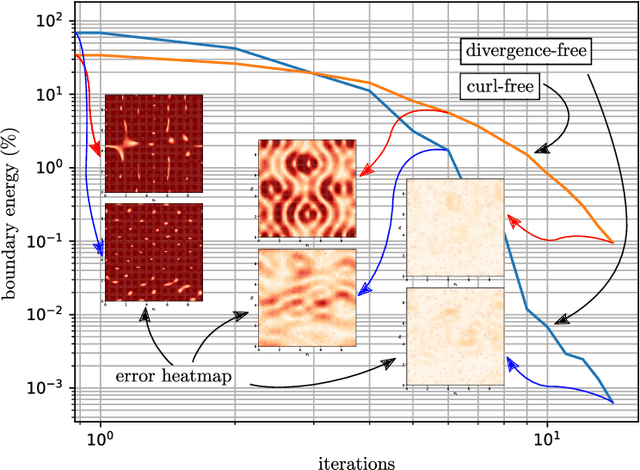
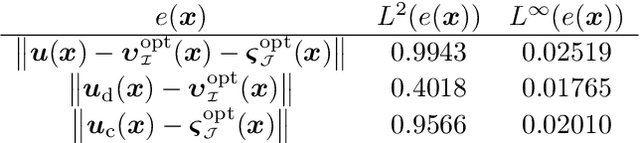
In this work, we further develop the Physics-informed Spectral Learning (PiSL) by Espath et al. \cite{Esp21} based on a discrete $L^2$ projection to solve the discrete Hodge--Helmholtz decomposition from sparse data. Within this physics-informed statistical learning framework, we adaptively build a sparse set of Fourier basis functions with corresponding coefficients by solving a sequence of minimization problems where the set of basis functions is augmented greedily at each optimization problem. Moreover, our PiSL computational framework enjoys spectral (exponential) convergence. We regularize the minimization problems with the seminorm of the fractional Sobolev space in a Tikhonov fashion. In the Fourier setting, the divergence- and curl-free constraints become a finite set of linear algebraic equations. The proposed computational framework combines supervised and unsupervised learning techniques in that we use data concomitantly with the projection onto divergence- and curl-free spaces. We assess the capabilities of our method in various numerical examples including the `Storm of the Century' with satellite data from 1993.
Deep nurbs -- admissible neural networks
Oct 25, 2022In this study, we propose a new numerical scheme for physics-informed neural networks (PINNs) that enables precise and inexpensive solution for partial differential equations (PDEs) in case of arbitrary geometries while strictly enforcing Dirichlet boundary conditions. The proposed approach combines admissible NURBS parametrizations required to define the physical domain and the Dirichlet boundary conditions with a PINN solver. The fundamental boundary conditions are automatically satisfied in this novel Deep NURBS framework. We verified our new approach using two-dimensional elliptic PDEs when considering arbitrary geometries, including non-Lipschitz domains. Compared to the classical PINN solver, the Deep NURBS estimator has a remarkably high convergence rate for all the studied problems. Moreover, a desirable accuracy was realized for most of the studied PDEs using only one hidden layer of neural networks. This novel approach is considered to pave the way for more effective solutions for high-dimensional problems by allowing for more realistic physics-informed statistical learning to solve PDE-based variational problems.
On the equivalence of different adaptive batch size selection strategies for stochastic gradient descent methods
Sep 22, 2021


In this study, we demonstrate that the norm test and inner product/orthogonality test presented in \cite{Bol18} are equivalent in terms of the convergence rates associated with Stochastic Gradient Descent (SGD) methods if $\epsilon^2=\theta^2+\nu^2$ with specific choices of $\theta$ and $\nu$. Here, $\epsilon$ controls the relative statistical error of the norm of the gradient while $\theta$ and $\nu$ control the relative statistical error of the gradient in the direction of the gradient and in the direction orthogonal to the gradient, respectively. Furthermore, we demonstrate that the inner product/orthogonality test can be as inexpensive as the norm test in the best case scenario if $\theta$ and $\nu$ are optimally selected, but the inner product/orthogonality test will never be more computationally affordable than the norm test if $\epsilon^2=\theta^2+\nu^2$. Finally, we present two stochastic optimization problems to illustrate our results.