 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECG Latent Feature Extraction with Autoencoders for Downstream Prediction Tasks
Jul 31, 2025The electrocardiogram (ECG) is an inexpensive and widely available tool for cardiac assessment. Despite its standardized format and small file size, the high complexity and inter-individual variability of ECG signals (typically a 60,000-size vector with 12 leads at 500 Hz) make it challenging to use in deep learning models, especially when only small training datasets are available. This study addresses these challenges by exploring feature generation methods from representative beat ECGs, focusing on Principal Component Analysis (PCA) and Autoencoders to reduce data complexity. We introduce three novel Variational Autoencoder (VAE) variants-Stochastic Autoencoder (SAE), Annealed beta-VAE (A beta-VAE), and Cyclical beta VAE (C beta-VAE)-and compare their effectiveness in maintaining signal fidelity and enhancing downstream prediction tasks using a Light Gradient Boost Machine (LGBM). The A beta-VAE achieved superior signal reconstruction, reducing the mean absolute error (MAE) to 15.7+/-3.2 muV, which is at the level of signal noise. Moreover, the SAE encodings, when combined with traditional ECG summary features, improved the prediction of reduced Left Ventricular Ejection Fraction (LVEF), achieving an holdout test set area under the receiver operating characteristic curve (AUROC) of 0.901 with a LGBM classifier. This performance nearly matches the 0.909 AUROC of state-of-the-art CNN model but requires significantly less computational resources. Further, the ECG feature extraction-LGBM pipeline avoids overfitting and retains predictive performance when trained with less data. Our findings demonstrate that these VAE encodings are not only effective in simplifying ECG data but also provide a practical solution for applying deep learning in contexts with limited-scale labeled training data.
ILASH: A Predictive Neural Architecture Search Framework for Multi-Task Applications
Dec 03, 2024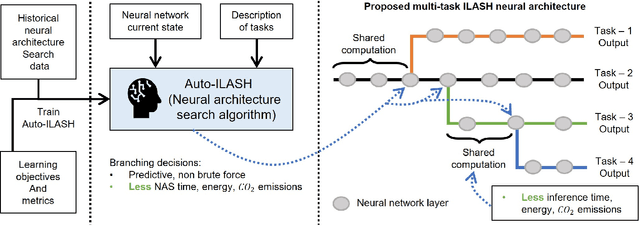
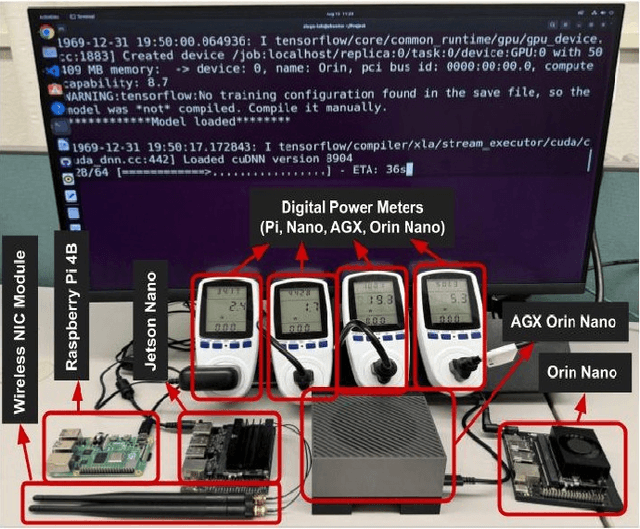
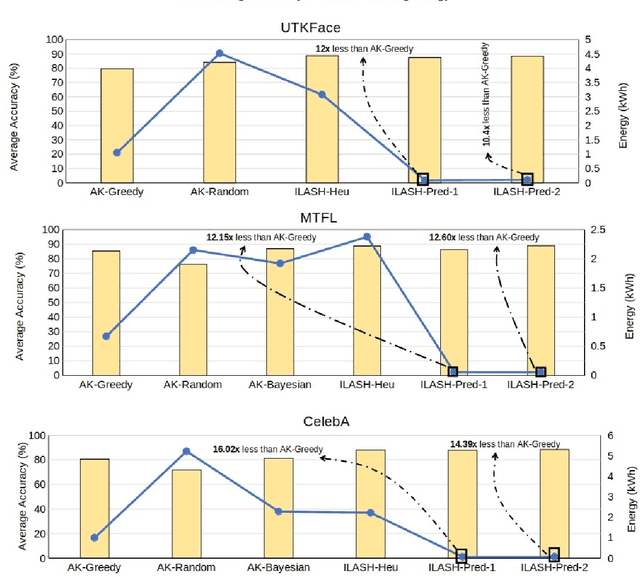
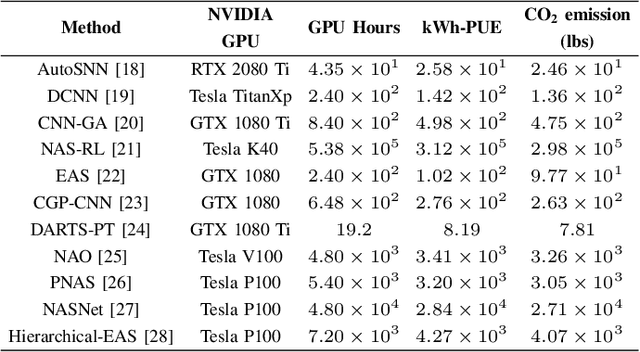
Artificial intelligence (AI) is widely used in various fields including healthcare, autonomous vehicles, robotics, traffic monitoring, and agriculture. Many modern AI applications in these fields are multi-tasking in nature (i.e. perform multiple analysis on same data) and are deployed on resource-constrained edge devices requiring the AI models to be efficient across different metrics such as power, frame rate, and size. For these specific use-cases, in this work, we propose a new paradigm of neural network architecture (ILASH) that leverages a layer sharing concept for minimizing power utilization, increasing frame rate, and reducing model size. Additionally, we propose a novel neural network architecture search framework (ILASH-NAS) for efficient construction of these neural network models for a given set of tasks and device constraints. The proposed NAS framework utilizes a data-driven intelligent approach to make the search efficient in terms of energy, time, and CO2 emission. We perform extensive evaluations of the proposed layer shared architecture paradigm (ILASH) and the ILASH-NAS framework using four open-source datasets (UTKFace, MTFL, CelebA, and Taskonomy). We compare ILASH-NAS with AutoKeras and observe significant improvement in terms of both the generated model performance and neural search efficiency with up to 16x less energy utilization, CO2 emission, and training/search time.
Comparison of Autoencoder Encodings for ECG Representation in Downstream Prediction Tasks
Oct 03, 2024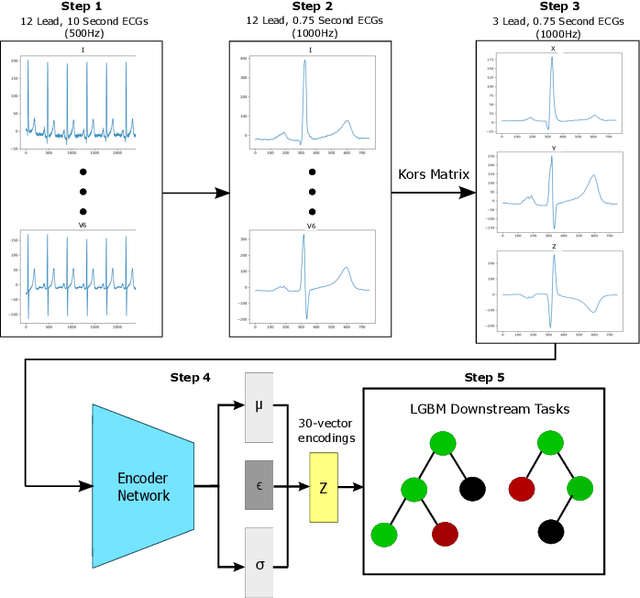
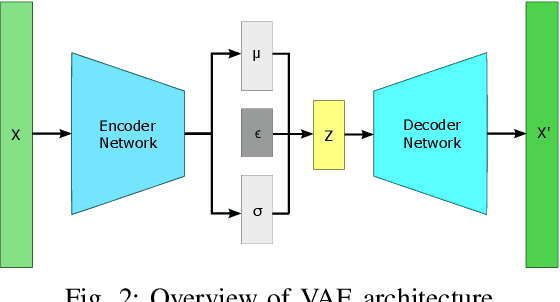
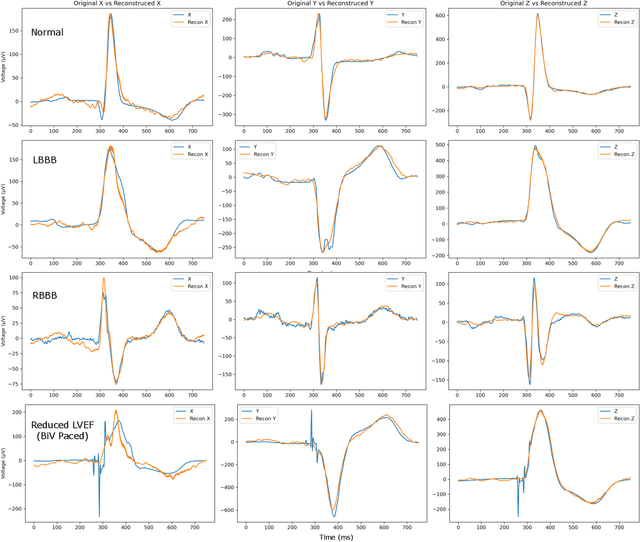

The electrocardiogram (ECG) is an inexpensive and widely available tool for cardiovascular assessment. Despite its standardized format and small file size, the high complexity and inter-individual variability of ECG signals (typically a 60,000-size vector) make it challenging to use in deep learning models, especially when only small datasets are available. This study addresses these challenges by exploring feature generation methods from representative beat ECGs, focusing on Principal Component Analysis (PCA) and Autoencoders to reduce data complexity. We introduce three novel Variational Autoencoder (VAE) variants: Stochastic Autoencoder (SAE), Annealed beta-VAE (Abeta-VAE), and cyclical beta-VAE (Cbeta-VAE), and compare their effectiveness in maintaining signal fidelity and enhancing downstream prediction tasks. The Abeta-VAE achieved superior signal reconstruction, reducing the mean absolute error (MAE) to 15.7 plus-minus 3.2 microvolts, which is at the level of signal noise. Moreover, the SAE encodings, when combined with ECG summary features, improved the prediction of reduced Left Ventricular Ejection Fraction (LVEF), achieving an area under the receiver operating characteristic curve (AUROC) of 0.901. This performance nearly matches the 0.910 AUROC of state-of-the-art CNN models but requires significantly less data and computational resources. Our findings demonstrate that these VAE encodings are not only effective in simplifying ECG data but also provide a practical solution for applying deep learning in contexts with limited-scale labeled training data.