 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Training and Convergence of Q-Learning -- Extended Version
Feb 05, 2026In recent work it is shown that Q-learning with linear function approximation is stable, in the sense of bounded parameter estimates, under the $(\varepsilon,κ)$-tamed Gibbs policy; $κ$ is inverse temperature, and $\varepsilon>0$ is introduced for additional exploration. Under these assumptions it also follows that there is a solution to the projected Bellman equation (PBE). Left open is uniqueness of the solution, and criteria for convergence outside of the standard tabular or linear MDP settings. The present work extends these results to other variants of Q-learning, and clarifies prior work: a one dimensional example shows that under an oblivious policy for training there may be no solution to the PBE, or multiple solutions, and in each case the algorithm is not stable under oblivious training. The main contribution is that far more structure is required for convergence. An example is presented for which the basis is ideal, in the sense that the true Q-function is in the span of the basis. However, there are two solutions to the PBE under the greedy policy, and hence also for the $(\varepsilon,κ)$-tamed Gibbs policy for all sufficiently small $\varepsilon>0$ and $κ\ge 1$.
Sufficient Exploration for Convex Q-learning
Oct 17, 2022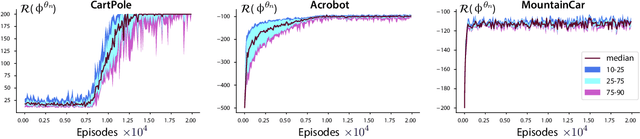
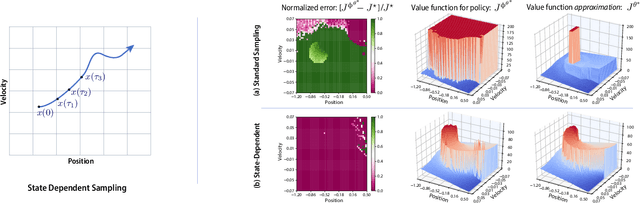

In recent years there has been a collective research effort to find new formulations of reinforcement learning that are simultaneously more efficient and more amenable to analysis. This paper concerns one approach that builds on the linear programming (LP) formulation of optimal control of Manne. A primal version is called logistic Q-learning, and a dual variant is convex Q-learning. This paper focuses on the latter, while building bridges with the former. The main contributions follow: (i) The dual of convex Q-learning is not precisely Manne's LP or a version of logistic Q-learning, but has similar structure that reveals the need for regularization to avoid over-fitting. (ii) A sufficient condition is obtained for a bounded solution to the Q-learning LP. (iii) Simulation studies reveal numerical challenges when addressing sampled-data systems based on a continuous time model. The challenge is addressed using state-dependent sampling. The theory is illustrated with applications to examples from OpenAI gym. It is shown that convex Q-learning is successful in cases where standard Q-learning diverges, such as the LQR problem.
Approximate dynamic programming using fluid and diffusion approximations with applications to power management
Jul 09, 2013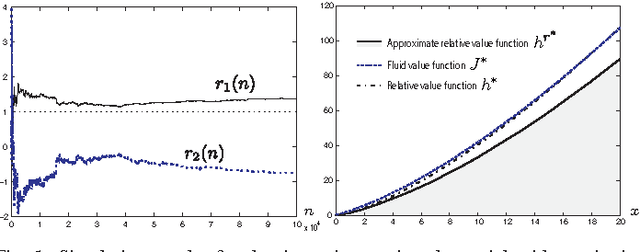
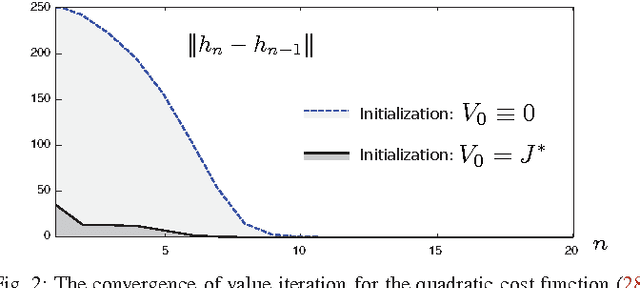
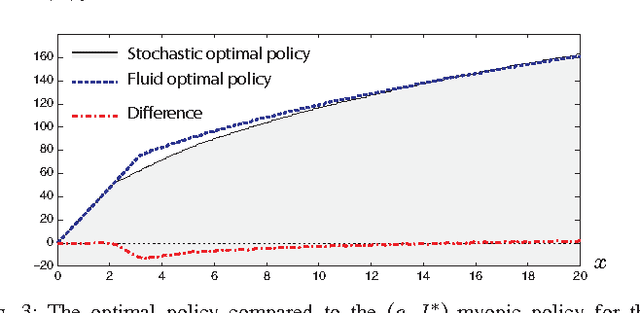
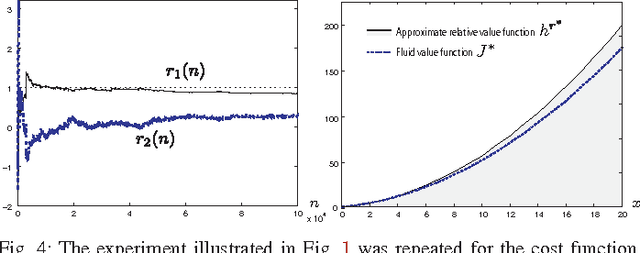
Neuro-dynamic programming is a class of powerful techniques for approximating the solution to dynamic programming equations. In their most computationally attractive formulations, these techniques provide the approximate solution only within a prescribed finite-dimensional function class. Thus, the question that always arises is how should the function class be chosen? The goal of this paper is to propose an approach using the solutions to associated fluid and diffusion approximations. In order to illustrate this approach, the paper focuses on an application to dynamic speed scaling for power management in computer processors.