 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow a Bit Becomes a Story: Semantic Steering via Differentiable Fault Injection
Dec 09, 2025Hard-to-detect hardware bit flips, from either malicious circuitry or bugs, have already been shown to make transformers vulnerable in non-generative tasks. This work, for the first time, investigates how low-level, bitwise perturbations (fault injection) to the weights of a large language model (LLM) used for image captioning can influence the semantic meaning of its generated descriptions while preserving grammatical structure. While prior fault analysis methods have shown that flipping a few bits can crash classifiers or degrade accuracy, these approaches overlook the semantic and linguistic dimensions of generative systems. In image captioning models, a single flipped bit might subtly alter how visual features map to words, shifting the entire narrative an AI tells about the world. We hypothesize that such semantic drifts are not random but differentiably estimable. That is, the model's own gradients can predict which bits, if perturbed, will most strongly influence meaning while leaving syntax and fluency intact. We design a differentiable fault analysis framework, BLADE (Bit-level Fault Analysis via Differentiable Estimation), that uses gradient-based sensitivity estimation to locate semantically critical bits and then refines their selection through a caption-level semantic-fluency objective. Our goal is not merely to corrupt captions, but to understand how meaning itself is encoded, distributed, and alterable at the bit level, revealing that even imperceptible low-level changes can steer the high-level semantics of generative vision-language models. It also opens pathways for robustness testing, adversarial defense, and explainable AI, by exposing how structured bit-level faults can reshape a model's semantic output.
ILASH: A Predictive Neural Architecture Search Framework for Multi-Task Applications
Dec 03, 2024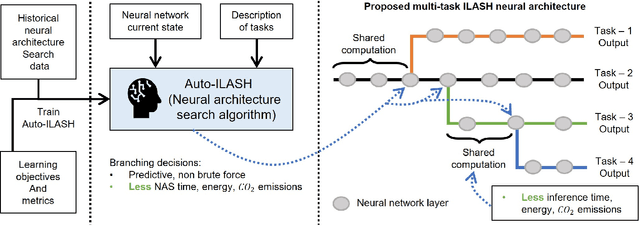
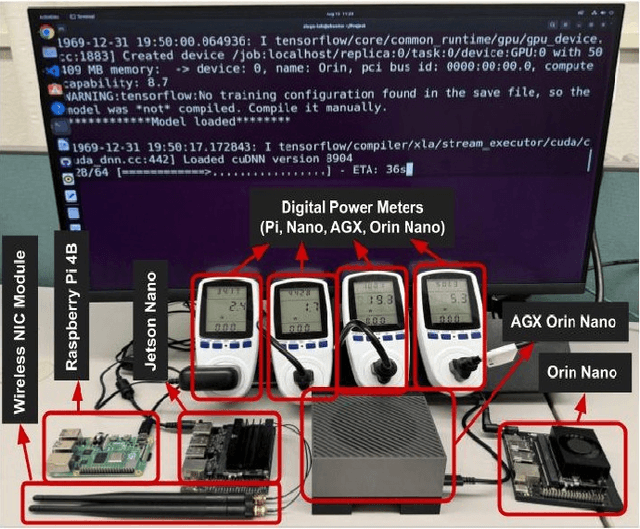
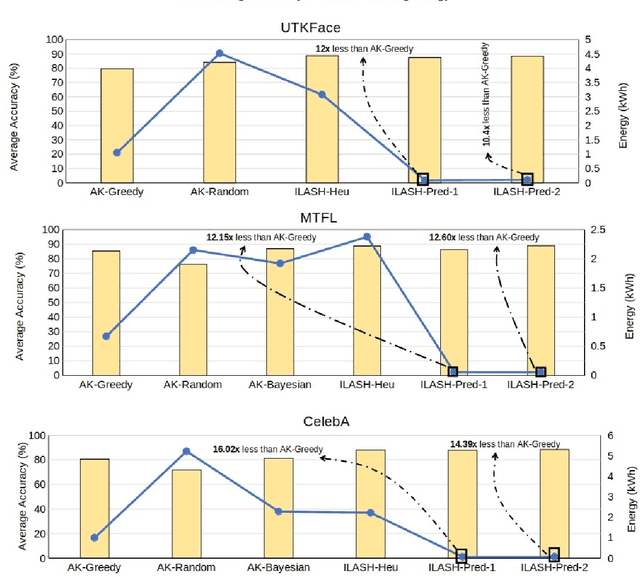
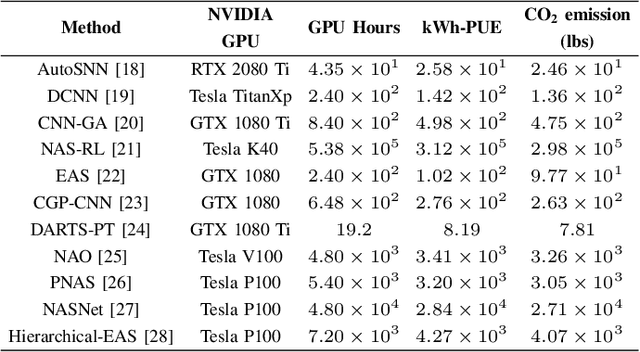
Artificial intelligence (AI) is widely used in various fields including healthcare, autonomous vehicles, robotics, traffic monitoring, and agriculture. Many modern AI applications in these fields are multi-tasking in nature (i.e. perform multiple analysis on same data) and are deployed on resource-constrained edge devices requiring the AI models to be efficient across different metrics such as power, frame rate, and size. For these specific use-cases, in this work, we propose a new paradigm of neural network architecture (ILASH) that leverages a layer sharing concept for minimizing power utilization, increasing frame rate, and reducing model size. Additionally, we propose a novel neural network architecture search framework (ILASH-NAS) for efficient construction of these neural network models for a given set of tasks and device constraints. The proposed NAS framework utilizes a data-driven intelligent approach to make the search efficient in terms of energy, time, and CO2 emission. We perform extensive evaluations of the proposed layer shared architecture paradigm (ILASH) and the ILASH-NAS framework using four open-source datasets (UTKFace, MTFL, CelebA, and Taskonomy). We compare ILASH-NAS with AutoKeras and observe significant improvement in terms of both the generated model performance and neural search efficiency with up to 16x less energy utilization, CO2 emission, and training/search time.
X-DFS: Explainable Artificial Intelligence Guided Design-for-Security Solution Space Exploration
Nov 11, 2024



Design and manufacturing of integrated circuits predominantly use a globally distributed semiconductor supply chain involving diverse entities. The modern semiconductor supply chain has been designed to boost production efficiency, but is filled with major security concerns such as malicious modifications (hardware Trojans), reverse engineering (RE), and cloning. While being deployed, digital systems are also subject to a plethora of threats such as power, timing, and electromagnetic (EM) side channel attacks. Many Design-for-Security (DFS) solutions have been proposed to deal with these vulnerabilities, and such solutions (DFS) relays on strategic modifications (e.g., logic locking, side channel resilient masking, and dummy logic insertion) of the digital designs for ensuring a higher level of security. However, most of these DFS strategies lack robust formalism, are often not human-understandable, and require an extensive amount of human expert effort during their development/use. All of these factors make it difficult to keep up with the ever growing number of microelectronic vulnerabilities. In this work, we propose X-DFS, an explainable Artificial Intelligence (AI) guided DFS solution-space exploration approach that can dramatically cut down the mitigation strategy development/use time while enriching our understanding of the vulnerability by providing human-understandable decision rationale. We implement X-DFS and comprehensively evaluate it for reverse engineering threats (SAIL, SWEEP, and OMLA) and formalize a generalized mechanism for applying X-DFS to defend against other threats such as hardware Trojans, fault attacks, and side channel attacks for seamless future extensions.
LeMo-NADe: Multi-Parameter Neural Architecture Discovery with LLMs
Feb 28, 2024



Building efficient neural network architectures can be a time-consuming task requiring extensive expert knowledge. This task becomes particularly challenging for edge devices because one has to consider parameters such as power consumption during inferencing, model size, inferencing speed, and CO2 emissions. In this article, we introduce a novel framework designed to automatically discover new neural network architectures based on user-defined parameters, an expert system, and an LLM trained on a large amount of open-domain knowledge. The introduced framework (LeMo-NADe) is tailored to be used by non-AI experts, does not require a predetermined neural architecture search space, and considers a large set of edge device-specific parameters. We implement and validate this proposed neural architecture discovery framework using CIFAR-10, CIFAR-100, and ImageNet16-120 datasets while using GPT-4 Turbo and Gemini as the LLM component. We observe that the proposed framework can rapidly (within hours) discover intricate neural network models that perform extremely well across a diverse set of application settings defined by the user.
Third-Party Hardware IP Assurance against Trojans through Supervised Learning and Post-processing
Nov 29, 2021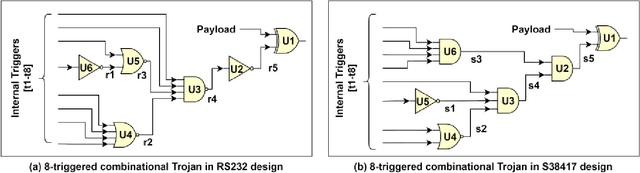

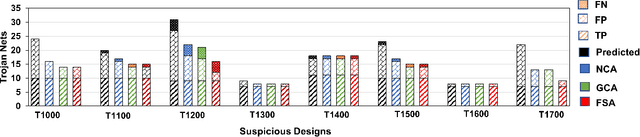

System-on-chip (SoC) developers increasingly rely on pre-verified hardware intellectual property (IP) blocks acquired from untrusted third-party vendors. These IPs might contain hidden malicious functionalities or hardware Trojans to compromise the security of the fabricated SoCs. Recently, supervised machine learning (ML) techniques have shown promising capability in identifying nets of potential Trojans in third party IPs (3PIPs). However, they bring several major challenges. First, they do not guide us to an optimal choice of features that reliably covers diverse classes of Trojans. Second, they require multiple Trojan-free/trusted designs to insert known Trojans and generate a trained model. Even if a set of trusted designs are available for training, the suspect IP could be inherently very different from the set of trusted designs, which may negatively impact the verification outcome. Third, these techniques only identify a set of suspect Trojan nets that require manual intervention to understand the potential threat. In this paper, we present VIPR, a systematic machine learning (ML) based trust verification solution for 3PIPs that eliminates the need for trusted designs for training. We present a comprehensive framework, associated algorithms, and a tool flow for obtaining an optimal set of features, training a targeted machine learning model, detecting suspect nets, and identifying Trojan circuitry from the suspect nets. We evaluate the framework on several Trust-Hub Trojan benchmarks and provide a comparative analysis of detection performance across different trained models, selection of features, and post-processing techniques. The proposed post-processing algorithms reduce false positives by up to 92.85%.
Neural Storage: A New Paradigm of Elastic Memory
Jan 07, 2021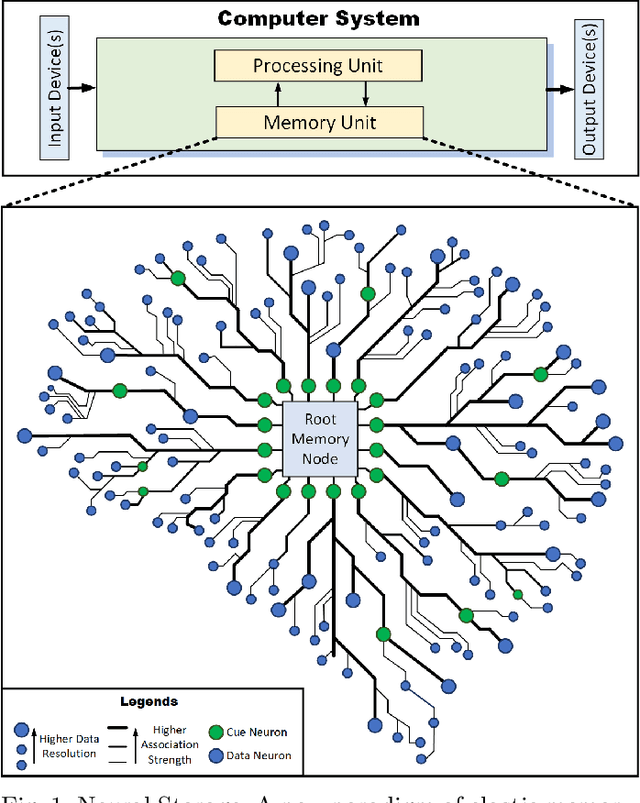

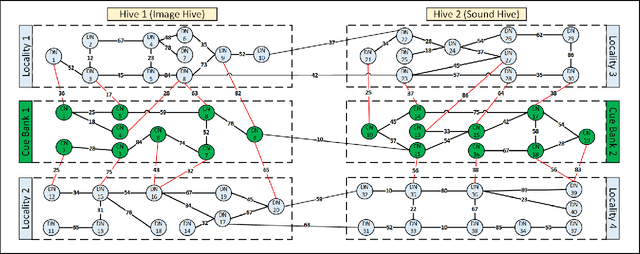

Storage and retrieval of data in a computer memory plays a major role in system performance. Traditionally, computer memory organization is static - i.e., they do not change based on the application-specific characteristics in memory access behaviour during system operation. Specifically, the association of a data block with a search pattern (or cues) as well as the granularity of a stored data do not evolve. Such a static nature of computer memory, we observe, not only limits the amount of data we can store in a given physical storage, but it also misses the opportunity for dramatic performance improvement in various applications. On the contrary, human memory is characterized by seemingly infinite plasticity in storing and retrieving data - as well as dynamically creating/updating the associations between data and corresponding cues. In this paper, we introduce Neural Storage (NS), a brain-inspired learning memory paradigm that organizes the memory as a flexible neural memory network. In NS, the network structure, strength of associations, and granularity of the data adjust continuously during system operation, providing unprecedented plasticity and performance benefits. We present the associated storage/retrieval/retention algorithms in NS, which integrate a formalized learning process. Using a full-blown operational model, we demonstrate that NS achieves an order of magnitude improvement in memory access performance for two representative applications when compared to traditional content-based memory.
Leveraging Domain Knowledge using Machine Learning for Image Compression in Internet-of-Things
Sep 14, 2020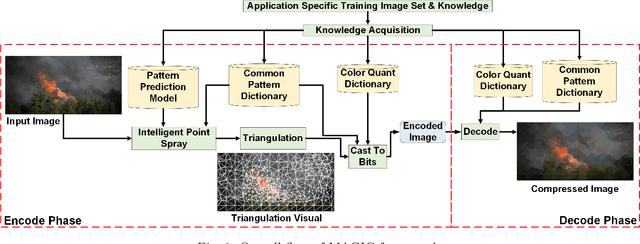

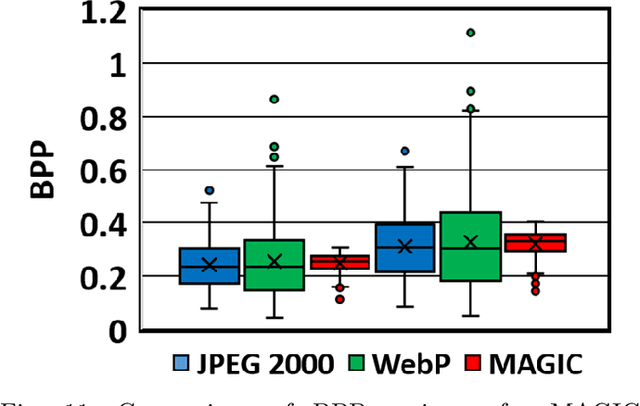
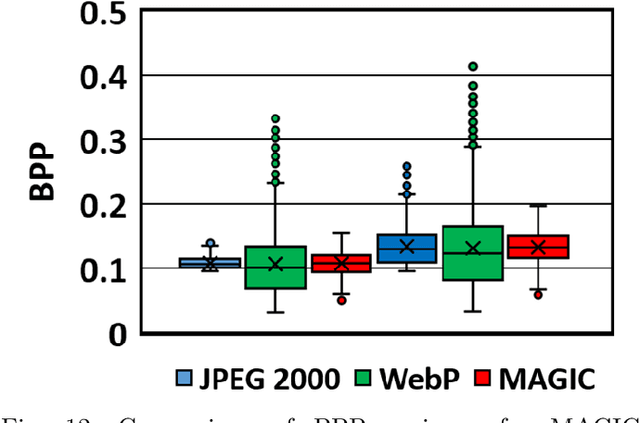
The emergent ecosystems of intelligent edge devices in diverse Internet of Things (IoT) applications, from automatic surveillance to precision agriculture, increasingly rely on recording and processing variety of image data. Due to resource constraints, e.g., energy and communication bandwidth requirements, these applications require compressing the recorded images before transmission. For these applications, image compression commonly requires: (1) maintaining features for coarse-grain pattern recognition instead of the high-level details for human perception due to machine-to-machine communications; (2) high compression ratio that leads to improved energy and transmission efficiency; (3) large dynamic range of compression and an easy trade-off between compression factor and quality of reconstruction to accommodate a wide diversity of IoT applications as well as their time-varying energy/performance needs. To address these requirements, we propose, MAGIC, a novel machine learning (ML) guided image compression framework that judiciously sacrifices visual quality to achieve much higher compression when compared to traditional techniques, while maintaining accuracy for coarse-grained vision tasks. The central idea is to capture application-specific domain knowledge and efficiently utilize it in achieving high compression. We demonstrate that the MAGIC framework is configurable across a wide range of compression/quality and is capable of compressing beyond the standard quality factor limits of both JPEG 2000 and WebP. We perform experiments on representative IoT applications using two vision datasets and show up to 42.65x compression at similar accuracy with respect to the source. We highlight low variance in compression rate across images using our technique as compared to JPEG 2000 and WebP.
Learning to Estimate Pose by Watching Videos
Apr 13, 2017
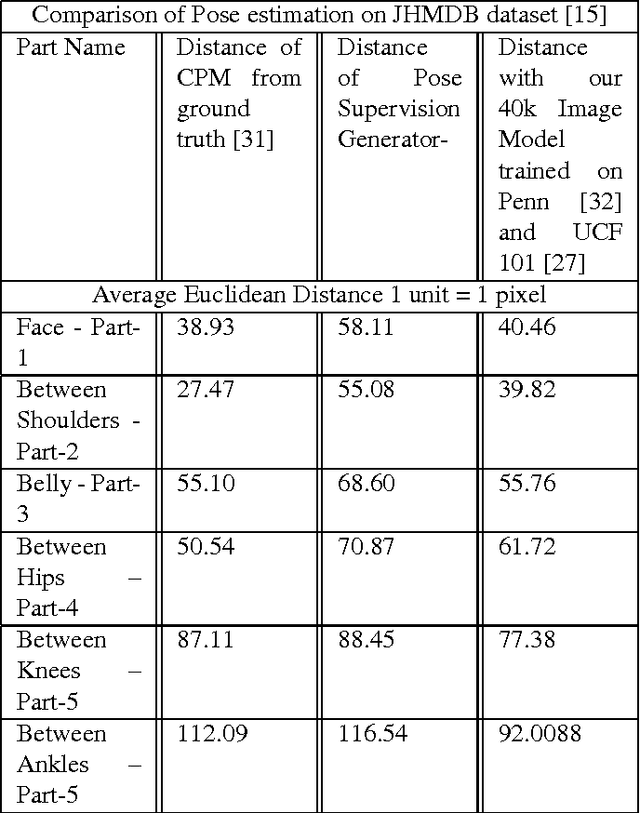
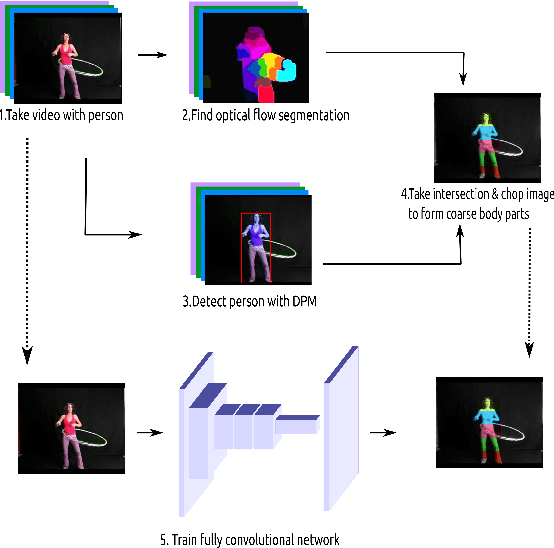
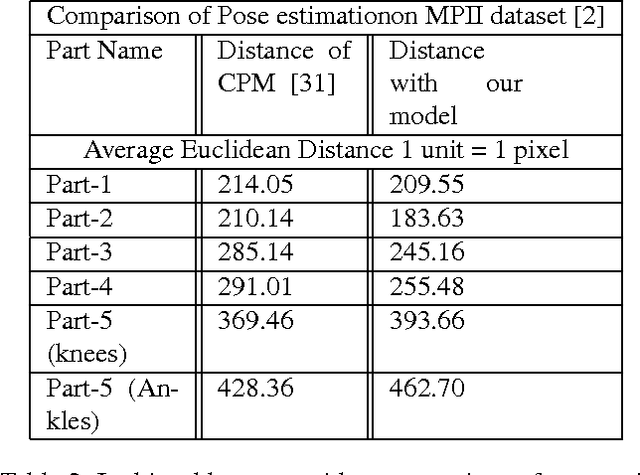
In this paper we propose a technique for obtaining coarse pose estimation of humans in an image that does not require any manual supervision. While a general unsupervised technique would fail to estimate human pose, we suggest that sufficient information about coarse pose can be obtained by observing human motion in multiple frames. Specifically, we consider obtaining surrogate supervision through videos as a means for obtaining motion based grouping cues. We supplement the method using a basic object detector that detects persons. With just these components we obtain a rough estimate of the human pose. With these samples for training, we train a fully convolutional neural network (FCNN)[20] to obtain accurate dense blob based pose estimation. We show that the results obtained are close to the ground-truth and to the results obtained using a fully supervised convolutional pose estimation method [31] as evaluated on a challenging dataset [15]. This is further validated by evaluating the obtained poses using a pose based action recognition method [5]. In this setting we outperform the results as obtained using the baseline method that uses a fully supervised pose estimation algorithm and is competitive with a new baseline created using convolutional pose estimation with full supervision.