 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Domain Knowledge using Machine Learning for Image Compression in Internet-of-Things
Paper and Code
Sep 14, 2020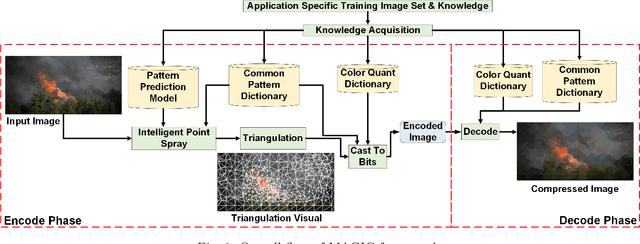

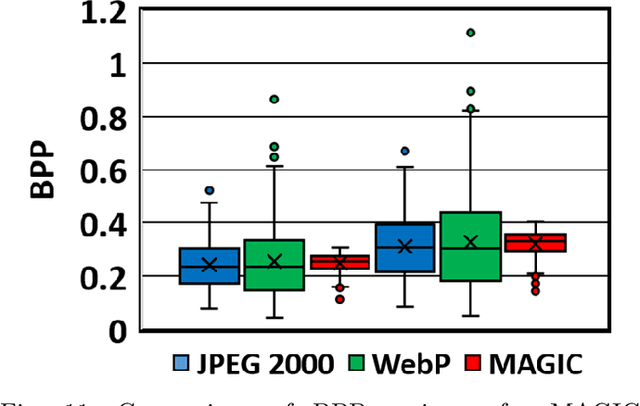
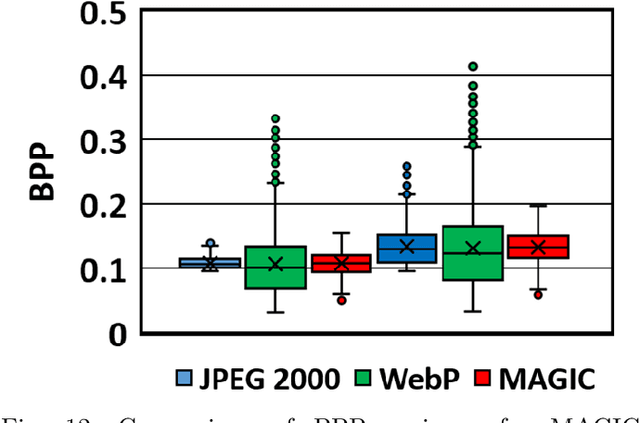
The emergent ecosystems of intelligent edge devices in diverse Internet of Things (IoT) applications, from automatic surveillance to precision agriculture, increasingly rely on recording and processing variety of image data. Due to resource constraints, e.g., energy and communication bandwidth requirements, these applications require compressing the recorded images before transmission. For these applications, image compression commonly requires: (1) maintaining features for coarse-grain pattern recognition instead of the high-level details for human perception due to machine-to-machine communications; (2) high compression ratio that leads to improved energy and transmission efficiency; (3) large dynamic range of compression and an easy trade-off between compression factor and quality of reconstruction to accommodate a wide diversity of IoT applications as well as their time-varying energy/performance needs. To address these requirements, we propose, MAGIC, a novel machine learning (ML) guided image compression framework that judiciously sacrifices visual quality to achieve much higher compression when compared to traditional techniques, while maintaining accuracy for coarse-grained vision tasks. The central idea is to capture application-specific domain knowledge and efficiently utilize it in achieving high compression. We demonstrate that the MAGIC framework is configurable across a wide range of compression/quality and is capable of compressing beyond the standard quality factor limits of both JPEG 2000 and WebP. We perform experiments on representative IoT applications using two vision datasets and show up to 42.65x compression at similar accuracy with respect to the source. We highlight low variance in compression rate across images using our technique as compared to JPEG 2000 and WebP.