 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradients of Counterfactuals
Paper and Code


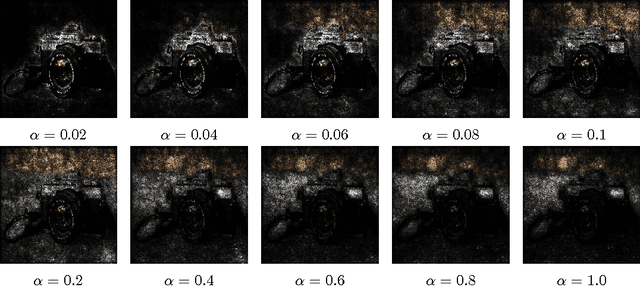

Gradients have been used to quantify feature importance in machine learning models. Unfortunately, in nonlinear deep networks, not only individual neurons but also the whole network can saturate, and as a result an important input feature can have a tiny gradient. We study various networks, and observe that this phenomena is indeed widespread, across many inputs. We propose to examine interior gradients, which are gradients of counterfactual inputs constructed by scaling down the original input. We apply our method to the GoogleNet architecture for object recognition in images, as well as a ligand-based virtual screening network with categorical features and an LSTM based language model for the Penn Treebank dataset. We visualize how interior gradients better capture feature importance. Furthermore, interior gradients are applicable to a wide variety of deep networks, and have the attribution property that the feature importance scores sum to the the prediction score. Best of all, interior gradients can be computed just as easily as gradients. In contrast, previous methods are complex to implement, which hinders practical adoption.