 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-Conditioned Parameterized Quantum Circuits as Universal Approximators for Distributions over Quantum States
May 27, 2026Many applications in quantum simulation, quantum chemistry, and quantum machine learning require not a single quantum state but an ensemble of states characterizing the heterogeneity of a target system. Preparing such ensembles state-by-state is prohibitive in both variational and fault-tolerant settings, motivating a generative-modeling approach. We introduce latent-conditioned parameterized quantum circuits (LPQCs), a hybrid quantum-classical framework in which classical neural networks map a latent variable sampled from a prior distribution to the parameters of a parameterized quantum circuit. We prove that LPQCs are universal approximators for probability measures over density operators in the $1$-Wasserstein distance, extending classical universal approximation theorems to the quantum-distribution setting. We additionally introduce a multimodal latent prior and a mixture-of-experts circuit architecture, and show that it empirically alleviates the barren plateau problem during optimization. Numerical experiments validate the framework on a synthetic multi-cluster ensemble of mixed quantum states and on a QM9-derived ensemble of 3-D molecular structures. In these tasks, LPQC outperforms recent quantum generative baselines while remaining competitive with typical classical baselines at substantially reduced output dimensionality. By leveraging classical expressivity in the latent space, LPQCs offer a tractable route to quantum generative modeling.
Learning Quantum Data Distribution via Chaotic Quantum Diffusion Model
Feb 25, 2026Generative models for quantum data pose significant challenges but hold immense potential in fields such as chemoinformatics and quantum physics. Quantum denoising diffusion probabilistic models (QuDDPMs) enable efficient learning of quantum data distributions by progressively scrambling and denoising quantum states; however, existing implementations typically rely on circuit-based random unitary dynamics that can be costly to realize and sensitive to control imperfections, particularly on analog quantum hardware. We propose the chaotic quantum diffusion model, a framework that generates projected ensembles via chaotic Hamiltonian time evolution, providing a flexible and hardware-compatible diffusion mechanism. Requiring only global, time-independent control, our approach substantially reduces implementation overhead across diverse analog quantum platforms while achieving accuracy comparable to QuDDPMs. This method improves trainability and robustness, broadening the applicability of quantum generative modeling.
Universality of Many-body Projected Ensemble for Learning Quantum Data Distribution
Jan 26, 2026Generating quantum data by learning the underlying quantum distribution poses challenges in both theoretical and practical scenarios, yet it is a critical task for understanding quantum systems. A fundamental question in quantum machine learning (QML) is the universality of approximation: whether a parameterized QML model can approximate any quantum distribution. We address this question by proving a universality theorem for the Many-body Projected Ensemble (MPE) framework, a method for quantum state design that uses a single many-body wave function to prepare random states. This demonstrates that MPE can approximate any distribution of pure states within a 1-Wasserstein distance error. This theorem provides a rigorous guarantee of universal expressivity, addressing key theoretical gaps in QML. For practicality, we propose an Incremental MPE variant with layer-wise training to improve the trainability. Numerical experiments on clustered quantum states and quantum chemistry datasets validate MPE's efficacy in learning complex quantum data distributions.
Iterative Quantum Feature Maps
Jun 24, 2025


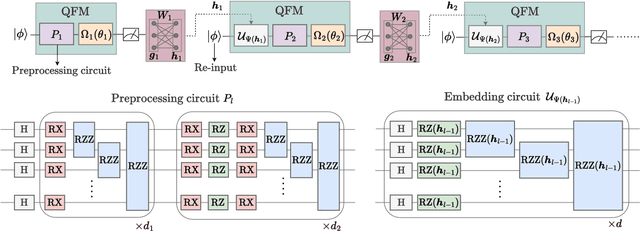
Quantum machine learning models that leverage quantum circuits as quantum feature maps (QFMs) are recognized for their enhanced expressive power in learning tasks. Such models have demonstrated rigorous end-to-end quantum speedups for specific families of classification problems. However, deploying deep QFMs on real quantum hardware remains challenging due to circuit noise and hardware constraints. Additionally, variational quantum algorithms often suffer from computational bottlenecks, particularly in accurate gradient estimation, which significantly increases quantum resource demands during training. We propose Iterative Quantum Feature Maps (IQFMs), a hybrid quantum-classical framework that constructs a deep architecture by iteratively connecting shallow QFMs with classically computed augmentation weights. By incorporating contrastive learning and a layer-wise training mechanism, IQFMs effectively reduces quantum runtime and mitigates noise-induced degradation. In tasks involving noisy quantum data, numerical experiments show that IQFMs outperforms quantum convolutional neural networks, without requiring the optimization of variational quantum parameters. Even for a typical classical image classification benchmark, a carefully designed IQFMs achieves performance comparable to that of classical neural networks. This framework presents a promising path to address current limitations and harness the full potential of quantum-enhanced machine learning.
Molecular Quantum Transformer
Mar 27, 2025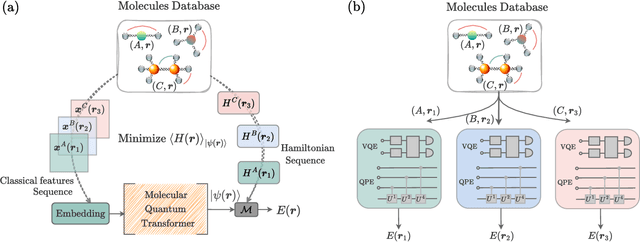
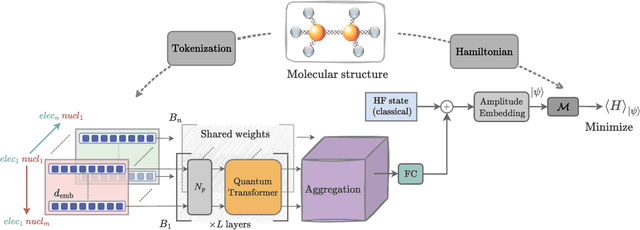
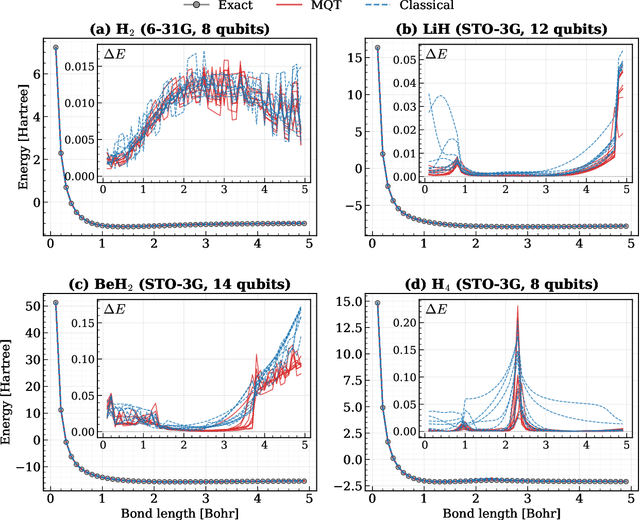
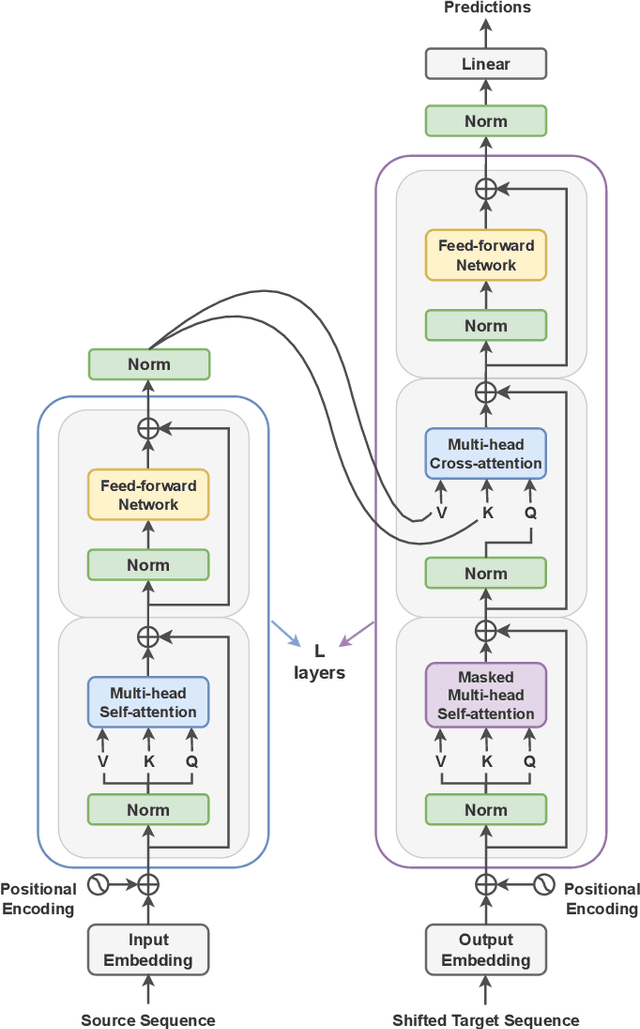
The Transformer model, renowned for its powerful attention mechanism, has achieved state-of-the-art performance in various artificial intelligence tasks but faces challenges such as high computational cost and memory usage. Researchers are exploring quantum computing to enhance the Transformer's design, though it still shows limited success with classical data. With a growing focus on leveraging quantum machine learning for quantum data, particularly in quantum chemistry, we propose the Molecular Quantum Transformer (MQT) for modeling interactions in molecular quantum systems. By utilizing quantum circuits to implement the attention mechanism on the molecular configurations, MQT can efficiently calculate ground-state energies for all configurations. Numerical demonstrations show that in calculating ground-state energies for H_2, LiH, BeH_2, and H_4, MQT outperforms the classical Transformer, highlighting the promise of quantum effects in Transformer structures. Furthermore, its pretraining capability on diverse molecular data facilitates the efficient learning of new molecules, extending its applicability to complex molecular systems with minimal additional effort. Our method offers an alternative to existing quantum algorithms for estimating ground-state energies, opening new avenues in quantum chemistry and materials science.
Enhancing variational quantum algorithms by balancing training on classical and quantum hardware
Mar 20, 2025Quantum computers offer a promising route to tackling problems that are classically intractable such as in prime-factorization, solving large-scale linear algebra and simulating complex quantum systems, but require fault-tolerant quantum hardware. On the other hand, variational quantum algorithms (VQAs) have the potential to provide a near-term route to quantum utility or advantage, and is usually constructed by using parametrized quantum circuits (PQCs) in combination with a classical optimizer for training. Although VQAs have been proposed for a multitude of tasks such as ground-state estimation, combinatorial optimization and unitary compilation, there remain major challenges in its trainability and resource costs on quantum hardware. Here we address these challenges by adopting Hardware Efficient and dynamical LIe algebra Supported Ansatz (HELIA), and propose two training schemes that combine an existing g-sim method (that uses the underlying group structure of the operators) and the Parameter-Shift Rule (PSR). Our improvement comes from distributing the resources required for gradient estimation and training to both classical and quantum hardware. We numerically test our proposal for ground-state estimation using Variational Quantum Eigensolver (VQE) and classification of quantum phases using quantum neural networks. Our methods show better accuracy and success of trials, and also need fewer calls to the quantum hardware on an average than using only PSR (upto 60% reduction), that runs exclusively on quantum hardware. We also numerically demonstrate the capability of HELIA in mitigating barren plateaus, paving the way for training large-scale quantum models.
Resource-efficient equivariant quantum convolutional neural networks
Oct 02, 2024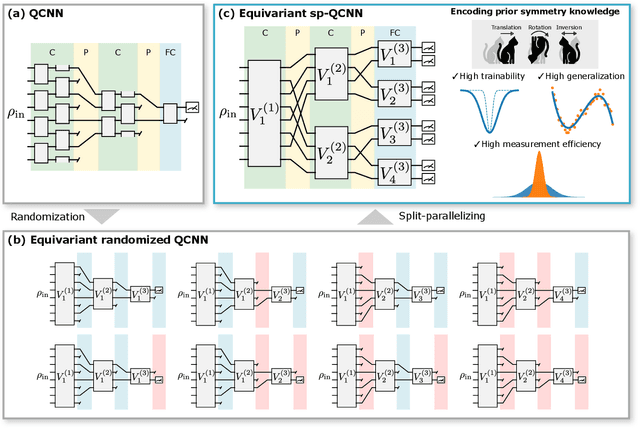
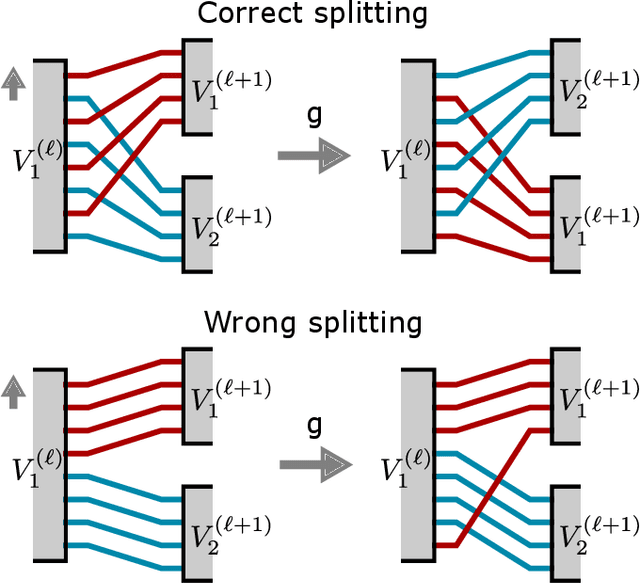
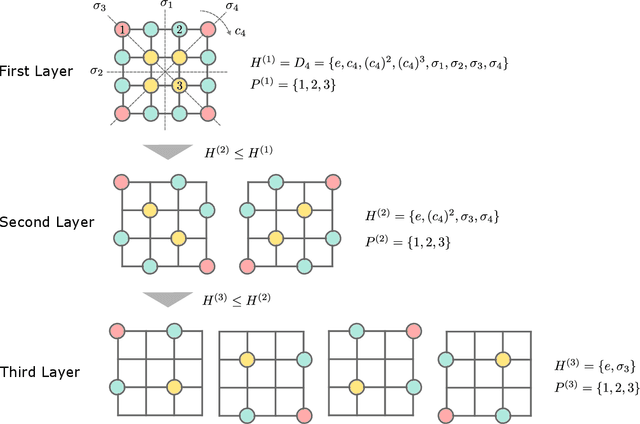
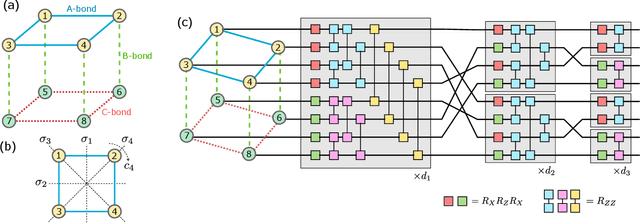
Equivariant quantum neural networks (QNNs) are promising quantum machine learning models that exploit symmetries to provide potential quantum advantages. Despite theoretical developments in equivariant QNNs, their implementation on near-term quantum devices remains challenging due to limited computational resources. This study proposes a resource-efficient model of equivariant quantum convolutional neural networks (QCNNs) called equivariant split-parallelizing QCNN (sp-QCNN). Using a group-theoretical approach, we encode general symmetries into our model beyond the translational symmetry addressed by previous sp-QCNNs. We achieve this by splitting the circuit at the pooling layer while preserving symmetry. This splitting structure effectively parallelizes QCNNs to improve measurement efficiency in estimating the expectation value of an observable and its gradient by order of the number of qubits. Our model also exhibits high trainability and generalization performance, including the absence of barren plateaus. Numerical experiments demonstrate that the equivariant sp-QCNN can be trained and generalized with fewer measurement resources than a conventional equivariant QCNN in a noisy quantum data classification task. Our results contribute to the advancement of practical quantum machine learning algorithms.
Quantum Curriculum Learning
Jul 02, 2024



Quantum machine learning (QML) requires significant quantum resources to achieve quantum advantage. Research should prioritize both the efficient design of quantum architectures and the development of learning strategies to optimize resource usage. We propose a framework called quantum curriculum learning (Q-CurL) for quantum data, where the curriculum introduces simpler tasks or data to the learning model before progressing to more challenging ones. We define the curriculum criteria based on the data density ratio between tasks to determine the curriculum order. We also implement a dynamic learning schedule to emphasize the significance of quantum data in optimizing the loss function. Empirical evidence shows that Q-CurL enhances the training convergence and the generalization for unitary learning tasks and improves the robustness of quantum phase recognition tasks. Our framework provides a general learning strategy, bringing QML closer to realizing practical advantages.
Trade-off between Gradient Measurement Efficiency and Expressivity in Deep Quantum Neural Networks
Jun 26, 2024Quantum neural networks (QNNs) require an efficient training algorithm to achieve practical quantum advantages. A promising approach is the use of gradient-based optimization algorithms, where gradients are estimated through quantum measurements. However, it is generally difficult to efficiently measure gradients in QNNs because the quantum state collapses upon measurement. In this work, we prove a general trade-off between gradient measurement efficiency and expressivity in a wide class of deep QNNs, elucidating the theoretical limits and possibilities of efficient gradient estimation. This trade-off implies that a more expressive QNN requires a higher measurement cost in gradient estimation, whereas we can increase gradient measurement efficiency by reducing the QNN expressivity to suit a given task. We further propose a general QNN ansatz called the stabilizer-logical product ansatz (SLPA), which can reach the upper limit of the trade-off inequality by leveraging the symmetric structure of the quantum circuit. In learning an unknown symmetric function, the SLPA drastically reduces the quantum resources required for training while maintaining accuracy and trainability compared to a well-designed symmetric circuit based on the parameter-shift method. Our results not only reveal a theoretical understanding of efficient training in QNNs but also provide a standard and broadly applicable efficient QNN design.
Hierarchy of the echo state property in quantum reservoir computing
Mar 05, 2024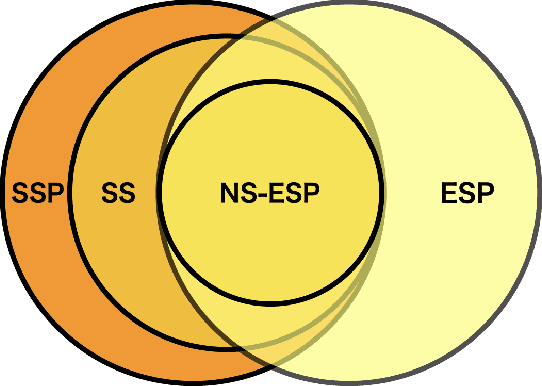
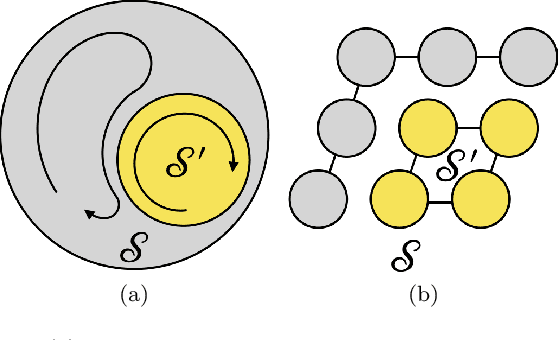
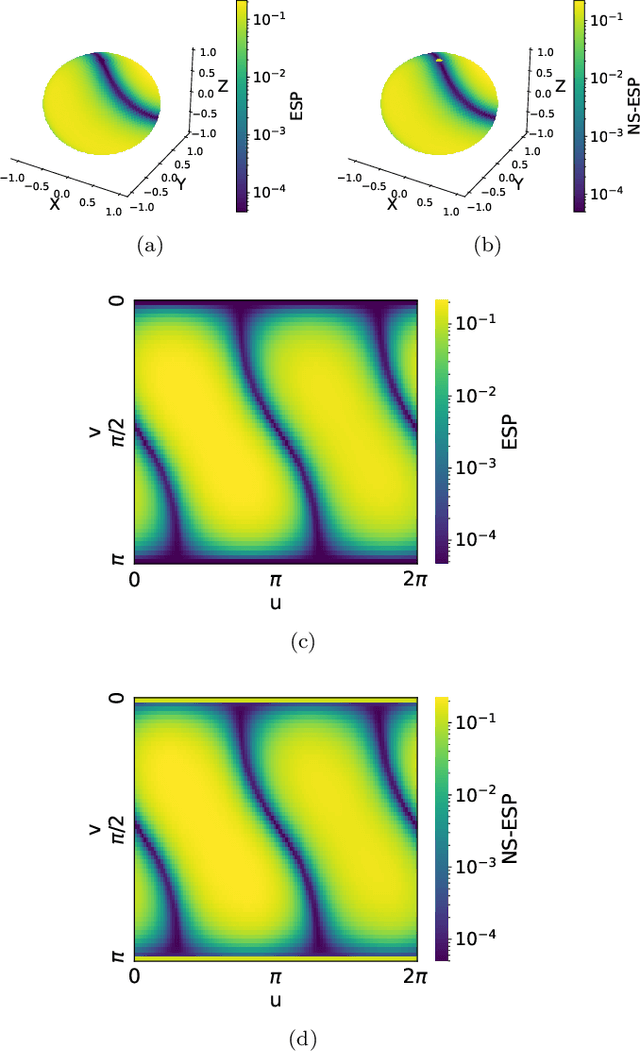
The echo state property (ESP) represents a fundamental concept in the reservoir computing (RC) framework that ensures output-only training of reservoir networks by being agnostic to the initial states and far past inputs. However, the traditional definition of ESP does not describe possible non-stationary systems in which statistical properties evolve. To address this issue, we introduce two new categories of ESP: \textit{non-stationary ESP}, designed for potentially non-stationary systems, and \textit{subspace/subset ESP}, designed for systems whose subsystems have ESP. Following the definitions, we numerically demonstrate the correspondence between non-stationary ESP in the quantum reservoir computer (QRC) framework with typical Hamiltonian dynamics and input encoding methods using non-linear autoregressive moving-average (NARMA) tasks. We also confirm the correspondence by computing linear/non-linear memory capacities that quantify input-dependent components within reservoir states. Our study presents a new understanding of the practical design of QRC and other possibly non-stationary RC systems in which non-stationary systems and subsystems are exploited.