 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer
Oct 13, 2022



Recently, transformer-based networks have shown impressive results in semantic segmentation. Yet for real-time semantic segmentation, pure CNN-based approaches still dominate in this field, due to the time-consuming computation mechanism of transformer. We propose RTFormer, an efficient dual-resolution transformer for real-time semantic segmenation, which achieves better trade-off between performance and efficiency than CNN-based models. To achieve high inference efficiency on GPU-like devices, our RTFormer leverages GPU-Friendly Attention with linear complexity and discards the multi-head mechanism. Besides, we find that cross-resolution attention is more efficient to gather global context information for high-resolution branch by spreading the high level knowledge learned from low-resolution branch. Extensive experiments on mainstream benchmarks demonstrate the effectiveness of our proposed RTFormer, it achieves state-of-the-art on Cityscapes, CamVid and COCOStuff, and shows promising results on ADE20K. Code is available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
PalQuant: Accelerating High-precision Networks on Low-precision Accelerators
Aug 03, 2022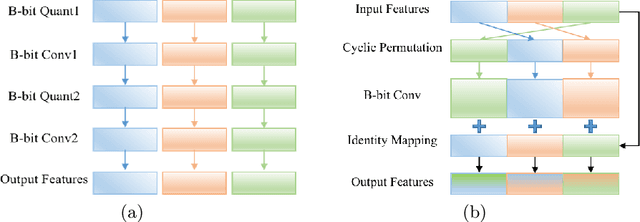
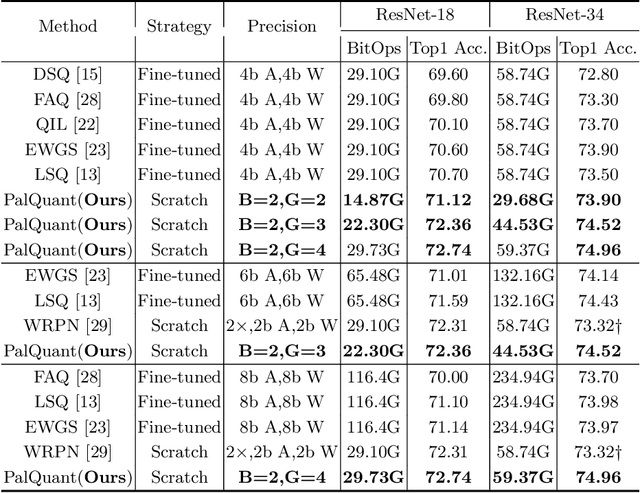


Recently low-precision deep learning accelerators (DLAs) have become popular due to their advantages in chip area and energy consumption, yet the low-precision quantized models on these DLAs bring in severe accuracy degradation. One way to achieve both high accuracy and efficient inference is to deploy high-precision neural networks on low-precision DLAs, which is rarely studied. In this paper, we propose the PArallel Low-precision Quantization (PalQuant) method that approximates high-precision computations via learning parallel low-precision representations from scratch. In addition, we present a novel cyclic shuffle module to boost the cross-group information communication between parallel low-precision groups. Extensive experiments demonstrate that PalQuant has superior performance to state-of-the-art quantization methods in both accuracy and inference speed, e.g., for ResNet-18 network quantization, PalQuant can obtain 0.52\% higher accuracy and 1.78$\times$ speedup simultaneously over their 4-bit counter-part on a state-of-the-art 2-bit accelerator. Code is available at \url{https://github.com/huqinghao/PalQuant}.
MixFormer: Mixing Features across Windows and Dimensions
Apr 12, 2022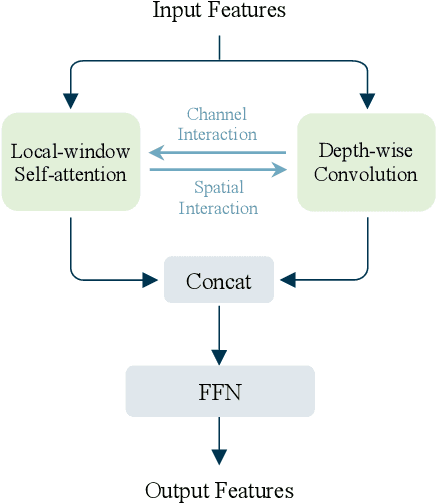

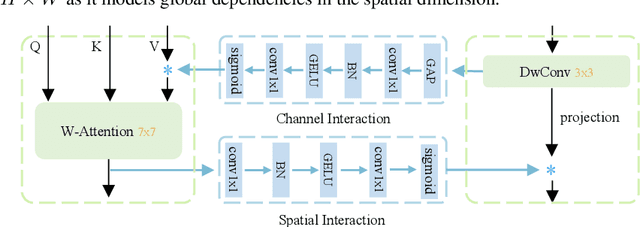

While local-window self-attention performs notably in vision tasks, it suffers from limited receptive field and weak modeling capability issues. This is mainly because it performs self-attention within non-overlapped windows and shares weights on the channel dimension. We propose MixFormer to find a solution. First, we combine local-window self-attention with depth-wise convolution in a parallel design, modeling cross-window connections to enlarge the receptive fields. Second, we propose bi-directional interactions across branches to provide complementary clues in the channel and spatial dimensions. These two designs are integrated to achieve efficient feature mixing among windows and dimensions. Our MixFormer provides competitive results on image classification with EfficientNet and shows better results than RegNet and Swin Transformer. Performance in downstream tasks outperforms its alternatives by significant margins with less computational costs in 5 dense prediction tasks on MS COCO, ADE20k, and LVIS. Code is available at \url{https://github.com/PaddlePaddle/PaddleClas}.