 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerrainMesh: Metric-Semantic Terrain Reconstruction from Aerial Images Using Joint 2D-3D Learning
Apr 23, 2022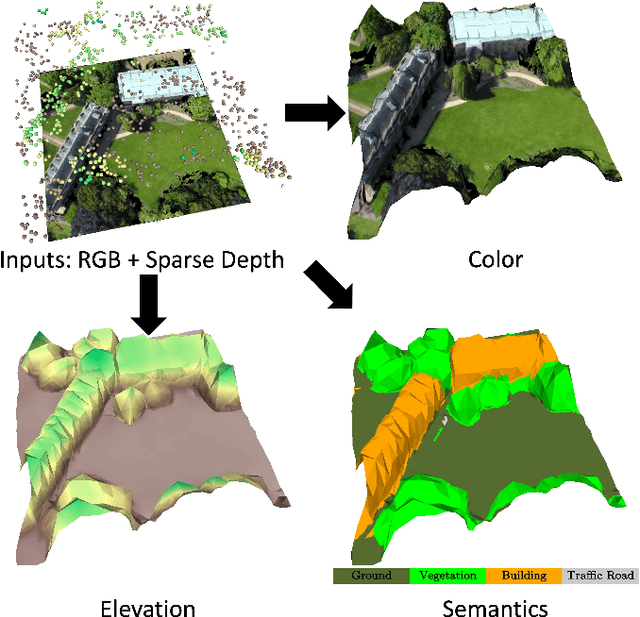

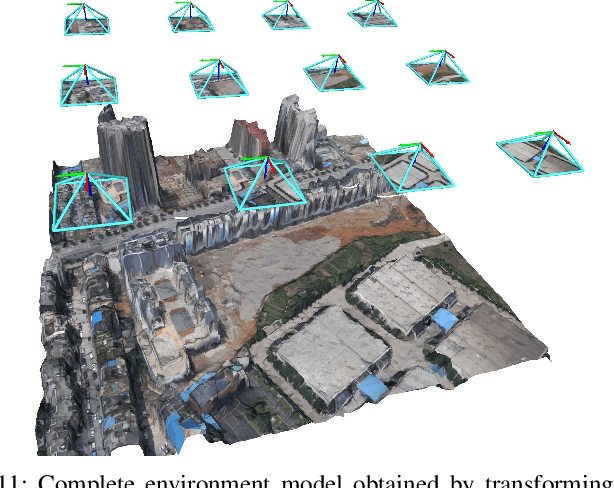
This paper considers outdoor terrain mapping using RGB images obtained from an aerial vehicle. While feature-based localization and mapping techniques deliver real-time vehicle odometry and sparse keypoint depth reconstruction, a dense model of the environment geometry and semantics (vegetation, buildings, etc.) is usually recovered offline with significant computation and storage. This paper develops a joint 2D-3D learning approach to reconstruct a local metric-semantic mesh at each camera keyframe maintained by a visual odometry algorithm. Given the estimated camera trajectory, the local meshes can be assembled into a global environment model to capture the terrain topology and semantics during online operation. A local mesh is reconstructed using an initialization and refinement stage. In the initialization stage, we estimate the mesh vertex elevation by solving a least squares problem relating the vertex barycentric coordinates to the sparse keypoint depth measurements. In the refinement stage, we associate 2D image and semantic features with the 3D mesh vertices using camera projection and apply graph convolution to refine the mesh vertex spatial coordinates and semantic features based on joint 2D and 3D supervision. Quantitative and qualitative evaluation using real aerial images show the potential of our method to support environmental monitoring and surveillance applications.
ELLIPSDF: Joint Object Pose and Shape Optimization with a Bi-level Ellipsoid and Signed Distance Function Description
Aug 01, 2021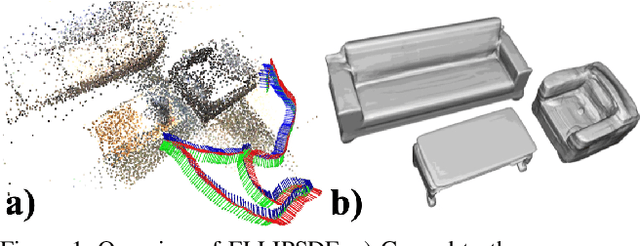
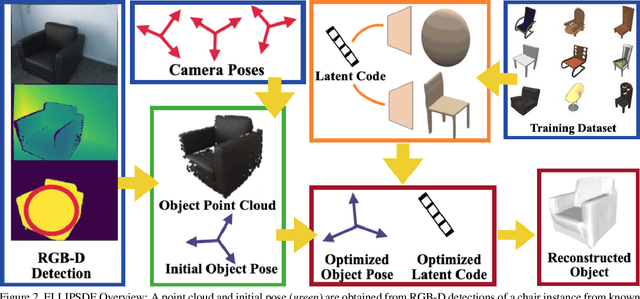
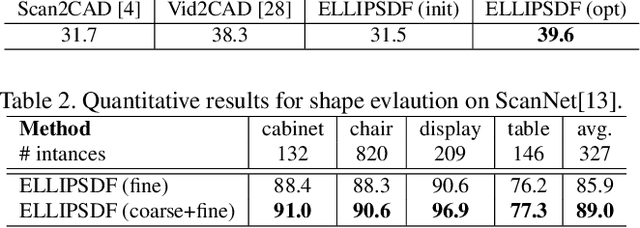
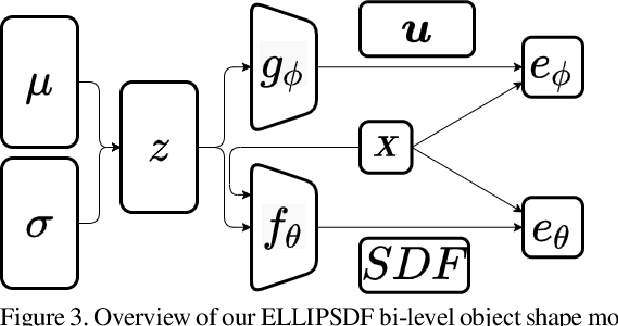
Autonomous systems need to understand the semantics and geometry of their surroundings in order to comprehend and safely execute object-level task specifications. This paper proposes an expressive yet compact model for joint object pose and shape optimization, and an associated optimization algorithm to infer an object-level map from multi-view RGB-D camera observations. The model is expressive because it captures the identities, positions, orientations, and shapes of objects in the environment. It is compact because it relies on a low-dimensional latent representation of implicit object shape, allowing onboard storage of large multi-category object maps. Different from other works that rely on a single object representation format, our approach has a bi-level object model that captures both the coarse level scale as well as the fine level shape details. Our approach is evaluated on the large-scale real-world ScanNet dataset and compared against state-of-the-art methods.
CORSAIR: Convolutional Object Retrieval and Symmetry-AIded Registration
Mar 11, 2021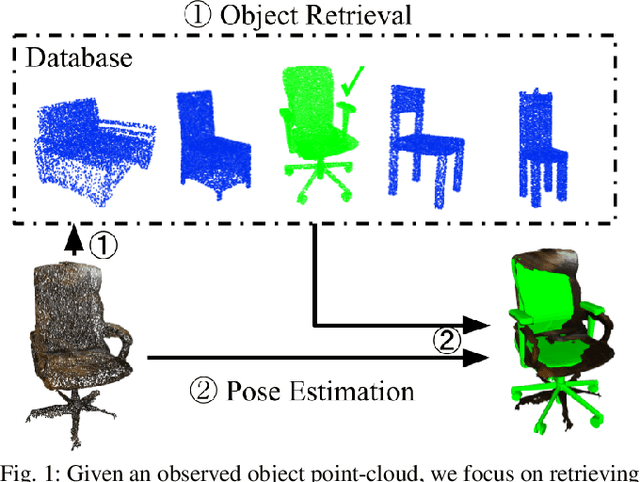
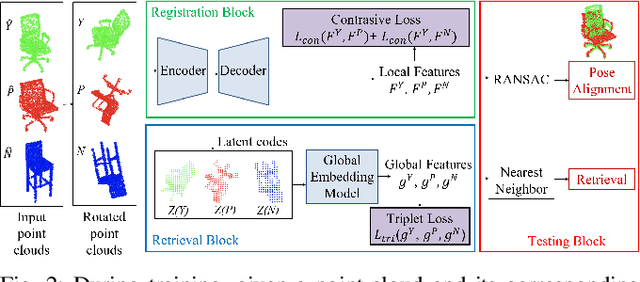
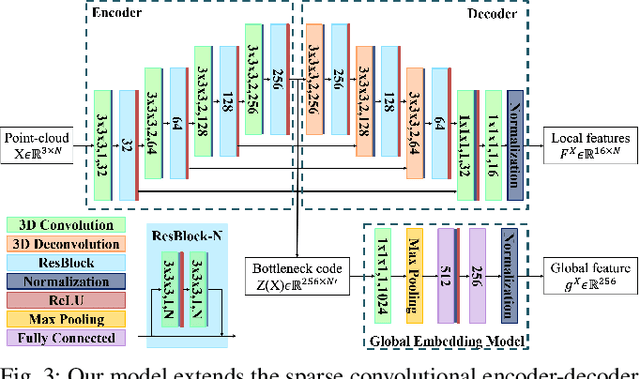
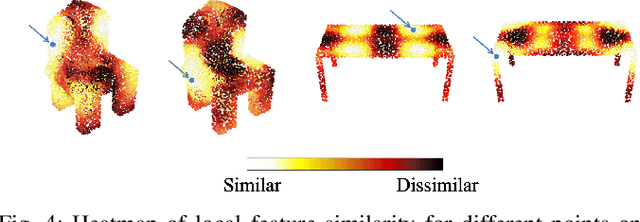
This paper considers online object-level mapping using partial point-cloud observations obtained online in an unknown environment. We develop and approach for fully Convolutional Object Retrieval and Symmetry-AIded Registration (CORSAIR). Our model extends the Fully Convolutional Geometric Features model to learn a global object-shape embedding in addition to local point-wise features from the point-cloud observations. The global feature is used to retrieve a similar object from a category database, and the local features are used for robust pose registration between the observed and the retrieved object. Our formulation also leverages symmetries, present in the object shapes, to obtain promising local-feature pairs from different symmetry classes for matching. We present results from synthetic and real-world datasets with different object categories to verify the robustness of our method.
Fully Convolutional Geometric Features for Category-level Object Alignment
Mar 08, 2021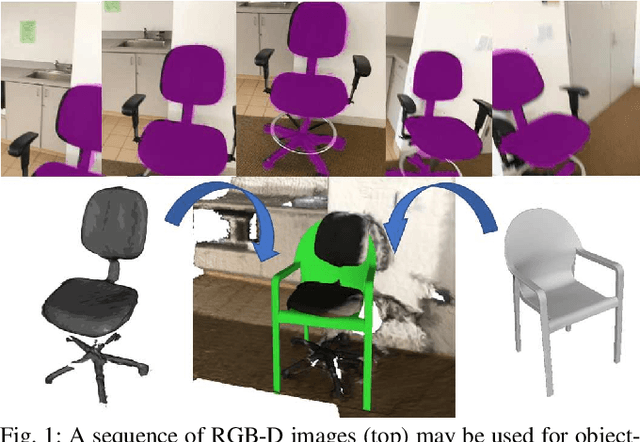
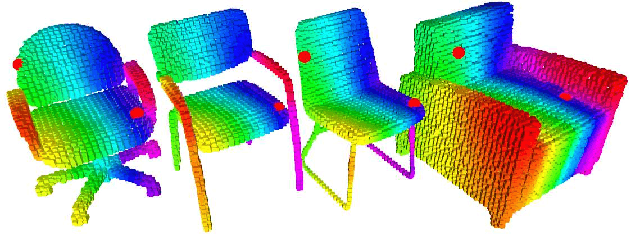
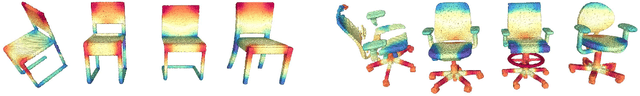
This paper focuses on pose registration of different object instances from the same category. This is required in online object mapping because object instances detected at test time usually differ from the training instances. Our approach transforms instances of the same category to a normalized canonical coordinate frame and uses metric learning to train fully convolutional geometric features. The resulting model is able to generate pairs of matching points between the instances, allowing category-level registration. Evaluation on both synthetic and real-world data shows that our method provides robust features, leading to accurate alignment of instances with different shapes.
* 7 pages, 9 figures
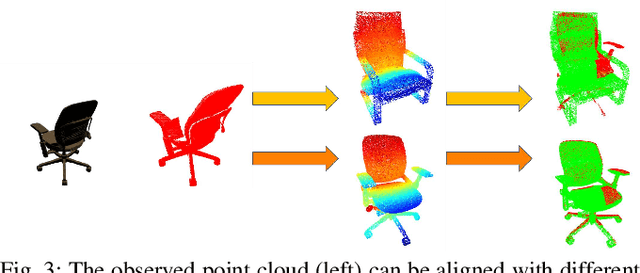
Localization and Mapping using Instance-specific Mesh Models
Mar 08, 2021
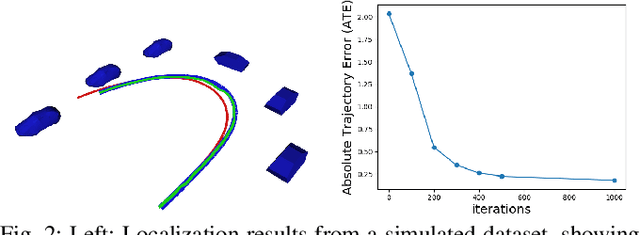
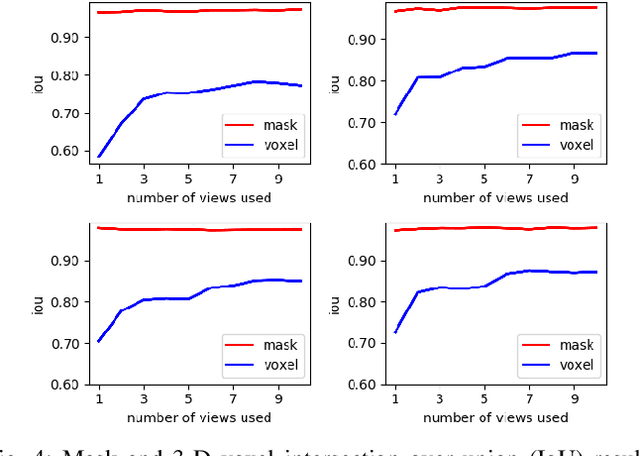
This paper focuses on building semantic maps, containing object poses and shapes, using a monocular camera. This is an important problem because robots need rich understanding of geometry and context if they are to shape the future of transportation, construction, and agriculture. Our contribution is an instance-specific mesh model of object shape that can be optimized online based on semantic information extracted from camera images. Multi-view constraints on the object shape are obtained by detecting objects and extracting category-specific keypoints and segmentation masks. We show that the errors between projections of the mesh model and the observed keypoints and masks can be differentiated in order to obtain accurate instance-specific object shapes. We evaluate the performance of the proposed approach in simulation and on the KITTI dataset by building maps of car poses and shapes.
* 8 pages, 9 figures
Mesh Reconstruction from Aerial Images for Outdoor Terrain Mapping Using Joint 2D-3D Learning
Jan 06, 2021
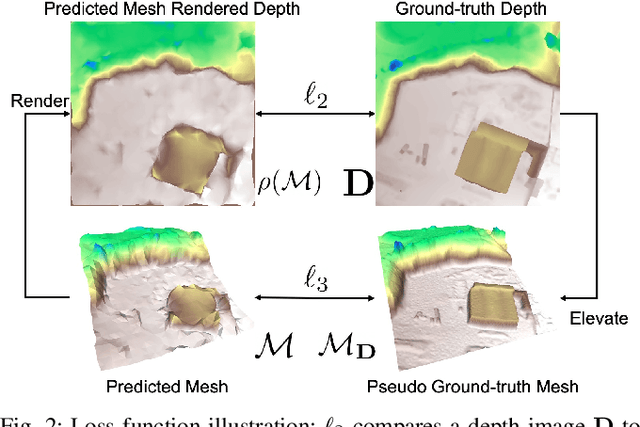
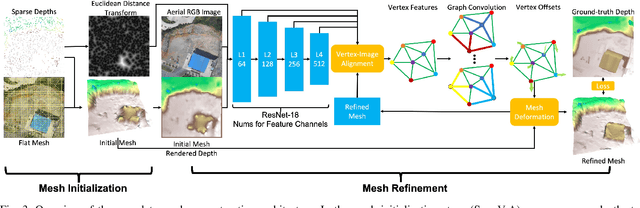
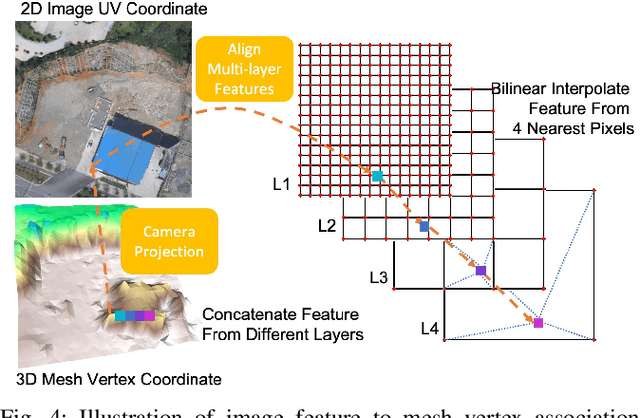
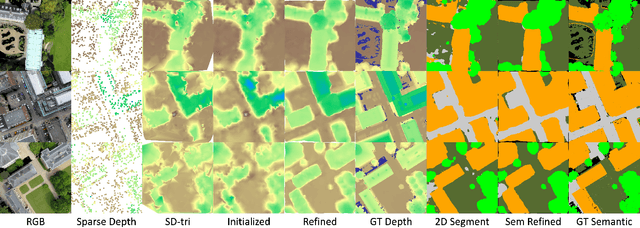
This paper addresses outdoor terrain mapping using overhead images obtained from an unmanned aerial vehicle. Dense depth estimation from aerial images during flight is challenging. While feature-based localization and mapping techniques can deliver real-time odometry and sparse points reconstruction, a dense environment model is generally recovered offline with significant computation and storage. This paper develops a joint 2D-3D learning approach to reconstruct local meshes at each camera keyframe, which can be assembled into a global environment model. Each local mesh is initialized from sparse depth measurements. We associate image features with the mesh vertices through camera projection and apply graph convolution to refine the mesh vertices based on joint 2-D reprojected depth and 3-D mesh supervision. Quantitative and qualitative evaluations using real aerial images show the potential of our method to support environmental monitoring and surveillance applications.
OrcVIO: Object residual constrained Visual-Inertial Odometry
Jul 29, 2020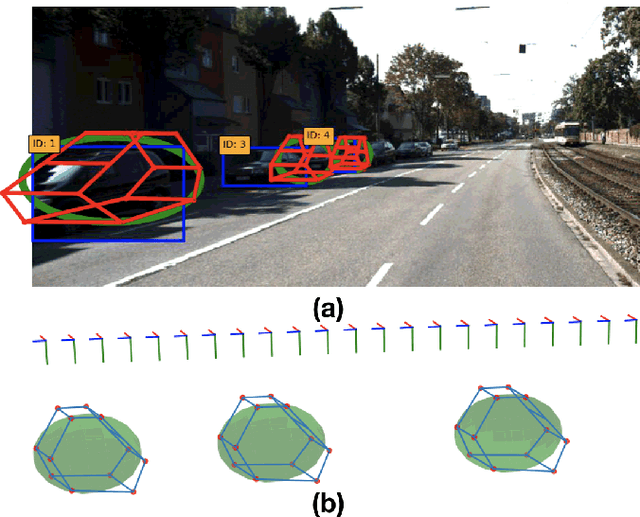
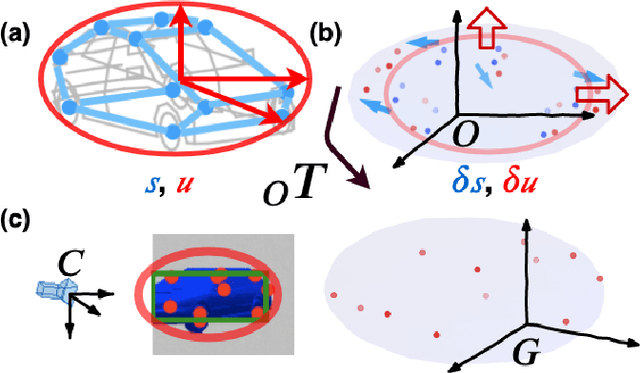
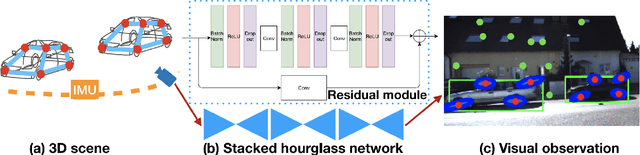
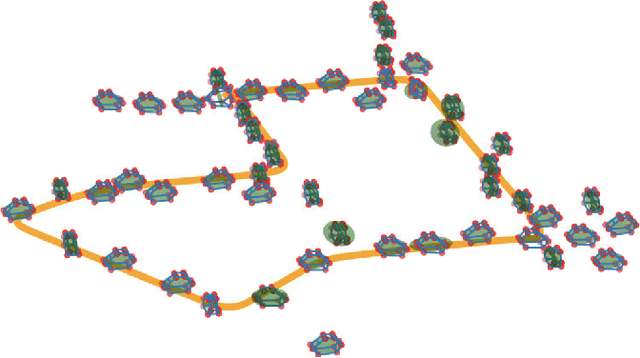
Introducing object-level semantic information into simultaneous localization and mapping (SLAM) system is critical. It not only improves the performance but also enables tasks specified in terms of meaningful objects. This work presents OrcVIO, for visual-inertial odometry tightly coupled with tracking and optimization over structured object models. OrcVIO differentiates through semantic feature and bounding-box reprojection errors to perform batch optimization over the pose and shape of objects. The estimated object states aid in real-time incremental optimization over the IMU-camera states. The ability of OrcVIO for accurate trajectory estimation and large-scale object-level mapping is evaluated using real data.
Constructing Effective Personalized Policies Using Counterfactual Inference from Biased Data Sets with Many Features
Jul 10, 2018
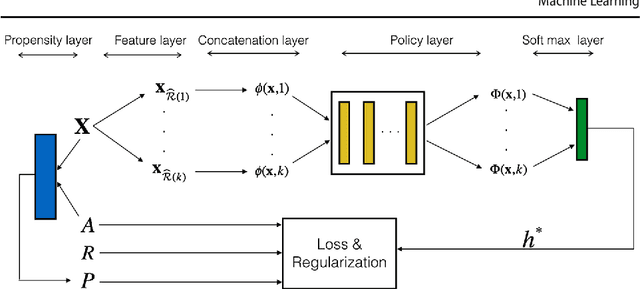

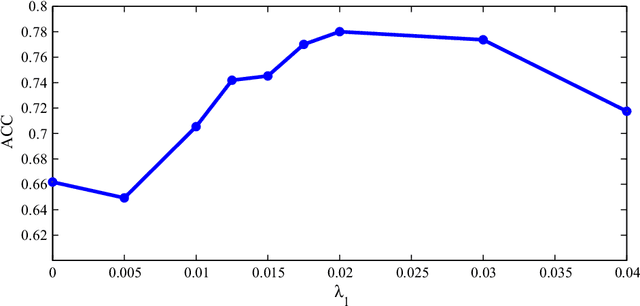
This paper proposes a novel approach for constructing effective personalized policies when the observed data lacks counter-factual information, is biased and possesses many features. The approach is applicable in a wide variety of settings from healthcare to advertising to education to finance. These settings have in common that the decision maker can observe, for each previous instance, an array of features of the instance, the action taken in that instance, and the reward realized -- but not the rewards of actions that were not taken: the counterfactual information. Learning in such settings is made even more difficult because the observed data is typically biased by the existing policy (that generated the data) and because the array of features that might affect the reward in a particular instance -- and hence should be taken into account in deciding on an action in each particular instance -- is often vast. The approach presented here estimates propensity scores for the observed data, infers counterfactuals, identifies a (relatively small) number of features that are (most) relevant for each possible action and instance, and prescribes a policy to be followed. Comparison of the proposed algorithm against the state-of-art algorithm on actual datasets demonstrates that the proposed algorithm achieves a significant improvement in performance.