 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Construction of Minimal Acyclic Sequential Transducers from Unsorted Data
Aug 10, 2004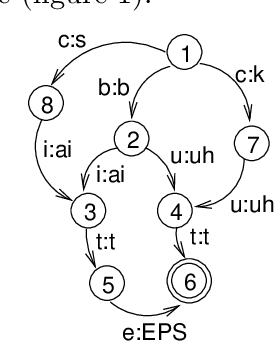

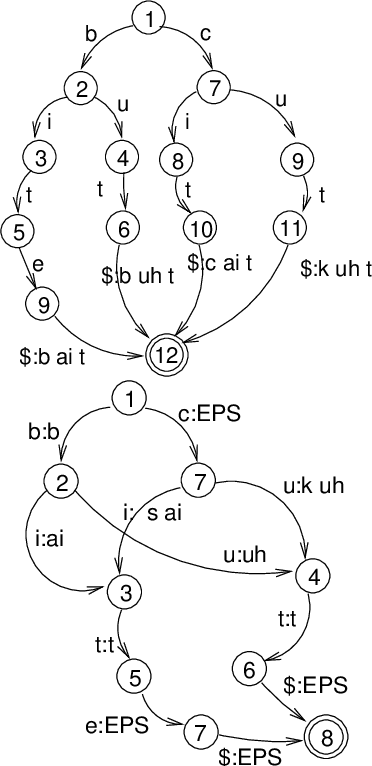
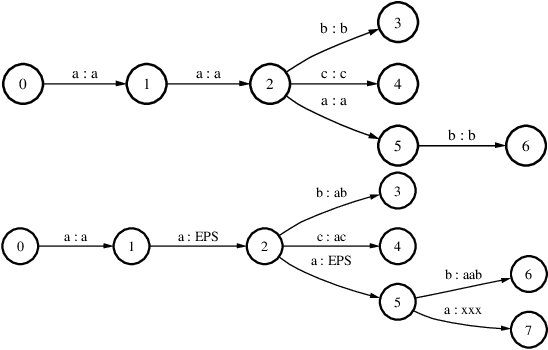
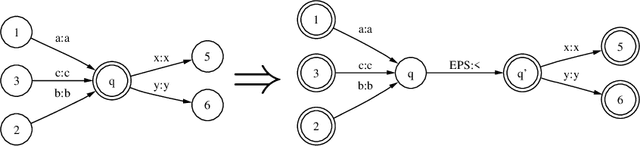
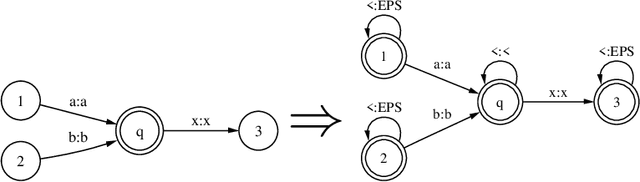
This paper presents an efficient algorithm for the incremental construction of a minimal acyclic sequential transducer (ST) for a dictionary consisting of a list of input and output strings. The algorithm generalises a known method of constructing minimal finite-state automata (Daciuk et al. 2000). Unlike the algorithm published by Mihov and Maurel (2001), it does not require the input strings to be sorted. The new method is illustrated by an application to pronunciation dictionaries.
A Bimachine Compiler for Ranked Tagging Rules
Jul 19, 2004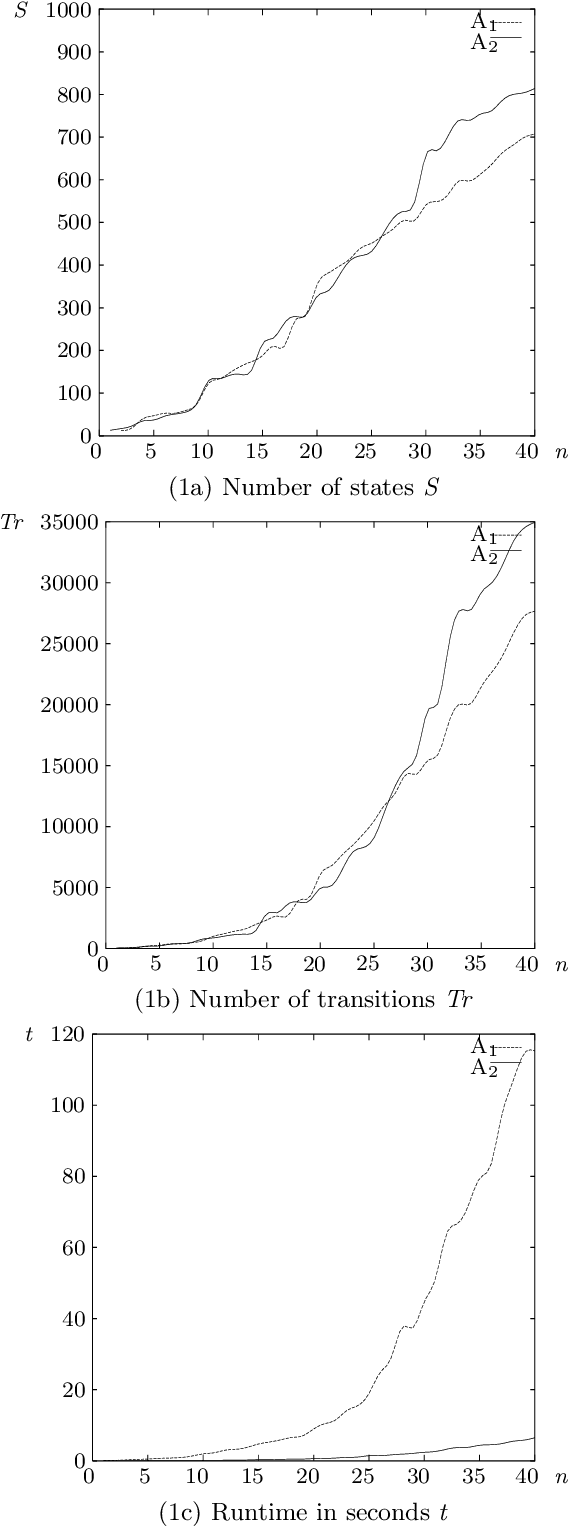
This paper describes a novel method of compiling ranked tagging rules into a deterministic finite-state device called a bimachine. The rules are formulated in the framework of regular rewrite operations and allow unrestricted regular expressions in both left and right rule contexts. The compiler is illustrated by an application within a speech synthesis system.
A Flexible Rule Compiler for Speech Synthesis
Mar 23, 2004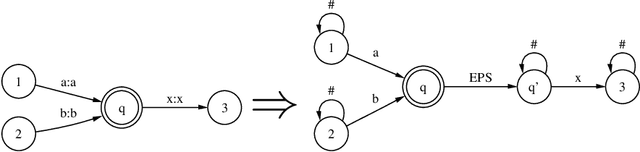
We present a flexible rule compiler developed for a text-to-speech (TTS) system. The compiler converts a set of rules into a finite-state transducer (FST). The input and output of the FST are subject to parameterization, so that the system can be applied to strings and sequences of feature-structures. The resulting transducer is guaranteed to realize a function (as opposed to a relation), and therefore can be implemented as a deterministic device (either a deterministic FST or a bimachine).
* 10 pages, 6 figures
A Linguistically Interpreted Corpus of German Newspaper Text
Jul 17, 1998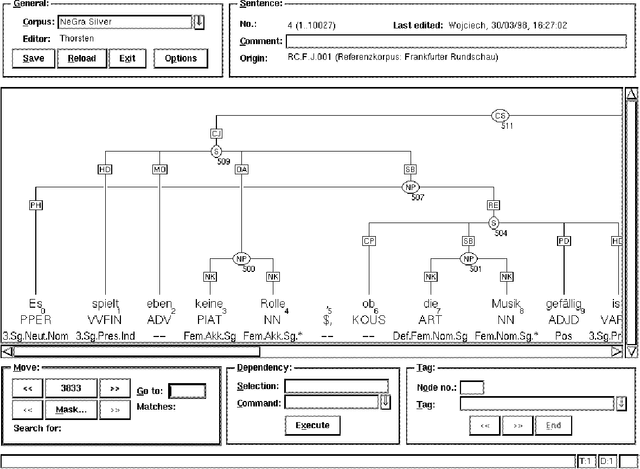
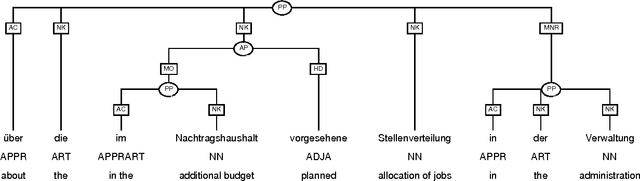
In this paper, we report on the development of an annotation scheme and annotation tools for unrestricted German text. Our representation format is based on argument structure, but also permits the extraction of other kinds of representations. We discuss several methodological issues and the analysis of some phenomena. Additional focus is on the tools developed in our project and their applications.
Chunk Tagger - Statistical Recognition of Noun Phrases
Jul 17, 1998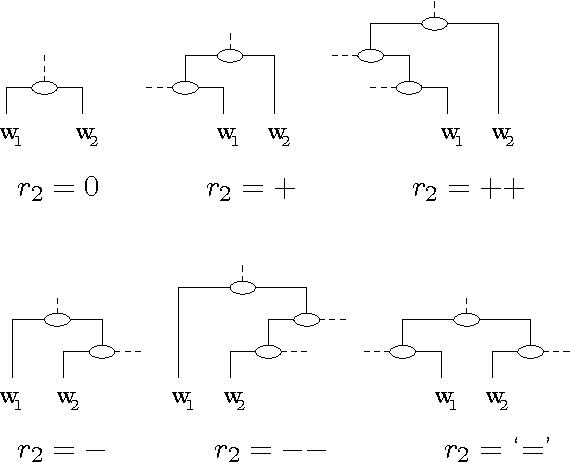


We describe a stochastic approach to partial parsing, i.e., the recognition of syntactic structures of limited depth. The technique utilises Markov Models, but goes beyond usual bracketing approaches, since it is capable of recognising not only the boundaries, but also the internal structure and syntactic category of simple as well as complex NP's, PP's, AP's and adverbials. We compare tagging accuracy for different applications and encoding schemes.
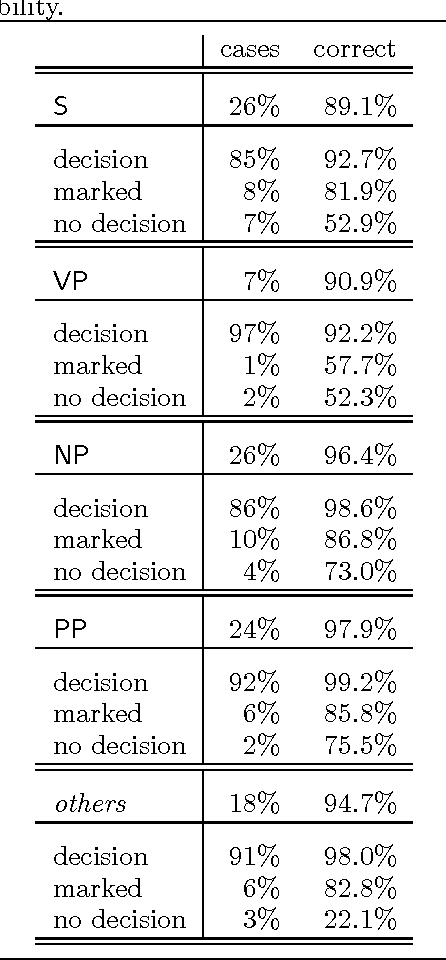
A Maximum-Entropy Partial Parser for Unrestricted Text
Jul 17, 1998
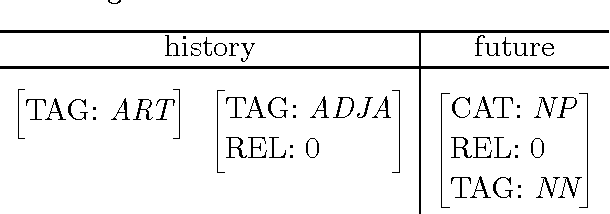
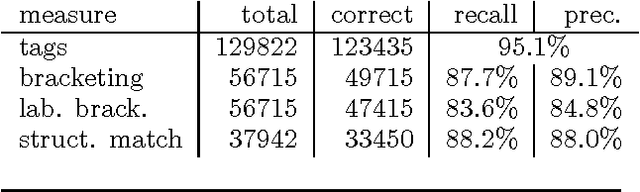
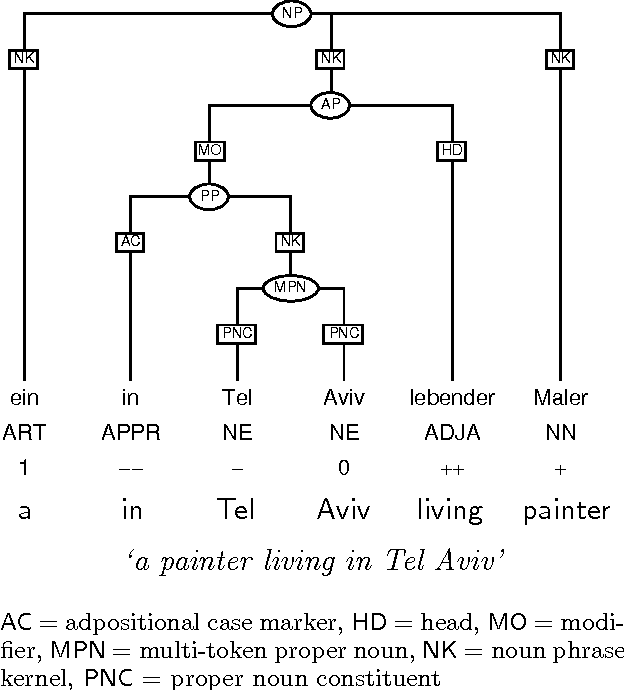
This paper describes a partial parser that assigns syntactic structures to sequences of part-of-speech tags. The program uses the maximum entropy parameter estimation method, which allows a flexible combination of different knowledge sources: the hierarchical structure, parts of speech and phrasal categories. In effect, the parser goes beyond simple bracketing and recognises even fairly complex structures. We give accuracy figures for different applications of the parser.
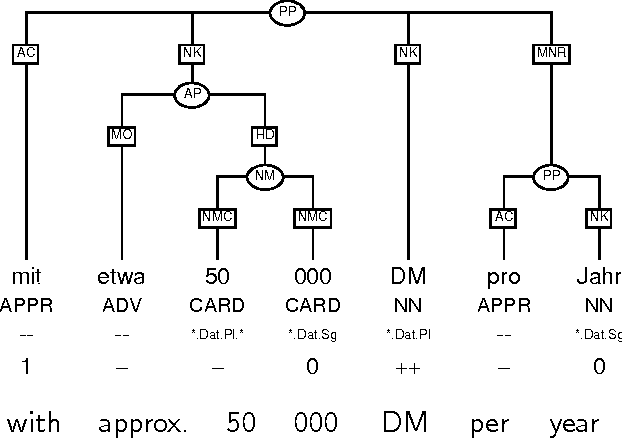
Tagging Grammatical Functions
Jul 23, 1997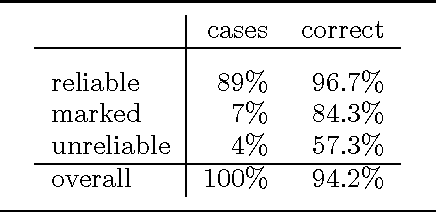
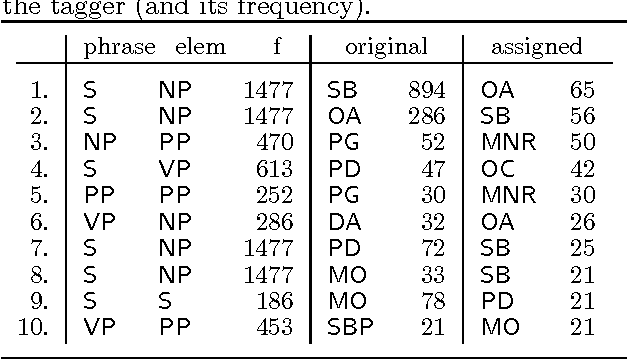
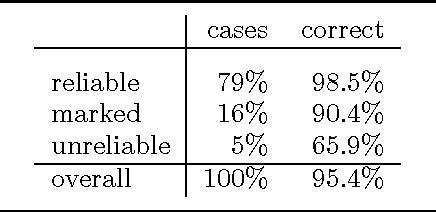
This paper addresses issues in automated treebank construction. We show how standard part-of-speech tagging techniques extend to the more general problem of structural annotation, especially for determining grammatical functions and syntactic categories. Annotation is viewed as an interactive process where manual and automatic processing alternate. Efficiency and accuracy results are presented. We also discuss further automation steps.
An Annotation Scheme for Free Word Order Languages
Feb 10, 1997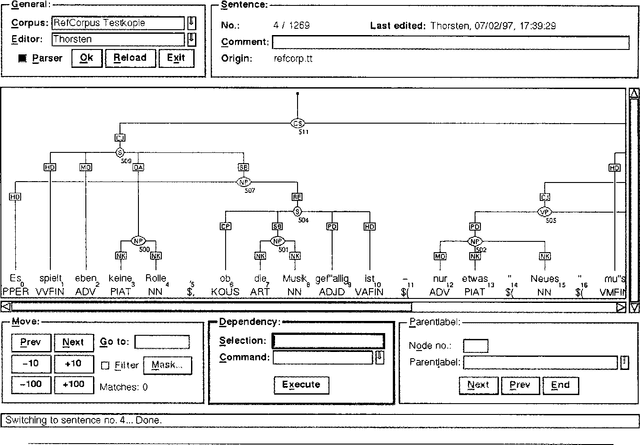
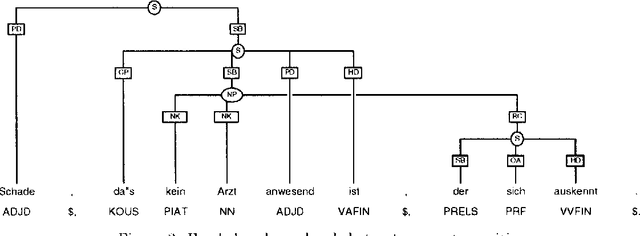
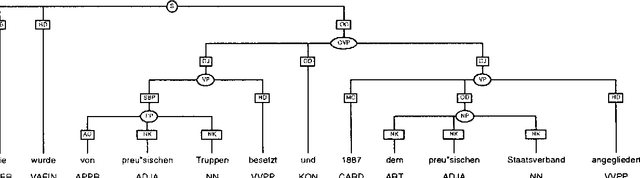
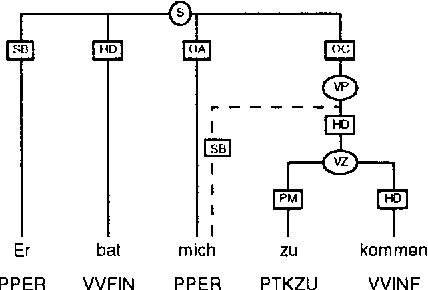
We describe an annotation scheme and a tool developed for creating linguistically annotated corpora for non-configurational languages. Since the requirements for such a formalism differ from those posited for configurational languages, several features have been added, influencing the architecture of the scheme. The resulting scheme reflects a stratificational notion of language, and makes only minimal assumptions about the interrelation of the particular representational strata.