 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Important Is a Neuron?
May 30, 2018
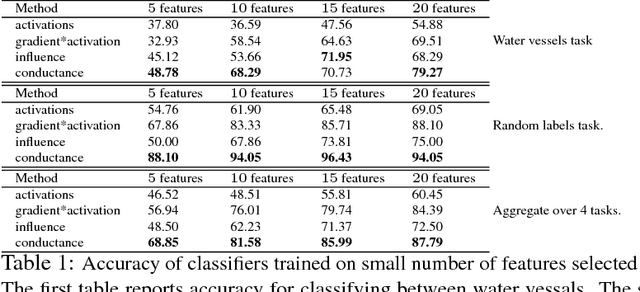

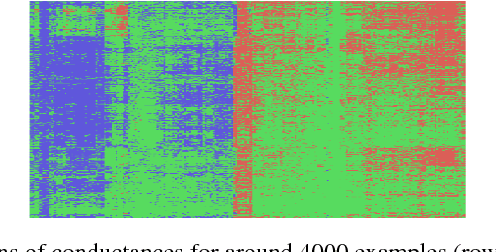
The problem of attributing a deep network's prediction to its \emph{input/base} features is well-studied. We introduce the notion of \emph{conductance} to extend the notion of attribution to the understanding the importance of \emph{hidden} units. Informally, the conductance of a hidden unit of a deep network is the \emph{flow} of attribution via this hidden unit. We use conductance to understand the importance of a hidden unit to the prediction for a specific input, or over a set of inputs. We evaluate the effectiveness of conductance in multiple ways, including theoretical properties, ablation studies, and a feature selection task. The empirical evaluations are done using the Inception network over ImageNet data, and a sentiment analysis network over reviews. In both cases, we demonstrate the effectiveness of conductance in identifying interesting insights about the internal workings of these networks.
Did the Model Understand the Question?
May 14, 2018
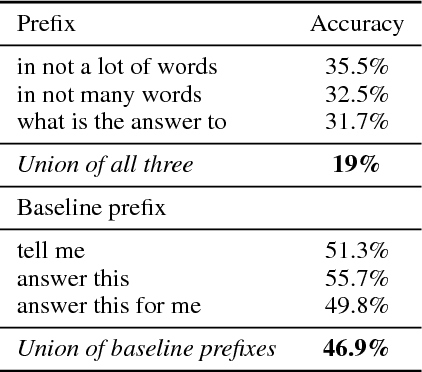
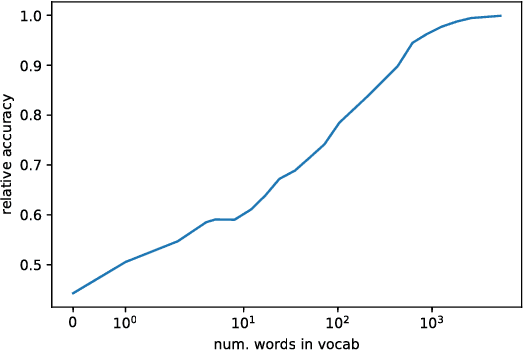

We analyze state-of-the-art deep learning models for three tasks: question answering on (1) images, (2) tables, and (3) passages of text. Using the notion of \emph{attribution} (word importance), we find that these deep networks often ignore important question terms. Leveraging such behavior, we perturb questions to craft a variety of adversarial examples. Our strongest attacks drop the accuracy of a visual question answering model from $61.1\%$ to $19\%$, and that of a tabular question answering model from $33.5\%$ to $3.3\%$. Additionally, we show how attributions can strengthen attacks proposed by Jia and Liang (2017) on paragraph comprehension models. Our results demonstrate that attributions can augment standard measures of accuracy and empower investigation of model performance. When a model is accurate but for the wrong reasons, attributions can surface erroneous logic in the model that indicates inadequacies in the test data.
It was the training data pruning too!
Mar 12, 2018We study the current best model (KDG) for question answering on tabular data evaluated over the WikiTableQuestions dataset. Previous ablation studies performed against this model attributed the model's performance to certain aspects of its architecture. In this paper, we find that the model's performance also crucially depends on a certain pruning of the data used to train the model. Disabling the pruning step drops the accuracy of the model from 43.3% to 36.3%. The large impact on the performance of the KDG model suggests that the pruning may be a useful pre-processing step in training other semantic parsers as well.
Abductive Matching in Question Answering
Sep 10, 2017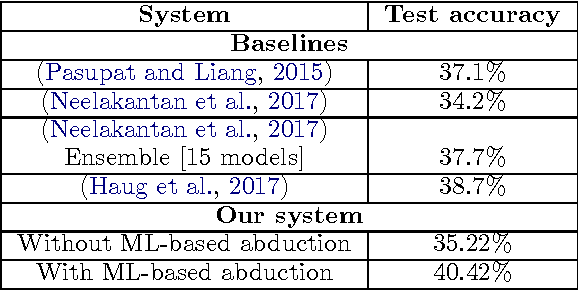
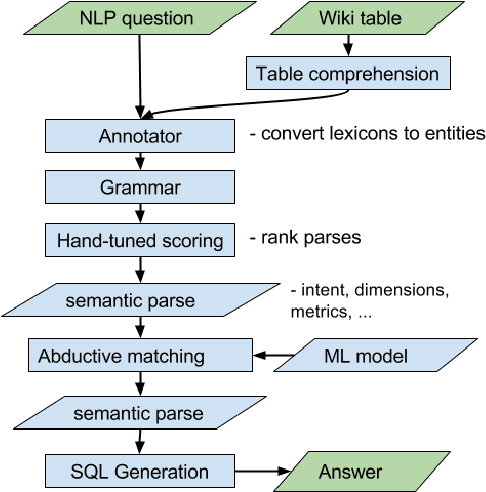

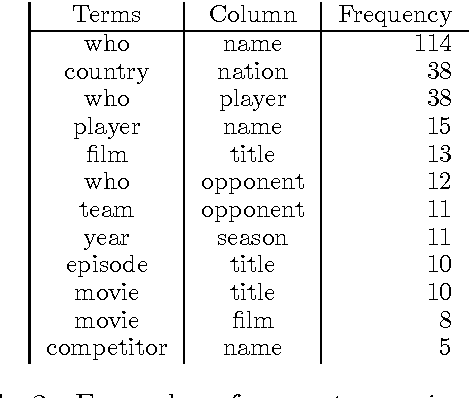
We study question-answering over semi-structured data. We introduce a new way to apply the technique of semantic parsing by applying machine learning only to provide annotations that the system infers to be missing; all the other parsing logic is in the form of manually authored rules. In effect, the machine learning is used to provide non-syntactic matches, a step that is ill-suited to manual rules. The advantage of this approach is in its debuggability and in its transparency to the end-user. We demonstrate the effectiveness of the approach by achieving state-of-the-art performance of 40.42% accuracy on a standard benchmark dataset over tables from Wikipedia.