Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagging accurately -- Don't guess if you know
Paper and Code
Aug 16, 1994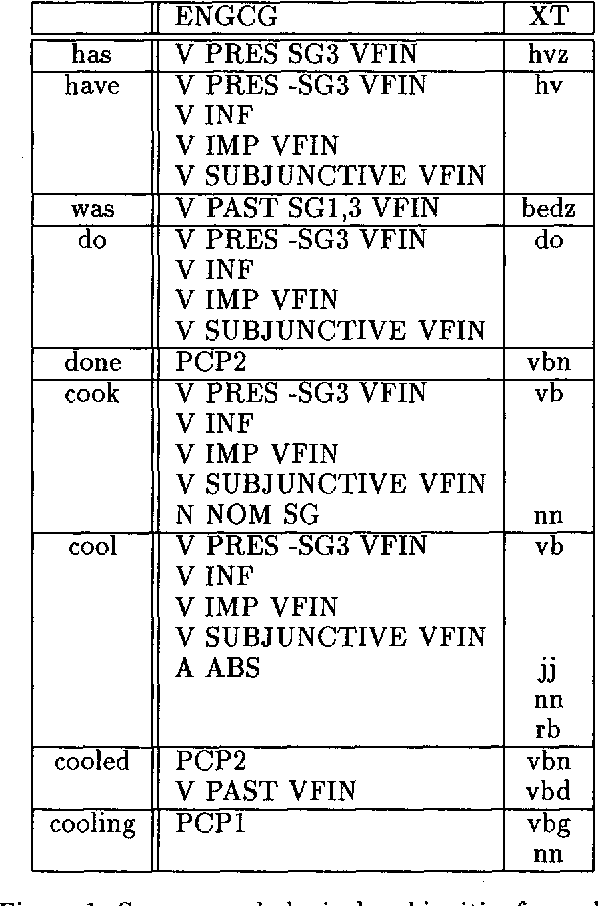
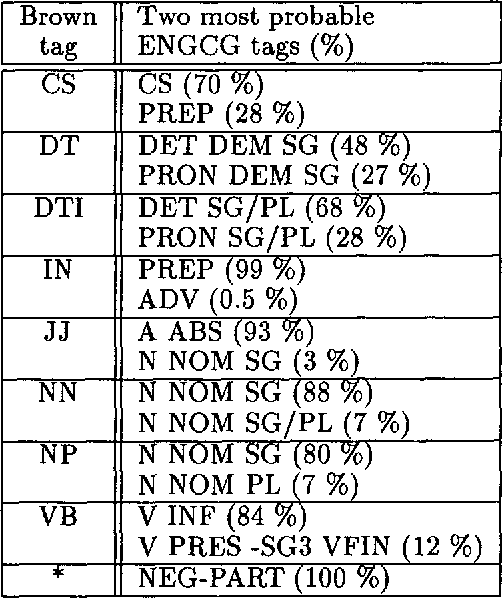
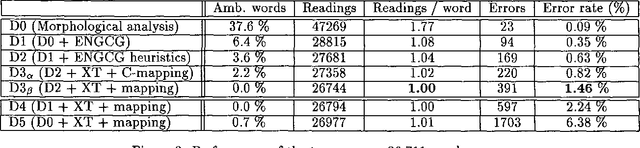
We discuss combining knowledge-based (or rule-based) and statistical part-of-speech taggers. We use two mature taggers, ENGCG and Xerox Tagger, to independently tag the same text and combine the results to produce a fully disambiguated text. In a 27000 word test sample taken from a previously unseen corpus we achieve 98.5% accuracy. This paper presents the data in detail. We describe the problems we encountered in the course of combining the two taggers and discuss the problem of evaluating taggers.
* 6 pages, Proc. ANLP94, uuencoded and gzipped postscript
View paper on