 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models
Sep 12, 2022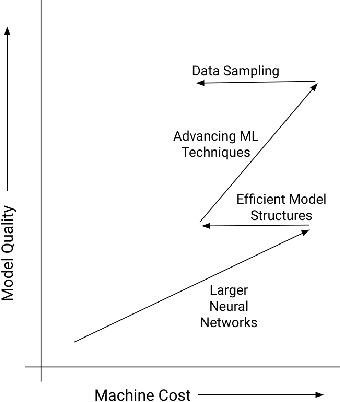
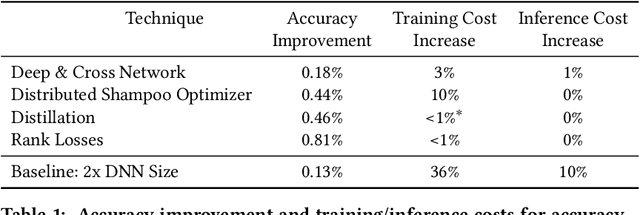
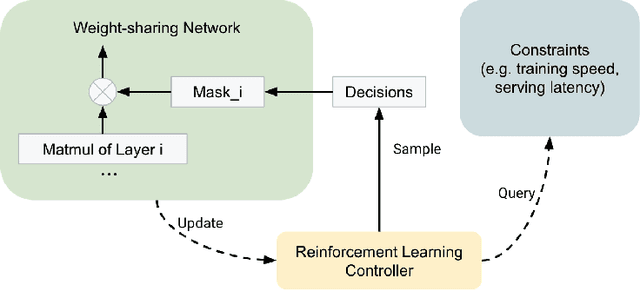

For industrial-scale advertising systems, prediction of ad click-through rate (CTR) is a central problem. Ad clicks constitute a significant class of user engagements and are often used as the primary signal for the usefulness of ads to users. Additionally, in cost-per-click advertising systems where advertisers are charged per click, click rate expectations feed directly into value estimation. Accordingly, CTR model development is a significant investment for most Internet advertising companies. Engineering for such problems requires many machine learning (ML) techniques suited to online learning that go well beyond traditional accuracy improvements, especially concerning efficiency, reproducibility, calibration, credit attribution. We present a case study of practical techniques deployed in Google's search ads CTR model. This paper provides an industry case study highlighting important areas of current ML research and illustrating how impactful new ML methods are evaluated and made useful in a large-scale industrial setting.
How Important Is a Neuron?
May 30, 2018
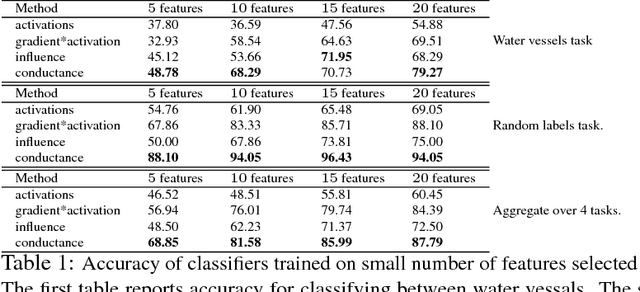

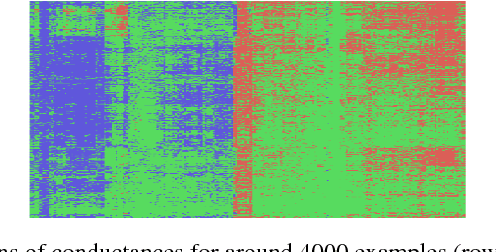
The problem of attributing a deep network's prediction to its \emph{input/base} features is well-studied. We introduce the notion of \emph{conductance} to extend the notion of attribution to the understanding the importance of \emph{hidden} units. Informally, the conductance of a hidden unit of a deep network is the \emph{flow} of attribution via this hidden unit. We use conductance to understand the importance of a hidden unit to the prediction for a specific input, or over a set of inputs. We evaluate the effectiveness of conductance in multiple ways, including theoretical properties, ablation studies, and a feature selection task. The empirical evaluations are done using the Inception network over ImageNet data, and a sentiment analysis network over reviews. In both cases, we demonstrate the effectiveness of conductance in identifying interesting insights about the internal workings of these networks.
Axiomatic Attribution for Deep Networks
Jun 13, 2017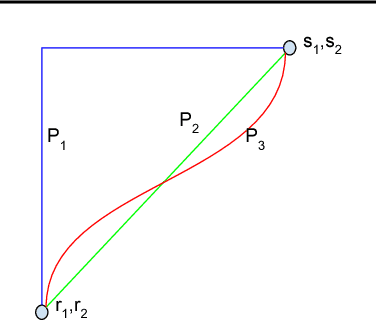

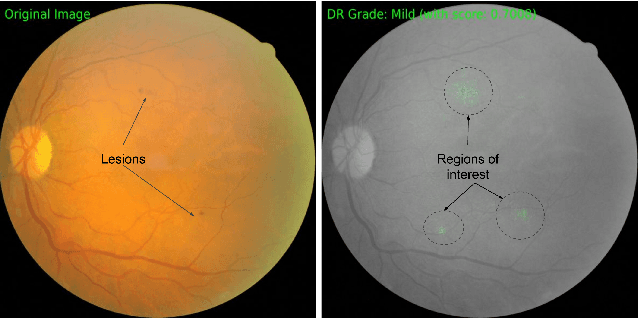

We study the problem of attributing the prediction of a deep network to its input features, a problem previously studied by several other works. We identify two fundamental axioms---Sensitivity and Implementation Invariance that attribution methods ought to satisfy. We show that they are not satisfied by most known attribution methods, which we consider to be a fundamental weakness of those methods. We use the axioms to guide the design of a new attribution method called Integrated Gradients. Our method requires no modification to the original network and is extremely simple to implement; it just needs a few calls to the standard gradient operator. We apply this method to a couple of image models, a couple of text models and a chemistry model, demonstrating its ability to debug networks, to extract rules from a network, and to enable users to engage with models better.
Gradients of Counterfactuals
Nov 15, 2016

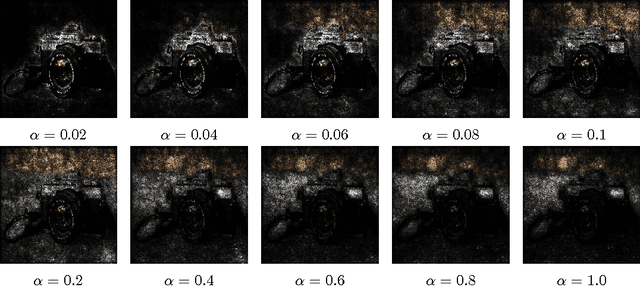

Gradients have been used to quantify feature importance in machine learning models. Unfortunately, in nonlinear deep networks, not only individual neurons but also the whole network can saturate, and as a result an important input feature can have a tiny gradient. We study various networks, and observe that this phenomena is indeed widespread, across many inputs. We propose to examine interior gradients, which are gradients of counterfactual inputs constructed by scaling down the original input. We apply our method to the GoogleNet architecture for object recognition in images, as well as a ligand-based virtual screening network with categorical features and an LSTM based language model for the Penn Treebank dataset. We visualize how interior gradients better capture feature importance. Furthermore, interior gradients are applicable to a wide variety of deep networks, and have the attribution property that the feature importance scores sum to the the prediction score. Best of all, interior gradients can be computed just as easily as gradients. In contrast, previous methods are complex to implement, which hinders practical adoption.