 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequencyFormer: A Co-Designed Sensor-to-Processor Pipeline for Frequency-Domain Vision Transformer Inference
Jun 17, 2026Deploying vision transformers (ViTs) on sensor-edge systems is limited not only by on-device compute, but also by the energy and bandwidth required to transmit high-dimensional image data from the sensor to the processor. While in-sensor and near-sensor computing reduce this cost through early feature extraction, existing methods often provide only modest compression. We observe that the frequency domain provides a naturally compact representation of visual information and can be exploited at the sensor level to reduce sensor-to-processor data movement. Building on this insight, we present FrequencyFormer, a co-designed sensor-to-processor pipeline for efficient ViT inference. FrequencyFormer includes: (1) a multi-scale DCT tokenizer that compresses a 224x224 image into compact frequency-domain tokens, achieving up to 128x reduction in off-chip data volume with modest accuracy loss; (2) a LUT-based near-sensor hardware implementation that leverages fixed DCT coefficients for multiplier-free, energy- and area-efficient tokenization; and (3) a modified MIPI-based low-power communication architecture that further reduces transfer energy. FrequencyFormer serves as a drop-in replacement for standard ViT patch embedding and remains compatible with pretrained backbones across classification, detection, and segmentation tasks. The pipeline achieves 28.8 TOPS/W, reduces communication energy by 230x, and lowers total sensor-side energy by 2.22x, demonstrating frequency-domain tokenization as a scalable foundation for in-sensor ViT deployment.
Ablation Study of Block Size, Weight Precision, and Scale Precision in NVFP4 Inference for Low-Power Edge-Efficient Neural Networks
Jun 03, 2026Energy-efficient edge inference requires reducing arithmetic cost, memory traffic, and hardware overhead. This paper presents an ablation-focused study of NVFP4 LUT-based inference for edge-efficient neural networks. The proposed NVLUT framework combines 4-bit NVFP4 activations, two-level scaling, LUT-based mantissa computation, voltage-scaled storage, and selective ECC protection. Multiplication is decomposed into sign, exponent, and mantissa paths, where sign uses XOR logic, exponent uses integer addition, and mantissa multiplication is replaced by compact LUT access. NVFP4 activations use FP4 data with an FP8 block scale and an FP32 tensor scale. Across six edge-efficient models, block-size ablation shows that B = 16 offers a practical accuracy/storage trade-off, requiring only 4.5078 bits per input for N = 4096. Weight-precision ablation shows that FP8 and FP16 weights provide only modest gains over FP4 weights under the same NVFP4 activation path. Compared with pure unscaled FP4, NVFP4 without retraining recovers substantial accuracy by restoring activation dynamic range, while NVFP4 with retraining achieves the best accuracy across models. Hardware analysis shows that NVLUT achieves up to 26.85x energy reduction over traditional LUTs with ECC plus voltage scaling and up to 22.85x under mixed-voltage operation. Area is reduced by up to 2.21x and 1.52x, respectively. These results demonstrate that NVFP4 two-level scaling with selective reliability protection enables robust, low-energy edge inference.
LASH: Adaptive Semantic Hybridization for Black-Box Jailbreaking of Large Language Models
May 20, 2026Jailbreak attacks expose a persistent gap between the intended safety behavior of aligned large language models and their behavior under adversarial prompting. Existing automated methods are increasingly effective but each commits to a single attack family (e.g., one refinement loop, one tree search, one mutation space, or one strategy library) and no single family dominates: the best-performing method shifts across target models and harm categories, suggesting complementary strengths that per-prompt composition could exploit. We introduce LASH (LLM Adaptive Semantic Hybridization), a black-box framework that treats outputs from multiple base attacks as reusable seed prompts and adaptively composes them for each target request. Given a seed pool, LASH searches over seed subsets and softmax-normalized mixture weights; a composition module synthesizes a single candidate prompt, and a derivative-free genetic optimizer updates the weights using black-box target feedback and a two-stage fitness function combining keyword-based refusal detection with LLM-judge scoring. On JailbreakBench, which contains 100 harmful prompts across 10 categories, we evaluate LASH on six common target models. LASH achieves an average attack success rate of 84.5% under keyword-based evaluation and 74.5% under two-stage evaluation, where responses are first filtered for refusals and then scored by an LLM judge for whether they substantively fulfill the original harmful request. LASH outperforms five state-of-the-art baselines on both metrics with only 30 mean target queries. LASH also remains competitive under three defense mechanisms and induces more success-like internal representations. These results suggest that adaptive composition across heterogeneous jailbreak strategies is a promising direction for black-box red-teaming.
HAMLOCK: HArdware-Model LOgically Combined attacK
Oct 22, 2025The growing use of third-party hardware accelerators (e.g., FPGAs, ASICs) for deep neural networks (DNNs) introduces new security vulnerabilities. Conventional model-level backdoor attacks, which only poison a model's weights to misclassify inputs with a specific trigger, are often detectable because the entire attack logic is embedded within the model (i.e., software), creating a traceable layer-by-layer activation path. This paper introduces the HArdware-Model Logically Combined Attack (HAMLOCK), a far stealthier threat that distributes the attack logic across the hardware-software boundary. The software (model) is now only minimally altered by tuning the activations of few neurons to produce uniquely high activation values when a trigger is present. A malicious hardware Trojan detects those unique activations by monitoring the corresponding neurons' most significant bit or the 8-bit exponents and triggers another hardware Trojan to directly manipulate the final output logits for misclassification. This decoupled design is highly stealthy, as the model itself contains no complete backdoor activation path as in conventional attacks and hence, appears fully benign. Empirically, across benchmarks like MNIST, CIFAR10, GTSRB, and ImageNet, HAMLOCK achieves a near-perfect attack success rate with a negligible clean accuracy drop. More importantly, HAMLOCK circumvents the state-of-the-art model-level defenses without any adaptive optimization. The hardware Trojan is also undetectable, incurring area and power overheads as low as 0.01%, which is easily masked by process and environmental noise. Our findings expose a critical vulnerability at the hardware-software interface, demanding new cross-layer defenses against this emerging threat.
Secure and Storage-Efficient Deep Learning Models for Edge AI Using Automatic Weight Generation
Jul 08, 2025Complex neural networks require substantial memory to store a large number of synaptic weights. This work introduces WINGs (Automatic Weight Generator for Secure and Storage-Efficient Deep Learning Models), a novel framework that dynamically generates layer weights in a fully connected neural network (FC) and compresses the weights in convolutional neural networks (CNNs) during inference, significantly reducing memory requirements without sacrificing accuracy. WINGs framework uses principal component analysis (PCA) for dimensionality reduction and lightweight support vector regression (SVR) models to predict layer weights in the FC networks, removing the need for storing full-weight matrices and achieving substantial memory savings. It also preferentially compresses the weights in low-sensitivity layers of CNNs using PCA and SVR with sensitivity analysis. The sensitivity-aware design also offers an added level of security, as any bit-flip attack with weights in compressed layers has an amplified and readily detectable effect on accuracy. WINGs achieves 53x compression for the FC layers and 28x for AlexNet with MNIST dataset, and 18x for Alexnet with CIFAR-10 dataset with 1-2% accuracy loss. This significant reduction in memory results in higher throughput and lower energy for DNN inference, making it attractive for resource-constrained edge applications.
Runtime Detection of Adversarial Attacks in AI Accelerators Using Performance Counters
Mar 10, 2025Rapid adoption of AI technologies raises several major security concerns, including the risks of adversarial perturbations, which threaten the confidentiality and integrity of AI applications. Protecting AI hardware from misuse and diverse security threats is a challenging task. To address this challenge, we propose SAMURAI, a novel framework for safeguarding against malicious usage of AI hardware and its resilience to attacks. SAMURAI introduces an AI Performance Counter (APC) for tracking dynamic behavior of an AI model coupled with an on-chip Machine Learning (ML) analysis engine, known as TANTO (Trained Anomaly Inspection Through Trace Observation). APC records the runtime profile of the low-level hardware events of different AI operations. Subsequently, the summary information recorded by the APC is processed by TANTO to efficiently identify potential security breaches and ensure secure, responsible use of AI. SAMURAI enables real-time detection of security threats and misuse without relying on traditional software-based solutions that require model integration. Experimental results demonstrate that SAMURAI achieves up to 97% accuracy in detecting adversarial attacks with moderate overhead on various AI models, significantly outperforming conventional software-based approaches. It enhances security and regulatory compliance, providing a comprehensive solution for safeguarding AI against emergent threats.
X-DFS: Explainable Artificial Intelligence Guided Design-for-Security Solution Space Exploration
Nov 11, 2024



Design and manufacturing of integrated circuits predominantly use a globally distributed semiconductor supply chain involving diverse entities. The modern semiconductor supply chain has been designed to boost production efficiency, but is filled with major security concerns such as malicious modifications (hardware Trojans), reverse engineering (RE), and cloning. While being deployed, digital systems are also subject to a plethora of threats such as power, timing, and electromagnetic (EM) side channel attacks. Many Design-for-Security (DFS) solutions have been proposed to deal with these vulnerabilities, and such solutions (DFS) relays on strategic modifications (e.g., logic locking, side channel resilient masking, and dummy logic insertion) of the digital designs for ensuring a higher level of security. However, most of these DFS strategies lack robust formalism, are often not human-understandable, and require an extensive amount of human expert effort during their development/use. All of these factors make it difficult to keep up with the ever growing number of microelectronic vulnerabilities. In this work, we propose X-DFS, an explainable Artificial Intelligence (AI) guided DFS solution-space exploration approach that can dramatically cut down the mitigation strategy development/use time while enriching our understanding of the vulnerability by providing human-understandable decision rationale. We implement X-DFS and comprehensively evaluate it for reverse engineering threats (SAIL, SWEEP, and OMLA) and formalize a generalized mechanism for applying X-DFS to defend against other threats such as hardware Trojans, fault attacks, and side channel attacks for seamless future extensions.
Fusion Intelligence: Confluence of Natural and Artificial Intelligence for Enhanced Problem-Solving Efficiency
May 16, 2024This paper introduces Fusion Intelligence (FI), a bio-inspired intelligent system, where the innate sensing, intelligence and unique actuation abilities of biological organisms such as bees and ants are integrated with the computational power of Artificial Intelligence (AI). This interdisciplinary field seeks to create systems that are not only smart but also adaptive and responsive in ways that mimic the nature. As FI evolves, it holds the promise of revolutionizing the way we approach complex problems, leveraging the best of both biological and digital worlds to create solutions that are more effective, sustainable, and harmonious with the environment. We demonstrate FI's potential to enhance agricultural IoT system performance through a simulated case study on improving insect pollination efficacy (entomophily).
Towards Model-Size Agnostic, Compute-Free, Memorization-based Inference of Deep Learning
Jul 14, 2023The rapid advancement of deep neural networks has significantly improved various tasks, such as image and speech recognition. However, as the complexity of these models increases, so does the computational cost and the number of parameters, making it difficult to deploy them on resource-constrained devices. This paper proposes a novel memorization-based inference (MBI) that is compute free and only requires lookups. Specifically, our work capitalizes on the inference mechanism of the recurrent attention model (RAM), where only a small window of input domain (glimpse) is processed in a one time step, and the outputs from multiple glimpses are combined through a hidden vector to determine the overall classification output of the problem. By leveraging the low-dimensionality of glimpse, our inference procedure stores key value pairs comprising of glimpse location, patch vector, etc. in a table. The computations are obviated during inference by utilizing the table to read out key-value pairs and performing compute-free inference by memorization. By exploiting Bayesian optimization and clustering, the necessary lookups are reduced, and accuracy is improved. We also present in-memory computing circuits to quickly look up the matching key vector to an input query. Compared to competitive compute-in-memory (CIM) approaches, MBI improves energy efficiency by almost 2.7 times than multilayer perceptions (MLP)-CIM and by almost 83 times than ResNet20-CIM for MNIST character recognition.
Third-Party Hardware IP Assurance against Trojans through Supervised Learning and Post-processing
Nov 29, 2021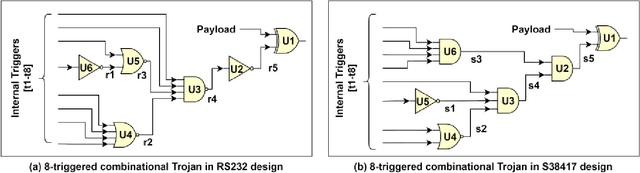

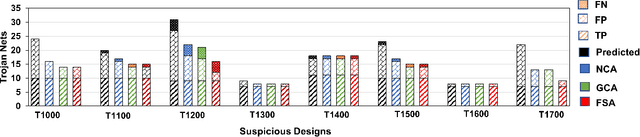

System-on-chip (SoC) developers increasingly rely on pre-verified hardware intellectual property (IP) blocks acquired from untrusted third-party vendors. These IPs might contain hidden malicious functionalities or hardware Trojans to compromise the security of the fabricated SoCs. Recently, supervised machine learning (ML) techniques have shown promising capability in identifying nets of potential Trojans in third party IPs (3PIPs). However, they bring several major challenges. First, they do not guide us to an optimal choice of features that reliably covers diverse classes of Trojans. Second, they require multiple Trojan-free/trusted designs to insert known Trojans and generate a trained model. Even if a set of trusted designs are available for training, the suspect IP could be inherently very different from the set of trusted designs, which may negatively impact the verification outcome. Third, these techniques only identify a set of suspect Trojan nets that require manual intervention to understand the potential threat. In this paper, we present VIPR, a systematic machine learning (ML) based trust verification solution for 3PIPs that eliminates the need for trusted designs for training. We present a comprehensive framework, associated algorithms, and a tool flow for obtaining an optimal set of features, training a targeted machine learning model, detecting suspect nets, and identifying Trojan circuitry from the suspect nets. We evaluate the framework on several Trust-Hub Trojan benchmarks and provide a comparative analysis of detection performance across different trained models, selection of features, and post-processing techniques. The proposed post-processing algorithms reduce false positives by up to 92.85%.