 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an implementable dependency grammar
Sep 02, 1998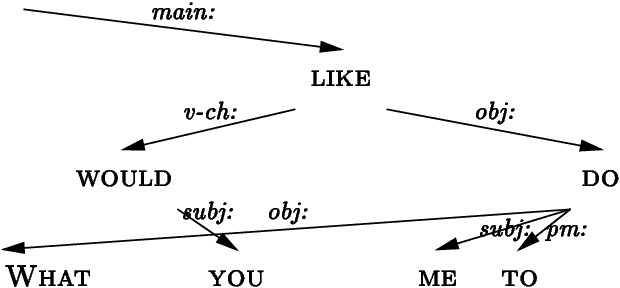
The aim of this paper is to define a dependency grammar framework which is both linguistically motivated and computationally parsable. See the demo at http://www.conexor.fi/analysers.html#testing
* 10 pages
Inducing Constraint Grammars
Jul 01, 1996Constraint Grammar rules are induced from corpora. A simple scheme based on local information, i.e., on lexical biases and next-neighbour contexts, extended through the use of barriers, reached 87.3 percent precision (1.12 tags/word) at 98.2 percent recall. The results compare favourably with other methods that are used for similar tasks although they are by no means as good as the results achieved using the original hand-written rules developed over several years time.
* 10 pages, uuencoded, gzipped PostScript
Creating a tagset, lexicon and guesser for a French tagger
Apr 05, 1995We earlier described two taggers for French, a statistical one and a constraint-based one. The two taggers have the same tokeniser and morphological analyser. In this paper, we describe aspects of this work concerned with the definition of the tagset, the building of the lexicon, derived from an existing two-level morphological analyser, and the definition of a lexical transducer for guessing unknown words.
* aclap.sty
Tagging French -- comparing a statistical and a constraint-based method
Mar 02, 1995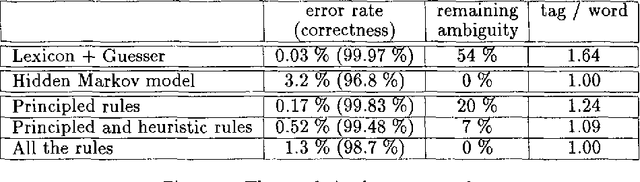
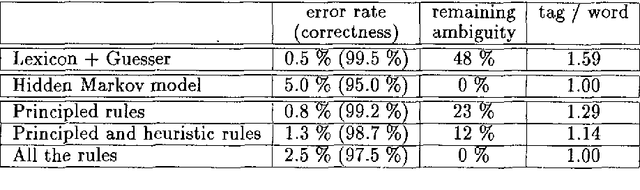
In this paper we compare two competing approaches to part-of-speech tagging, statistical and constraint-based disambiguation, using French as our test language. We imposed a time limit on our experiment: the amount of time spent on the design of our constraint system was about the same as the time we used to train and test the easy-to-implement statistical model. We describe the two systems and compare the results. The accuracy of the statistical method is reasonably good, comparable to taggers for English. But the constraint-based tagger seems to be superior even with the limited time we allowed ourselves for rule development.
* in Proceedings of EACL-95, uuencoded gzipped postscript
Ambiguity resolution in a reductionistic parser
Feb 13, 1995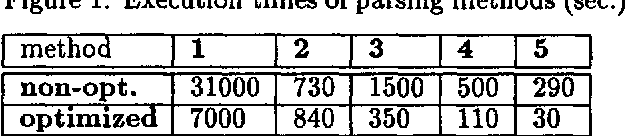
We are concerned with dependency-oriented morphosyntactic parsing of running text. While a parsing grammar should avoid introducing structurally unresolvable distinctions in order to optimise on the accuracy of the parser, it also is beneficial for the grammarian to have as expressive a structural representation available as possible. In a reductionistic parsing system this policy may result in considerable ambiguity in the input; however, even massive ambiguity can be tackled efficiently with an accurate parsing description and effective parsing technology.
Syntactic Analysis Of Natural Language Using Linguistic Rules And Corpus-based Patterns
Oct 25, 1994We are concerned with the syntactic annotation of unrestricted text. We combine a rule-based analysis with subsequent exploitation of empirical data. The rule-based surface syntactic analyser leaves some amount of ambiguity in the output that is resolved using empirical patterns. We have implemented a system for generating and applying corpus-based patterns. Some patterns describe the main constituents in the sentence and some the local context of the each syntactic function. There are several (partly) reduntant patterns, and the ``pattern'' parser selects analysis of the sentence that matches the strictest possible pattern(s). The system is applied to an experimental corpus. We present the results and discuss possible refinements of the method from a linguistic point of view.
Tagging accurately -- Don't guess if you know
Aug 16, 1994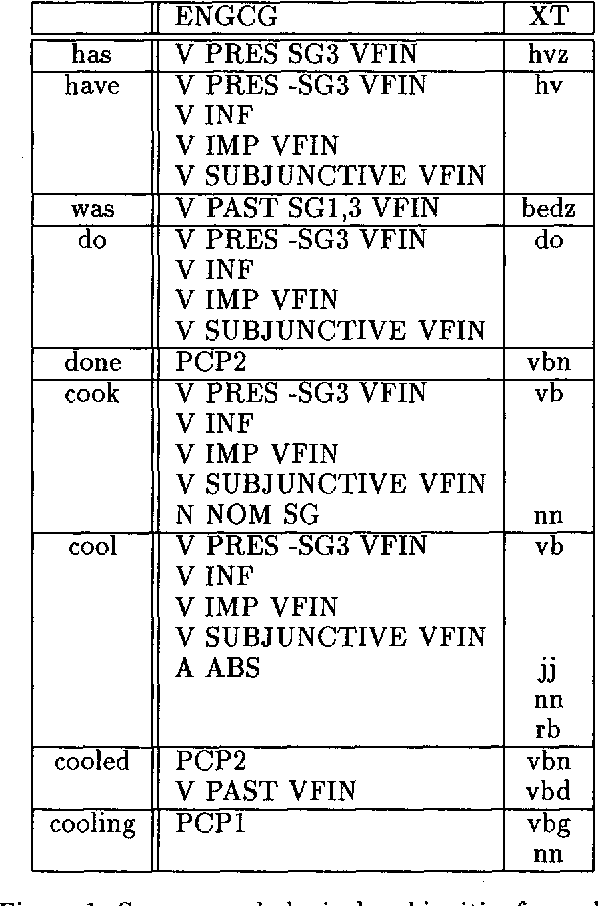
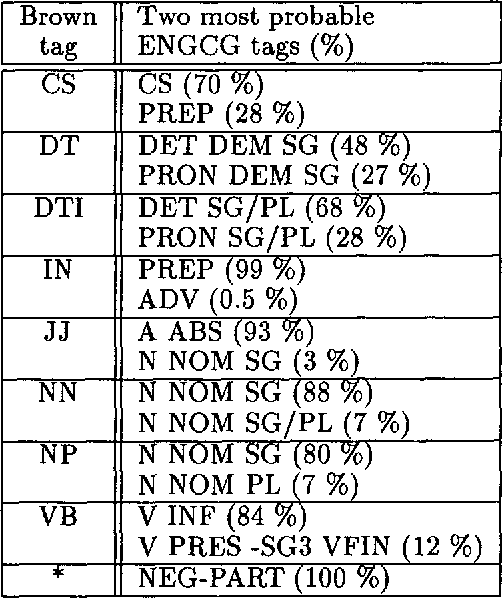
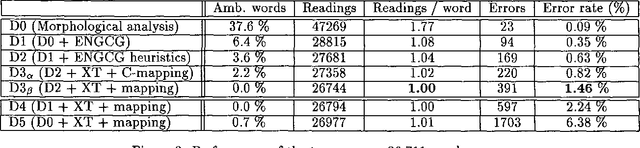
We discuss combining knowledge-based (or rule-based) and statistical part-of-speech taggers. We use two mature taggers, ENGCG and Xerox Tagger, to independently tag the same text and combine the results to produce a fully disambiguated text. In a 27000 word test sample taken from a previously unseen corpus we achieve 98.5% accuracy. This paper presents the data in detail. We describe the problems we encountered in the course of combining the two taggers and discuss the problem of evaluating taggers.