 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing a Linguistic and a Stochastic Tagger
Jun 07, 1997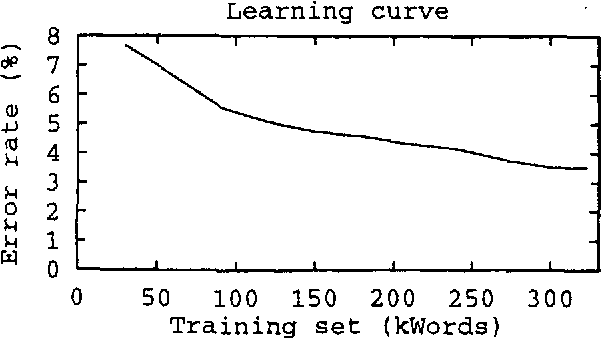
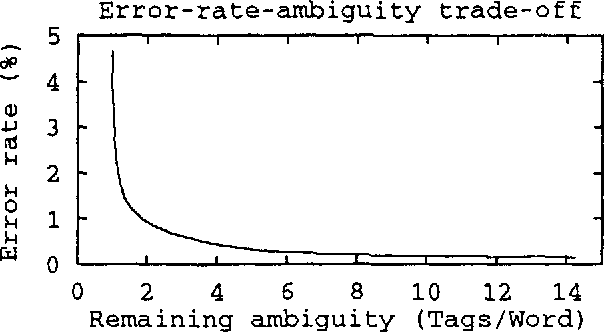
Concerning different approaches to automatic PoS tagging: EngCG-2, a constraint-based morphological tagger, is compared in a double-blind test with a state-of-the-art statistical tagger on a common disambiguation task using a common tag set. The experiments show that for the same amount of remaining ambiguity, the error rate of the statistical tagger is one order of magnitude greater than that of the rule-based one. The two related issues of priming effects compromising the results and disagreement between human annotators are also addressed.
Developing a hybrid NP parser
Apr 24, 1997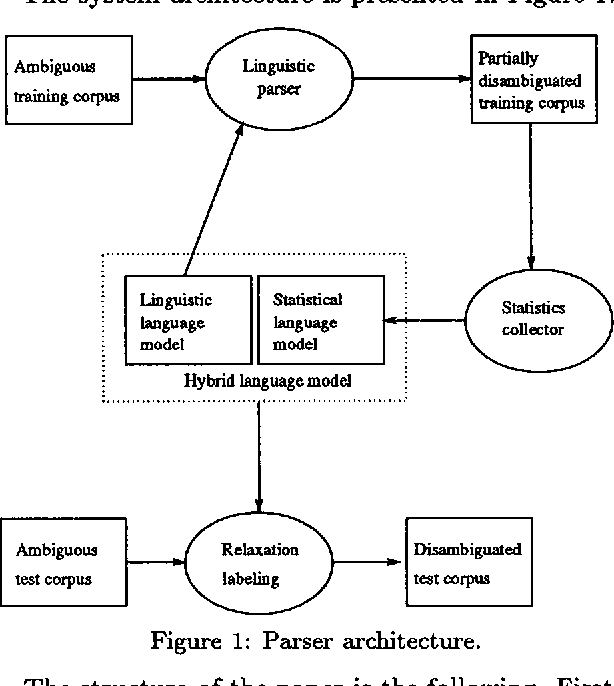

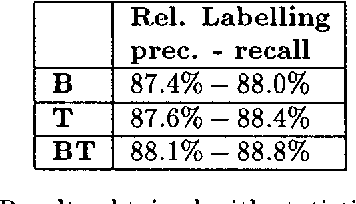
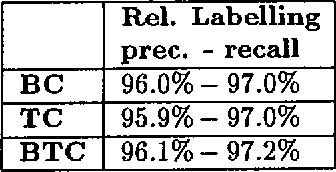
We describe the use of energy function optimization in very shallow syntactic parsing. The approach can use linguistic rules and corpus-based statistics, so the strengths of both linguistic and statistical approaches to NLP can be combined in a single framework. The rules are contextual constraints for resolving syntactic ambiguities expressed as alternative tags, and the statistical language model consists of corpus-based n-grams of syntactic tags. The success of the hybrid syntactic disambiguator is evaluated against a held-out benchmark corpus. Also the contributions of the linguistic and statistical language models to the hybrid model are estimated.
* 8 pages, uses aclap.sty, epsf.sty
Inducing Constraint Grammars
Jul 01, 1996Constraint Grammar rules are induced from corpora. A simple scheme based on local information, i.e., on lexical biases and next-neighbour contexts, extended through the use of barriers, reached 87.3 percent precision (1.12 tags/word) at 98.2 percent recall. The results compare favourably with other methods that are used for similar tasks although they are by no means as good as the results achieved using the original hand-written rules developed over several years time.
* 10 pages, uuencoded, gzipped PostScript
A syntax-based part-of-speech analyser
Feb 14, 1995
There are two main methodologies for constructing the knowledge base of a natural language analyser: the linguistic and the data-driven. Recent state-of-the-art part-of-speech taggers are based on the data-driven approach. Because of the known feasibility of the linguistic rule-based approach at related levels of description, the success of the data-driven approach in part-of-speech analysis may appear surprising. In this paper, a case is made for the syntactic nature of part-of-speech tagging. A new tagger of English that uses only linguistic distributional rules is outlined and empirically evaluated. Tested against a benchmark corpus of 38,000 words of previously unseen text, this syntax-based system reaches an accuracy of above 99%. Compared to the 95-97% accuracy of its best competitors, this result suggests the feasibility of the linguistic approach also in part-of-speech analysis.
Ambiguity resolution in a reductionistic parser
Feb 13, 1995
We are concerned with dependency-oriented morphosyntactic parsing of running text. While a parsing grammar should avoid introducing structurally unresolvable distinctions in order to optimise on the accuracy of the parser, it also is beneficial for the grammarian to have as expressive a structural representation available as possible. In a reductionistic parsing system this policy may result in considerable ambiguity in the input; however, even massive ambiguity can be tackled efficiently with an accurate parsing description and effective parsing technology.
Specifying a shallow grammatical representation for parsing purposes
Feb 13, 1995
Is it possible to specify a grammatical representation (descriptors and their application guidelines) to such a degree that it can be consistently applied by different grammarians e.g. for producing a benchmark corpus for parser evaluation? Arguments for and against have been given, but very little empirical evidence. In this article we report on a double-blind experiment with a surface-oriented morphosyntactic grammatical representation used in a large-scale English parser. We argue that a consistently applicable representation for morphology and also shallow syntax can be specified. A grammatical representation with a near-100% coverage of running text can be specified with a reasonable effort, especially if the representation is based on structural distinctions (i.e. it is structurally resolvable).
NPtool, a detector of English noun phrases
Feb 13, 1995
NPtool is a fast and accurate system for extracting noun phrases from English texts for the purposes of e.g. information retrieval, translation unit discovery, and corpus studies. After a general introduction, the system architecture is presented in outline. Then follows an examination of a recently written Constraint Syntax. An evaluation report concludes the paper.
Tagging accurately -- Don't guess if you know
Aug 16, 1994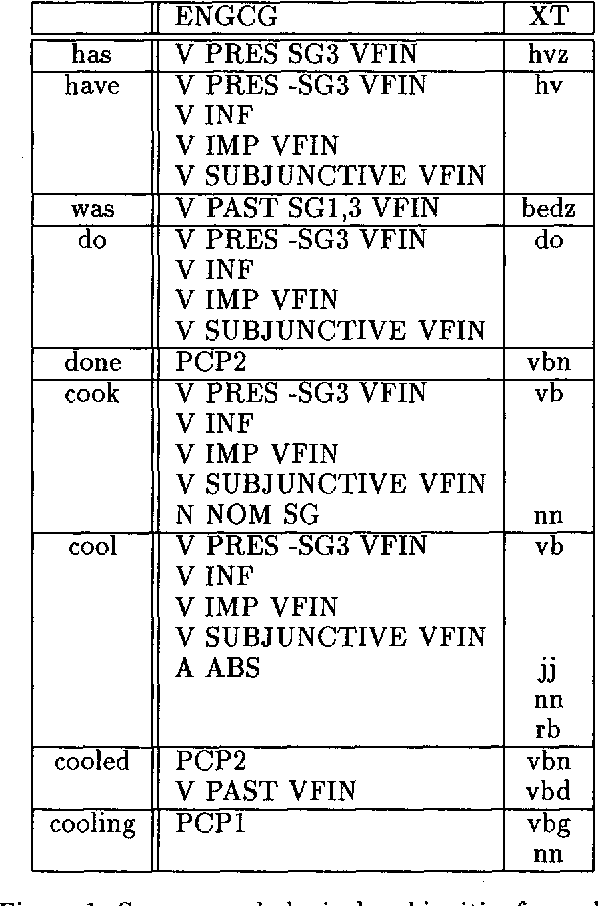
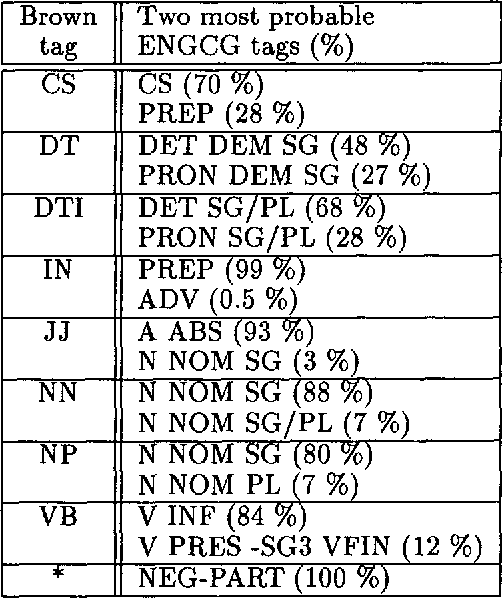
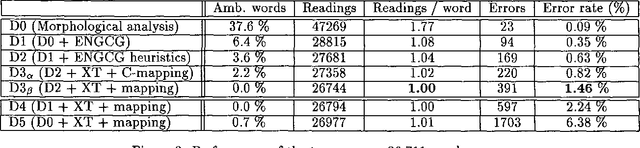
We discuss combining knowledge-based (or rule-based) and statistical part-of-speech taggers. We use two mature taggers, ENGCG and Xerox Tagger, to independently tag the same text and combine the results to produce a fully disambiguated text. In a 27000 word test sample taken from a previously unseen corpus we achieve 98.5% accuracy. This paper presents the data in detail. We describe the problems we encountered in the course of combining the two taggers and discuss the problem of evaluating taggers.
Three studies of grammar-based surface-syntactic parsing of unrestricted English text. A summary and orientation
Jun 27, 1994The dissertation addresses the design of parsing grammars for automatic surface-syntactic analysis of unconstrained English text. It consists of a summary and three articles. {\it Morphological disambiguation} documents a grammar for morphological (or part-of-speech) disambiguation of English, done within the Constraint Grammar framework proposed by Fred Karlsson. The disambiguator seeks to discard those of the alternative morphological analyses proposed by the lexical analyser that are contextually illegitimate. The 1,100 constraints express some 23 general, essentially syntactic statements as restrictions on the linear order of morphological tags. The error rate of the morphological disambiguator is about ten times smaller than that of another state-of-the-art probabilistic disambiguator, given that both are allowed to leave some of the hardest ambiguities unresolved. This accuracy suggests the viability of the grammar-based approach to natural language parsing, thus also contributing to the more general debate concerning the viability of probabilistic vs.\ linguistic techniques. {\it Experiments with heuristics} addresses the question of how to resolve those ambiguities that survive the morphological disambiguator. Two approaches are presented and empirically evaluated: (i) heuristic disambiguation constraints and (ii) techniques for learning from the fully disambiguated part of the corpus and then applying this information to resolving remaining ambiguities.