 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELLIPSDF: Joint Object Pose and Shape Optimization with a Bi-level Ellipsoid and Signed Distance Function Description
Aug 01, 2021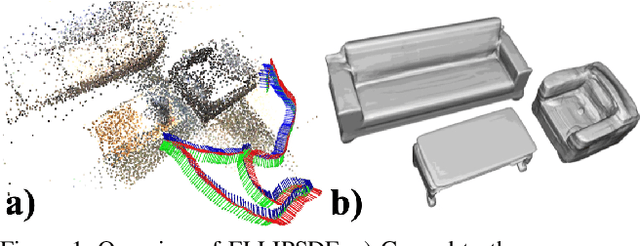
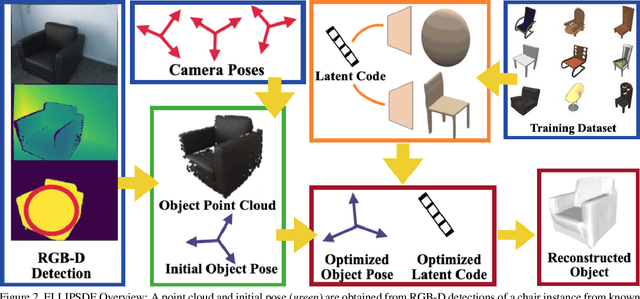
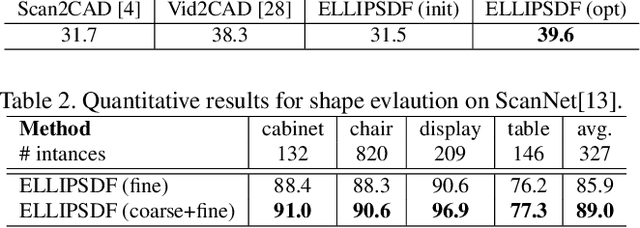
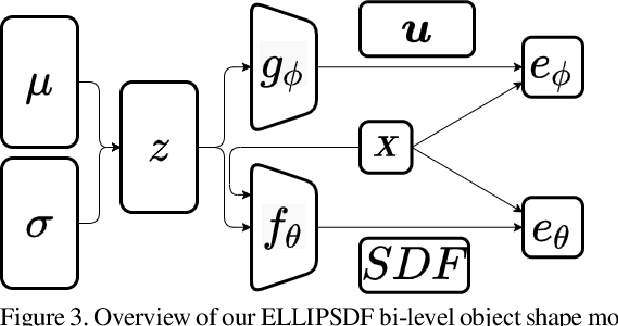
Autonomous systems need to understand the semantics and geometry of their surroundings in order to comprehend and safely execute object-level task specifications. This paper proposes an expressive yet compact model for joint object pose and shape optimization, and an associated optimization algorithm to infer an object-level map from multi-view RGB-D camera observations. The model is expressive because it captures the identities, positions, orientations, and shapes of objects in the environment. It is compact because it relies on a low-dimensional latent representation of implicit object shape, allowing onboard storage of large multi-category object maps. Different from other works that rely on a single object representation format, our approach has a bi-level object model that captures both the coarse level scale as well as the fine level shape details. Our approach is evaluated on the large-scale real-world ScanNet dataset and compared against state-of-the-art methods.
Localization and Mapping using Instance-specific Mesh Models
Mar 08, 2021
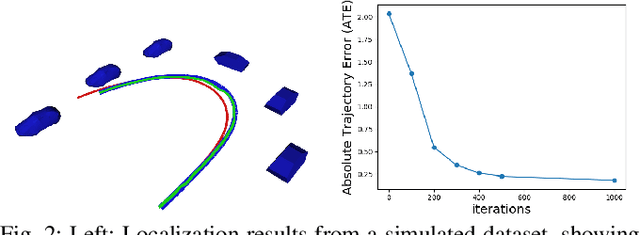
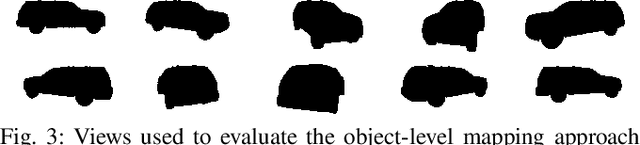
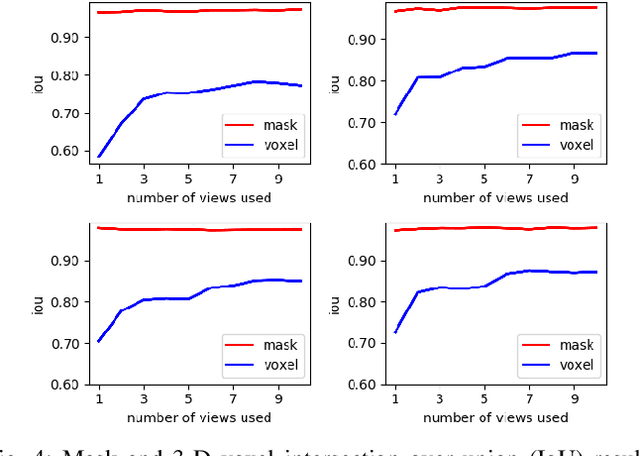
This paper focuses on building semantic maps, containing object poses and shapes, using a monocular camera. This is an important problem because robots need rich understanding of geometry and context if they are to shape the future of transportation, construction, and agriculture. Our contribution is an instance-specific mesh model of object shape that can be optimized online based on semantic information extracted from camera images. Multi-view constraints on the object shape are obtained by detecting objects and extracting category-specific keypoints and segmentation masks. We show that the errors between projections of the mesh model and the observed keypoints and masks can be differentiated in order to obtain accurate instance-specific object shapes. We evaluate the performance of the proposed approach in simulation and on the KITTI dataset by building maps of car poses and shapes.
* 8 pages, 9 figures
OrcVIO: Object residual constrained Visual-Inertial Odometry
Jul 29, 2020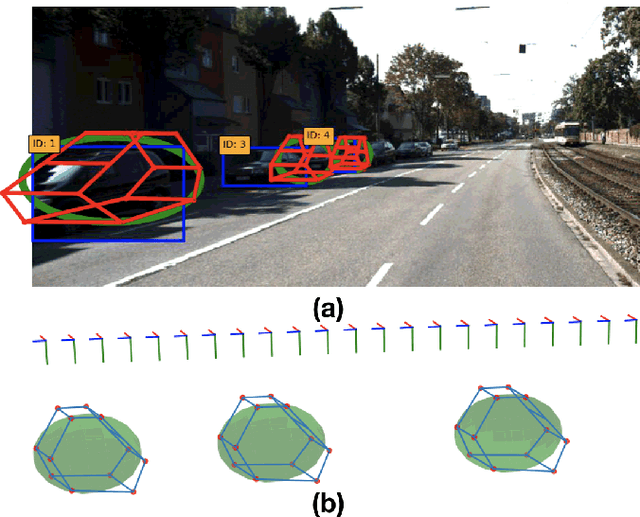
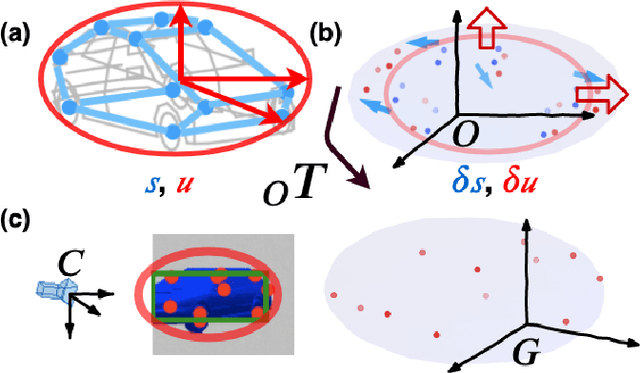
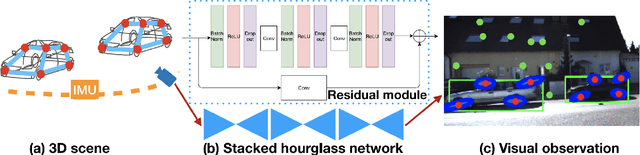
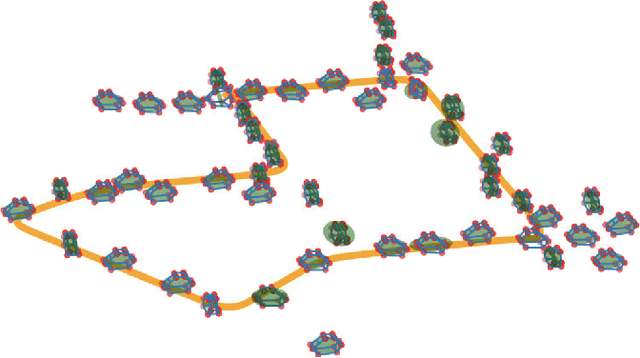
Introducing object-level semantic information into simultaneous localization and mapping (SLAM) system is critical. It not only improves the performance but also enables tasks specified in terms of meaningful objects. This work presents OrcVIO, for visual-inertial odometry tightly coupled with tracking and optimization over structured object models. OrcVIO differentiates through semantic feature and bounding-box reprojection errors to perform batch optimization over the pose and shape of objects. The estimated object states aid in real-time incremental optimization over the IMU-camera states. The ability of OrcVIO for accurate trajectory estimation and large-scale object-level mapping is evaluated using real data.
A spatiotemporal model with visual attention for video classification
Jul 24, 2017



High level understanding of sequential visual input is important for safe and stable autonomy, especially in localization and object detection. While traditional object classification and tracking approaches are specifically designed to handle variations in rotation and scale, current state-of-the-art approaches based on deep learning achieve better performance. This paper focuses on developing a spatiotemporal model to handle videos containing moving objects with rotation and scale changes. Built on models that combine Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) to classify sequential data, this work investigates the effectiveness of incorporating attention modules in the CNN stage for video classification. The superiority of the proposed spatiotemporal model is demonstrated on the Moving MNIST dataset augmented with rotation and scaling.
Google Map Aided Visual Navigation for UAVs in GPS-denied Environment
Mar 29, 2017

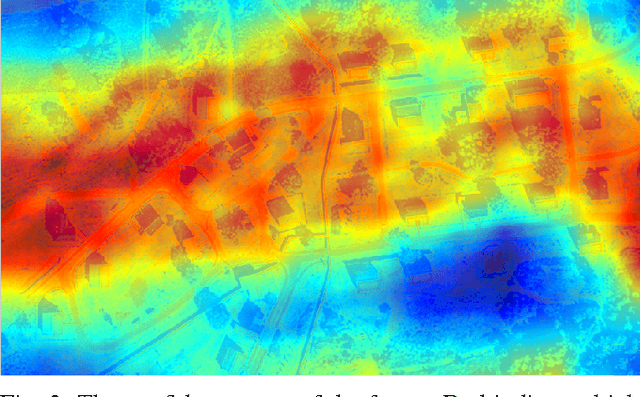

We propose a framework for Google Map aided UAV navigation in GPS-denied environment. Geo-referenced navigation provides drift-free localization and does not require loop closures. The UAV position is initialized via correlation, which is simple and efficient. We then use optical flow to predict its position in subsequent frames. During pose tracking, we obtain inter-frame translation either by motion field or homography decomposition, and we use HOG features for registration on Google Map. We employ particle filter to conduct a coarse to fine search to localize the UAV. Offline test using aerial images collected by our quadrotor platform shows promising results as our approach eliminates the drift in dead-reckoning, and the small localization error indicates the superiority of our approach as a supplement to GPS.