Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagging the Teleman Corpus
Paper and Code
May 11, 1995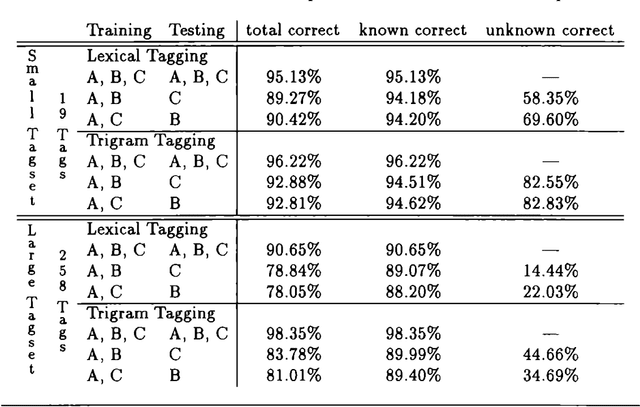

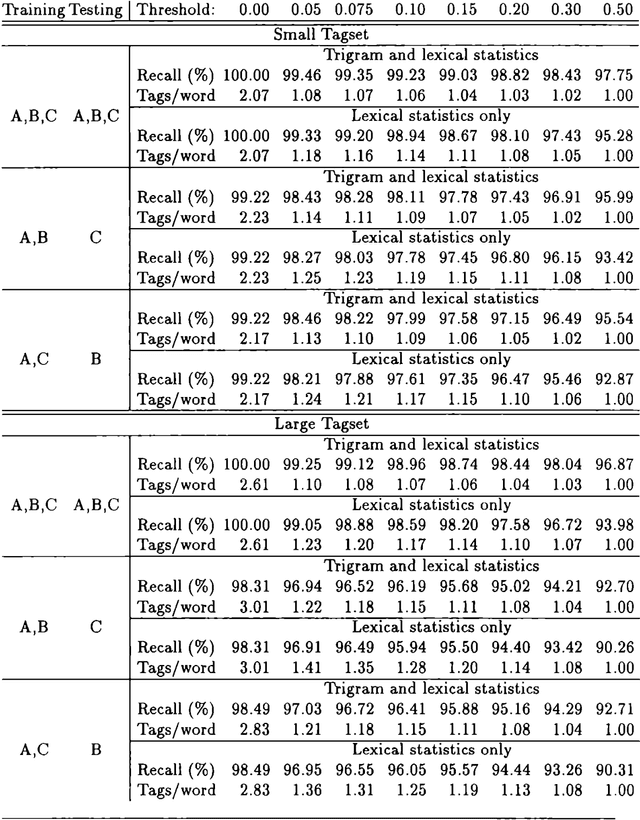
Experiments were carried out comparing the Swedish Teleman and the English Susanne corpora using an HMM-based and a novel reductionistic statistical part-of-speech tagger. They indicate that tagging the Teleman corpus is the more difficult task, and that the performance of the two different taggers is comparable.
* 14 pages, LaTeX, to appear in Proceedings of the 10th Nordic
Conference of Computational Linguistics, Helsinki, Finland, 1995
View paper on