 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho State Neural Machine Translation
Feb 27, 2020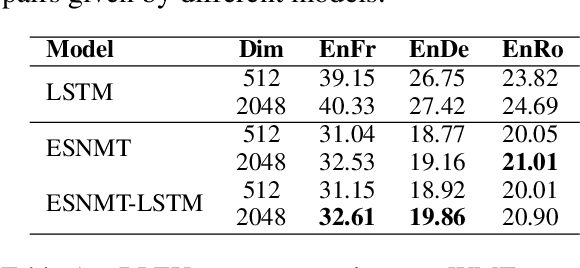
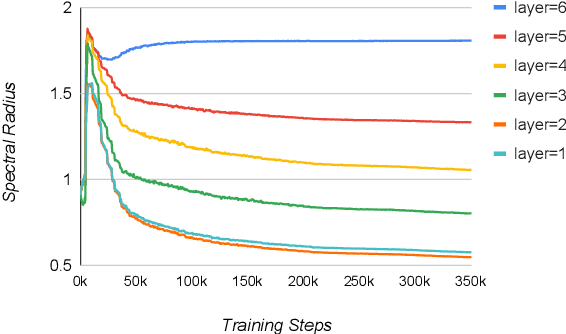

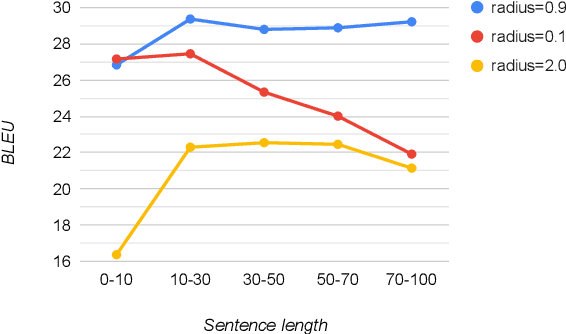
We present neural machine translation (NMT) models inspired by echo state network (ESN), named Echo State NMT (ESNMT), in which the encoder and decoder layer weights are randomly generated then fixed throughout training. We show that even with this extremely simple model construction and training procedure, ESNMT can already reach 70-80% quality of fully trainable baselines. We examine how spectral radius of the reservoir, a key quantity that characterizes the model, determines the model behavior. Our findings indicate that randomized networks can work well even for complicated sequence-to-sequence prediction NLP tasks.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019
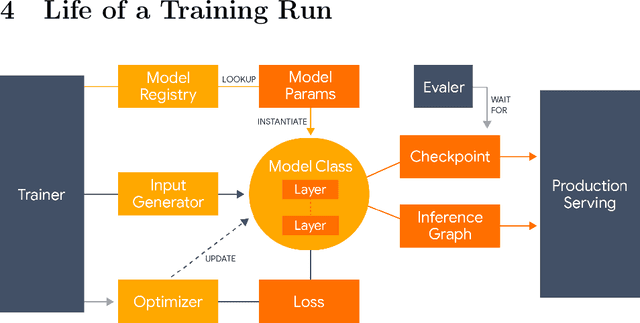
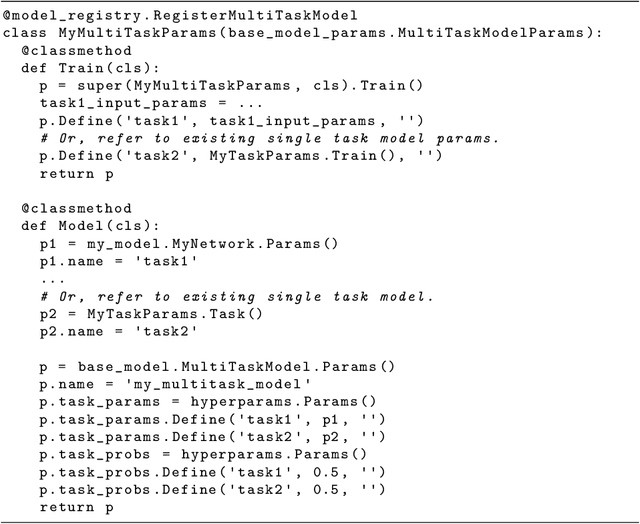
Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
Mar 04, 2014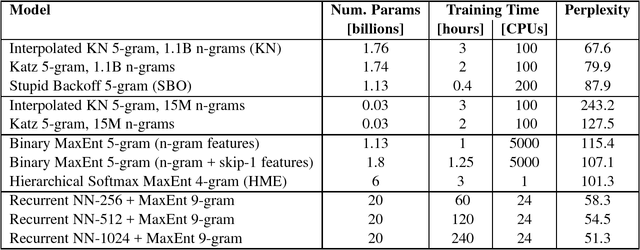

We propose a new benchmark corpus to be used for measuring progress in statistical language modeling. With almost one billion words of training data, we hope this benchmark will be useful to quickly evaluate novel language modeling techniques, and to compare their contribution when combined with other advanced techniques. We show performance of several well-known types of language models, with the best results achieved with a recurrent neural network based language model. The baseline unpruned Kneser-Ney 5-gram model achieves perplexity 67.6; a combination of techniques leads to 35% reduction in perplexity, or 10% reduction in cross-entropy (bits), over that baseline. The benchmark is available as a code.google.com project; besides the scripts needed to rebuild the training/held-out data, it also makes available log-probability values for each word in each of ten held-out data sets, for each of the baseline n-gram models.