 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
Mar 04, 2014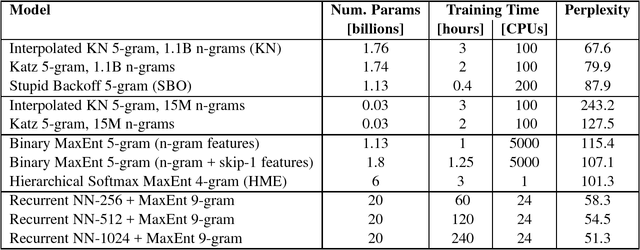

We propose a new benchmark corpus to be used for measuring progress in statistical language modeling. With almost one billion words of training data, we hope this benchmark will be useful to quickly evaluate novel language modeling techniques, and to compare their contribution when combined with other advanced techniques. We show performance of several well-known types of language models, with the best results achieved with a recurrent neural network based language model. The baseline unpruned Kneser-Ney 5-gram model achieves perplexity 67.6; a combination of techniques leads to 35% reduction in perplexity, or 10% reduction in cross-entropy (bits), over that baseline. The benchmark is available as a code.google.com project; besides the scripts needed to rebuild the training/held-out data, it also makes available log-probability values for each word in each of ten held-out data sets, for each of the baseline n-gram models.
TnT - A Statistical Part-of-Speech Tagger
Mar 13, 2000



Trigrams'n'Tags (TnT) is an efficient statistical part-of-speech tagger. Contrary to claims found elsewhere in the literature, we argue that a tagger based on Markov models performs at least as well as other current approaches, including the Maximum Entropy framework. A recent comparison has even shown that TnT performs significantly better for the tested corpora. We describe the basic model of TnT, the techniques used for smoothing and for handling unknown words. Furthermore, we present evaluations on two corpora.
* 8 pages
Cascaded Markov Models
Jun 06, 1999
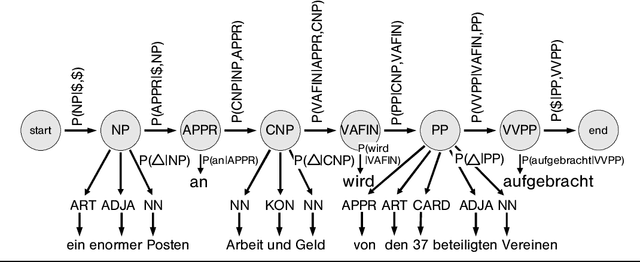


This paper presents a new approach to partial parsing of context-free structures. The approach is based on Markov Models. Each layer of the resulting structure is represented by its own Markov Model, and output of a lower layer is passed as input to the next higher layer. An empirical evaluation of the method yields very good results for NP/PP chunking of German newspaper texts.
* 8 pages
A Linguistically Interpreted Corpus of German Newspaper Text
Jul 17, 1998
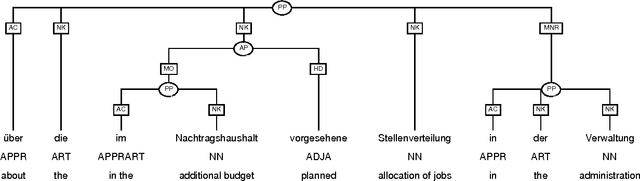
In this paper, we report on the development of an annotation scheme and annotation tools for unrestricted German text. Our representation format is based on argument structure, but also permits the extraction of other kinds of representations. We discuss several methodological issues and the analysis of some phenomena. Additional focus is on the tools developed in our project and their applications.
Chunk Tagger - Statistical Recognition of Noun Phrases
Jul 17, 1998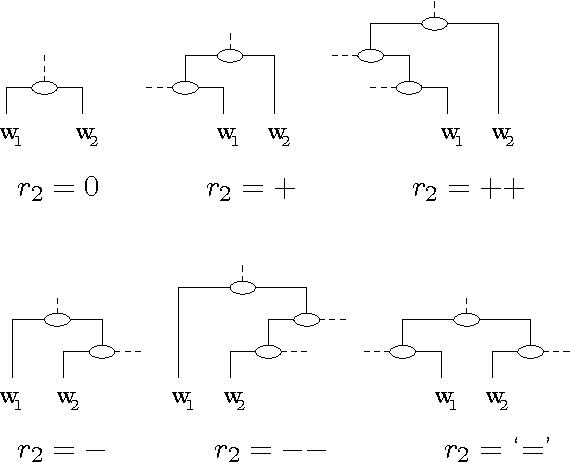

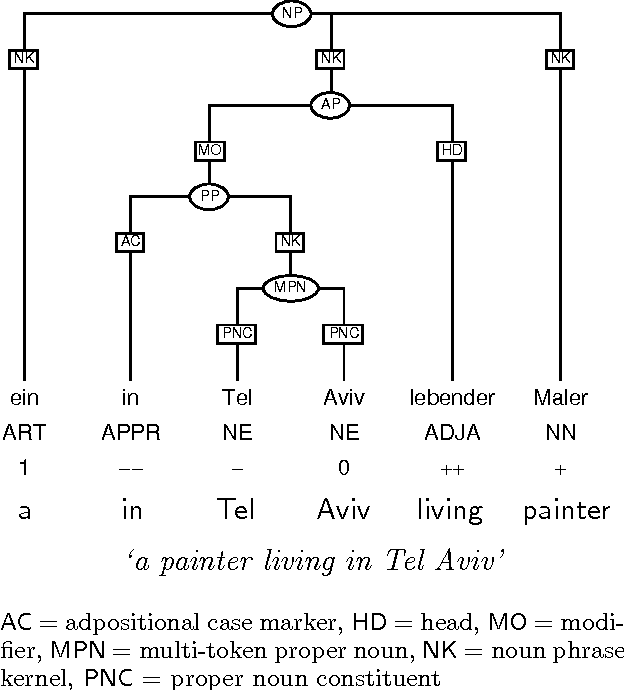

We describe a stochastic approach to partial parsing, i.e., the recognition of syntactic structures of limited depth. The technique utilises Markov Models, but goes beyond usual bracketing approaches, since it is capable of recognising not only the boundaries, but also the internal structure and syntactic category of simple as well as complex NP's, PP's, AP's and adverbials. We compare tagging accuracy for different applications and encoding schemes.
A Maximum-Entropy Partial Parser for Unrestricted Text
Jul 17, 1998
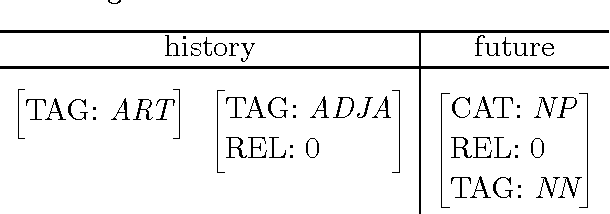
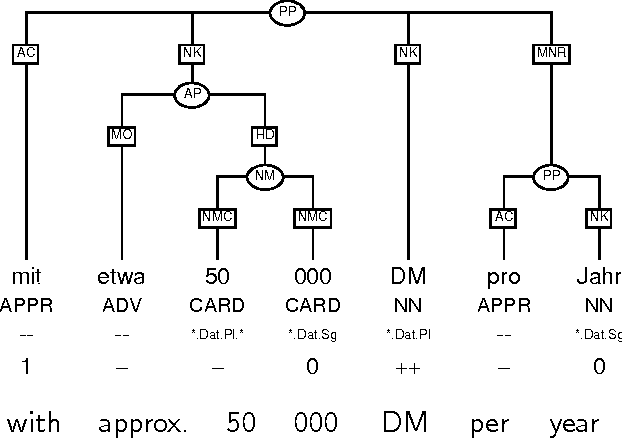
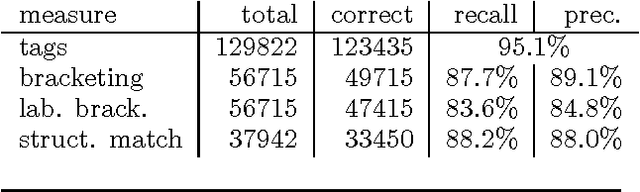
This paper describes a partial parser that assigns syntactic structures to sequences of part-of-speech tags. The program uses the maximum entropy parameter estimation method, which allows a flexible combination of different knowledge sources: the hierarchical structure, parts of speech and phrasal categories. In effect, the parser goes beyond simple bracketing and recognises even fairly complex structures. We give accuracy figures for different applications of the parser.
Tagging Grammatical Functions
Jul 23, 1997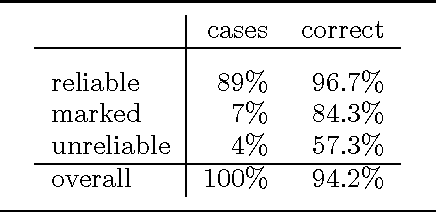
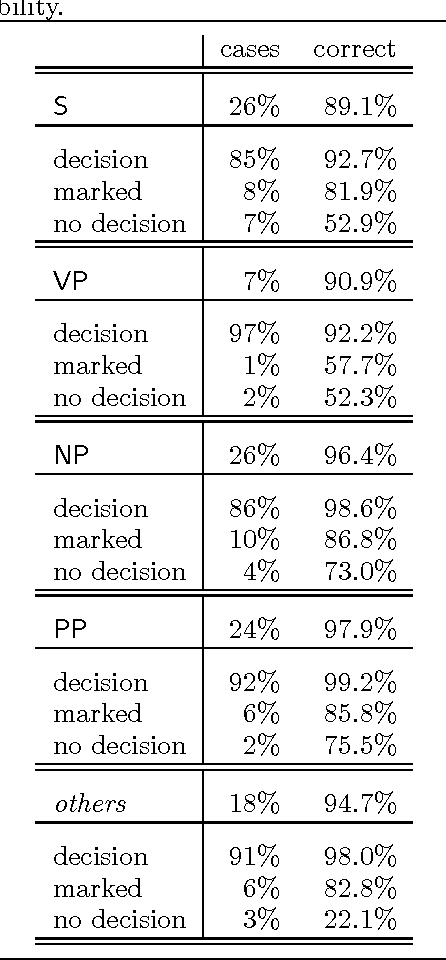
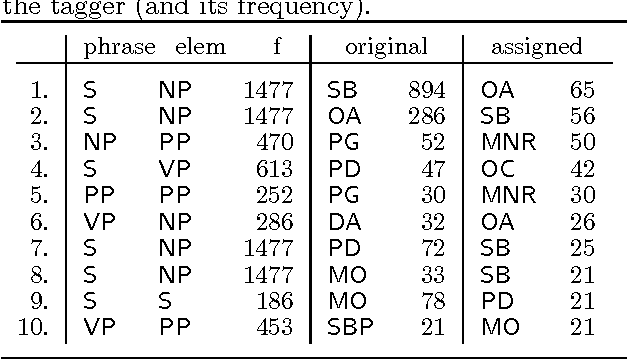
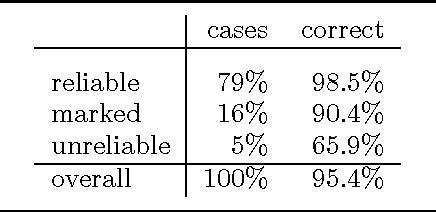
This paper addresses issues in automated treebank construction. We show how standard part-of-speech tagging techniques extend to the more general problem of structural annotation, especially for determining grammatical functions and syntactic categories. Annotation is viewed as an interactive process where manual and automatic processing alternate. Efficiency and accuracy results are presented. We also discuss further automation steps.
An Annotation Scheme for Free Word Order Languages
Feb 10, 1997
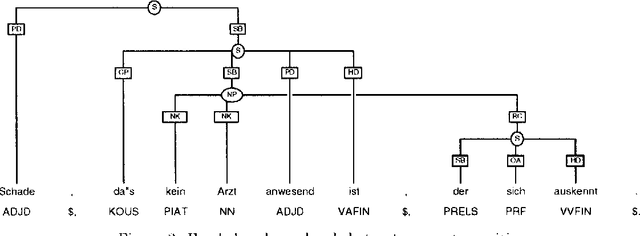
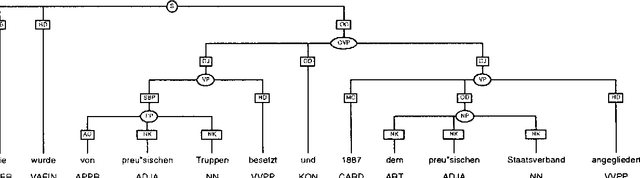
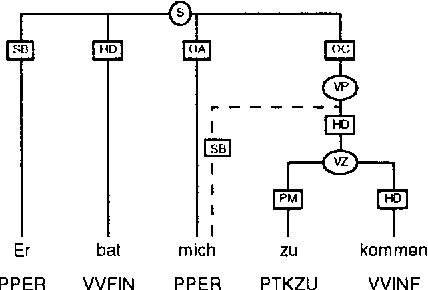
We describe an annotation scheme and a tool developed for creating linguistically annotated corpora for non-configurational languages. Since the requirements for such a formalism differ from those posited for configurational languages, several features have been added, influencing the architecture of the scheme. The resulting scheme reflects a stratificational notion of language, and makes only minimal assumptions about the interrelation of the particular representational strata.
Better Language Models with Model Merging
Apr 17, 1996


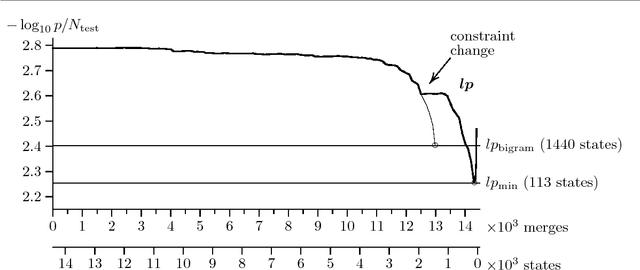
This paper investigates model merging, a technique for deriving Markov models from text or speech corpora. Models are derived by starting with a large and specific model and by successively combining states to build smaller and more general models. We present methods to reduce the time complexity of the algorithm and report on experiments on deriving language models for a speech recognition task. The experiments show the advantage of model merging over the standard bigram approach. The merged model assigns a lower perplexity to the test set and uses considerably fewer states.
Tagging the Teleman Corpus
May 11, 1995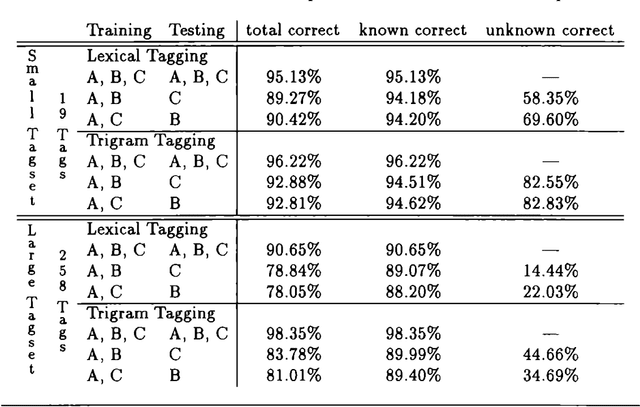

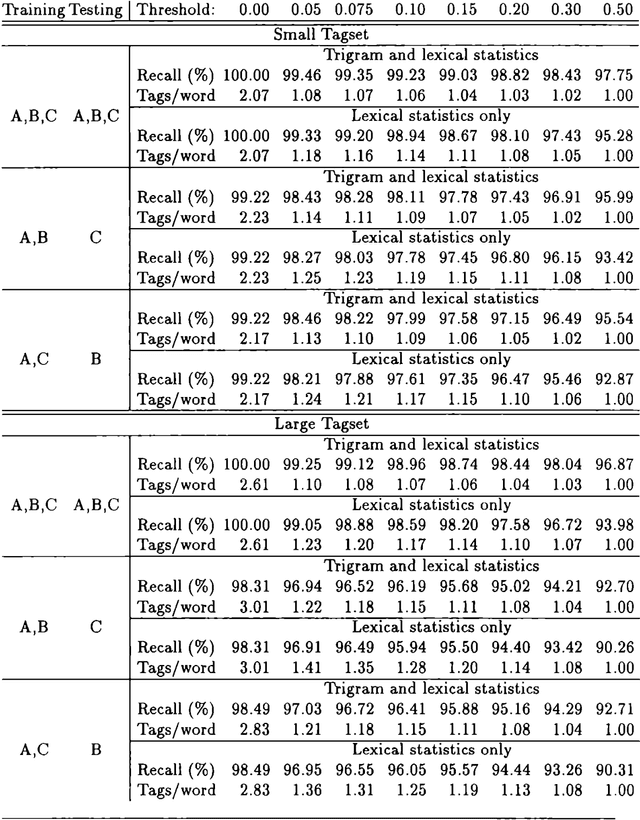
Experiments were carried out comparing the Swedish Teleman and the English Susanne corpora using an HMM-based and a novel reductionistic statistical part-of-speech tagger. They indicate that tagging the Teleman corpus is the more difficult task, and that the performance of the two different taggers is comparable.