 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing a Linguistic and a Stochastic Tagger
Jun 07, 1997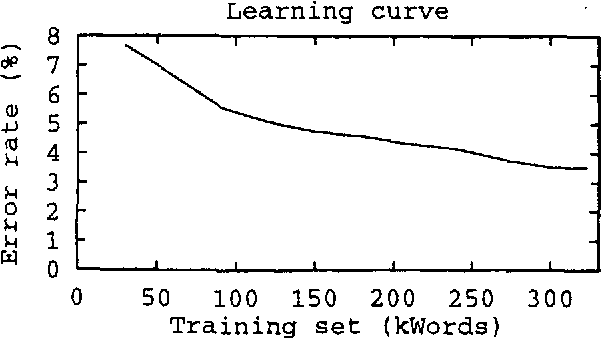
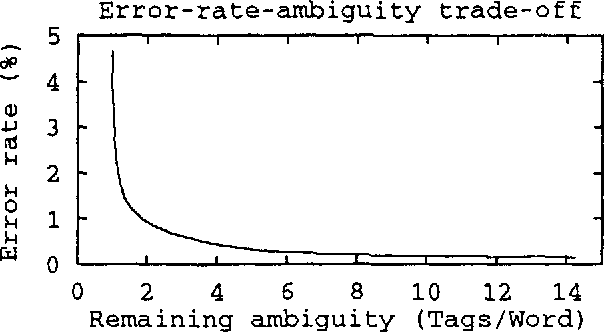
Concerning different approaches to automatic PoS tagging: EngCG-2, a constraint-based morphological tagger, is compared in a double-blind test with a state-of-the-art statistical tagger on a common disambiguation task using a common tag set. The experiments show that for the same amount of remaining ambiguity, the error rate of the statistical tagger is one order of magnitude greater than that of the rule-based one. The two related issues of priming effects compromising the results and disagreement between human annotators are also addressed.
Inducing Constraint Grammars
Jul 01, 1996Constraint Grammar rules are induced from corpora. A simple scheme based on local information, i.e., on lexical biases and next-neighbour contexts, extended through the use of barriers, reached 87.3 percent precision (1.12 tags/word) at 98.2 percent recall. The results compare favourably with other methods that are used for similar tasks although they are by no means as good as the results achieved using the original hand-written rules developed over several years time.
* 10 pages, uuencoded, gzipped PostScript
Relating Turing's Formula and Zipf's Law
Jun 21, 1996An asymptote is derived from Turing's local reestimation formula for population frequencies, and a local reestimation formula is derived from Zipf's law for the asymptotic behavior of population frequencies. The two are shown to be qualitatively different asymptotically, but nevertheless to be instances of a common class of reestimation-formula-asymptote pairs, in which they constitute the upper and lower bounds of the convergence region of the cumulative of the frequency function, as rank tends to infinity. The results demonstrate that Turing's formula is qualitatively different from the various extensions to Zipf's law, and suggest that it smooths the frequency estimates towards a geometric distribution.
* 9 pages, uuencoded, gzipped PostScript; some typos removed
Handling Sparse Data by Successive Abstraction
May 29, 1996A general, practical method for handling sparse data that avoids held-out data and iterative reestimation is derived from first principles. It has been tested on a part-of-speech tagging task and outperformed (deleted) interpolation with context-independent weights, even when the latter used a globally optimal parameter setting determined a posteriori.
* 6 pages, uuencoded, gzipped PostScript
Example-Based Optimization of Surface-Generation Tables
May 29, 1996A method is given that "inverts" a logic grammar and displays it from the point of view of the logical form, rather than from that of the word string. LR-compiling techniques are used to allow a recursive-descent generation algorithm to perform "functor merging" much in the same way as an LR parser performs prefix merging. This is an improvement on the semantic-head-driven generator that results in a much smaller search space. The amount of semantic lookahead can be varied, and appropriate tradeoff points between table size and resulting nondeterminism can be found automatically. This can be done by removing all spurious nondeterminism for input sufficiently close to the examples of a training corpus, and large portions of it for other input, while preserving completeness.
* 22 pages, uuencoded, gzipped PostScript
Notes on LR Parser Design
May 29, 1996The design of an LR parser based on interleaving the atomic symbol processing of a context-free backbone grammar with the full constraints of the underlying unification grammar is described. The parser employs a set of reduced constraints derived from the unification grammar in the LR parsing step. Gap threading is simulated to reduce the applicability of empty productions.
* 5 pages, uuncoded, gzipped PostScript
An Efficient Algorithm for Surface Generation
Jul 21, 1995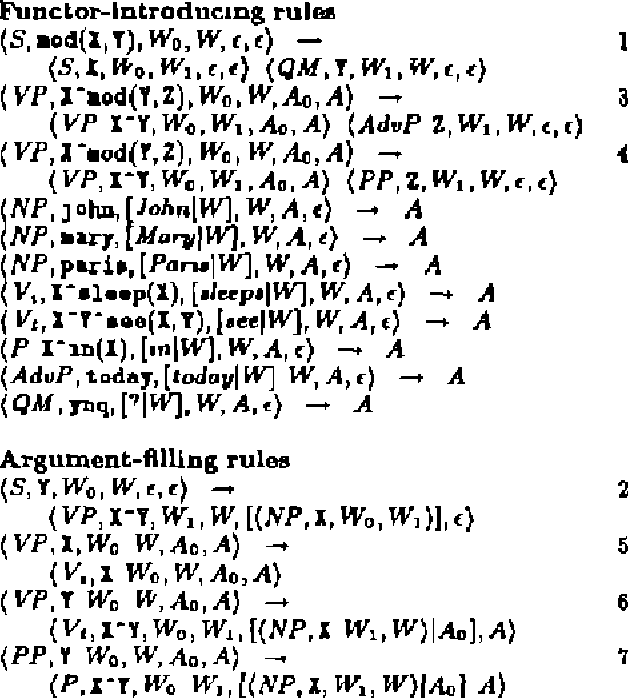
A method is given that "inverts" a logic grammar and displays it from the point of view of the logical form, rather than from that of the word string. LR-compiling techniques are used to allow a recursive-descent generation algorithm to perform "functor merging" much in the same way as an LR parser performs prefix merging. This is an improvement on the semantic-head-driven generator that results in a much smaller search space. The amount of semantic lookahead can be varied, and appropriate tradeoff points between table size and resulting nondeterminism can be found automatically.
* Uuencoded compressed PostScript format
Tagging the Teleman Corpus
May 11, 1995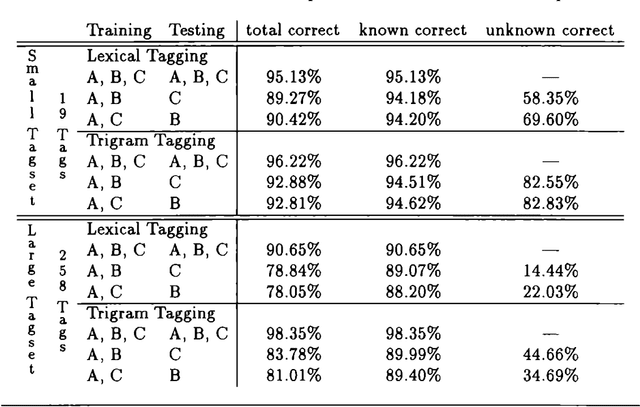

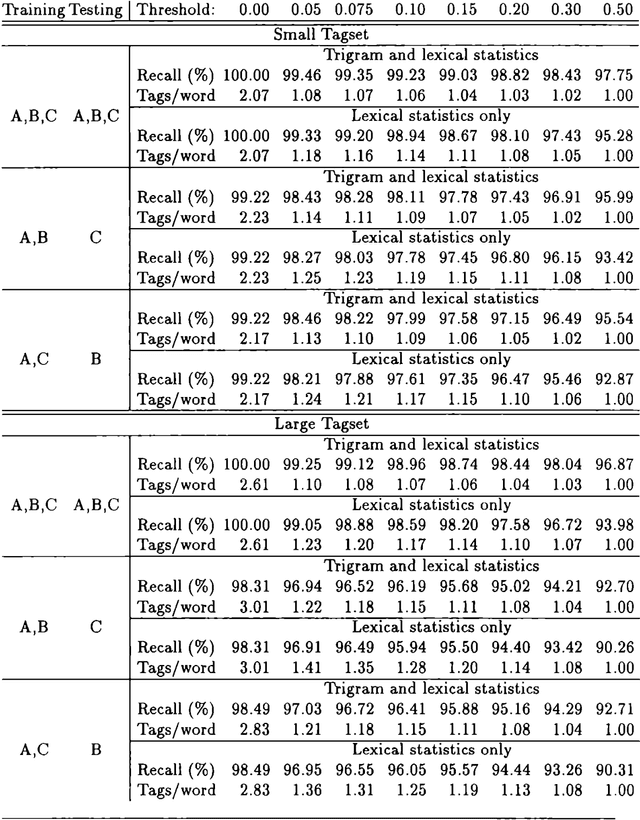
Experiments were carried out comparing the Swedish Teleman and the English Susanne corpora using an HMM-based and a novel reductionistic statistical part-of-speech tagger. They indicate that tagging the Teleman corpus is the more difficult task, and that the performance of the two different taggers is comparable.
Grammar Specialization through Entropy Thresholds
May 25, 1994
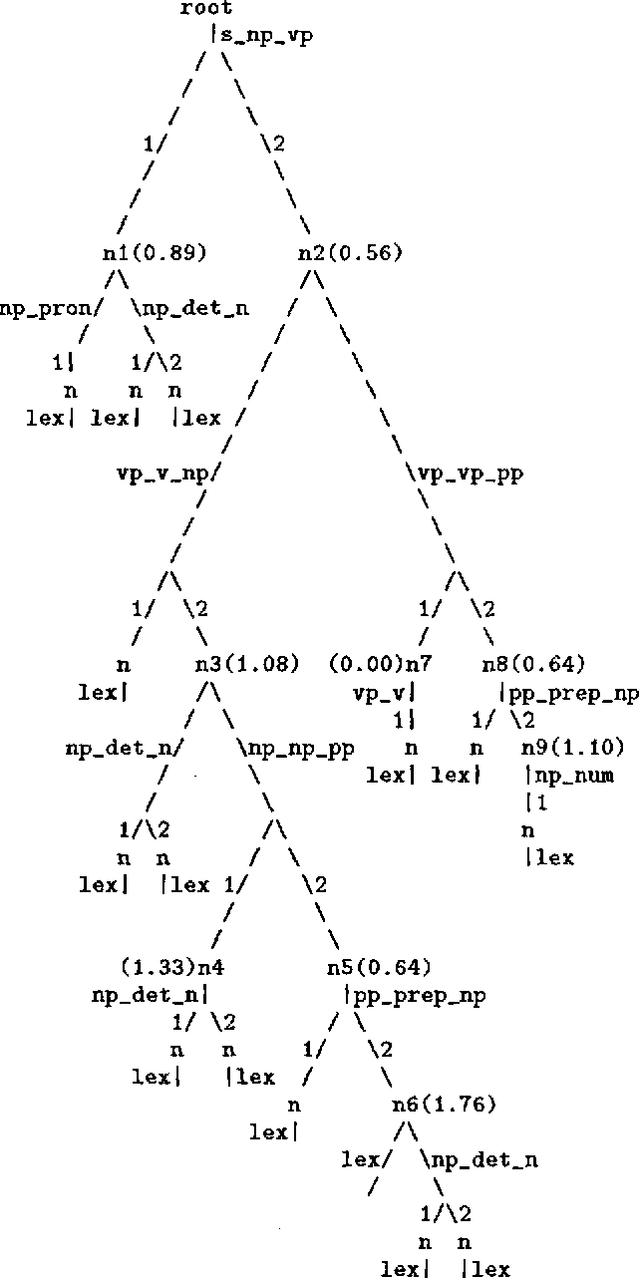

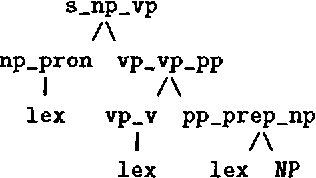
Explanation-based generalization is used to extract a specialized grammar from the original one using a training corpus of parse trees. This allows very much faster parsing and gives a lower error rate, at the price of a small loss in coverage. Previously, it has been necessary to specify the tree-cutting criteria (or operationality criteria) manually; here they are derived automatically from the training set and the desired coverage of the specialized grammar. This is done by assigning an entropy value to each node in the parse trees and cutting in the nodes with sufficiently high entropy values.
* 8 pages