 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Convergence and Generalization of Dropout Training
Oct 23, 2020

We study dropout in two-layer neural networks with rectified linear unit (ReLU) activations. Under mild overparametrization and assuming that the limiting kernel can separate the data distribution with a positive margin, we show that dropout training with logistic loss achieves $\epsilon$-suboptimality in test error in $O(1/\epsilon)$ iterations.
Dropout: Explicit Forms and Capacity Control
Mar 06, 2020

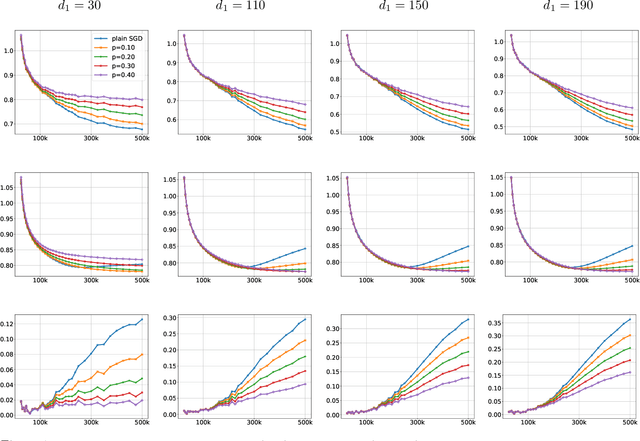
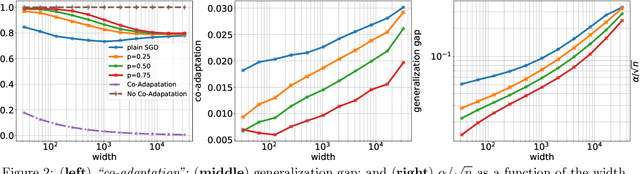
We investigate the capacity control provided by dropout in various machine learning problems. First, we study dropout for matrix completion, where it induces a data-dependent regularizer that, in expectation, equals the weighted trace-norm of the product of the factors. In deep learning, we show that the data-dependent regularizer due to dropout directly controls the Rademacher complexity of the underlying class of deep neural networks. These developments enable us to give concrete generalization error bounds for the dropout algorithm in both matrix completion as well as training deep neural networks. We evaluate our theoretical findings on real-world datasets, including MovieLens, MNIST, and Fashion-MNIST.
On Dropout and Nuclear Norm Regularization
May 28, 2019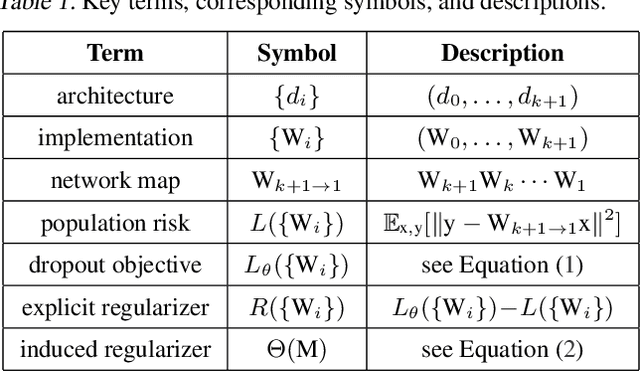
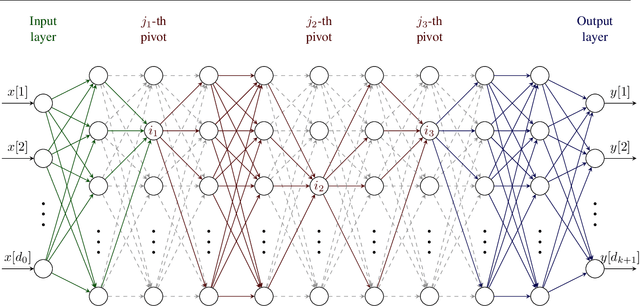
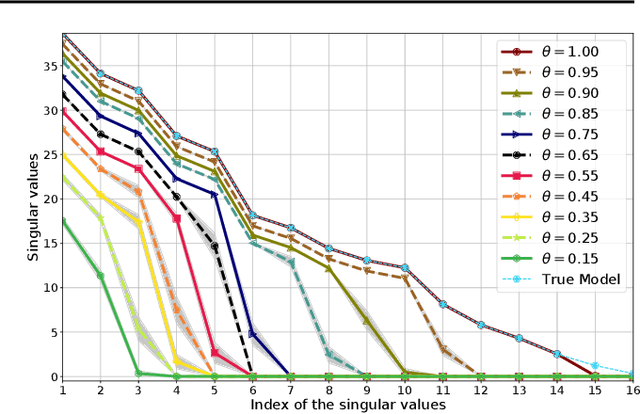
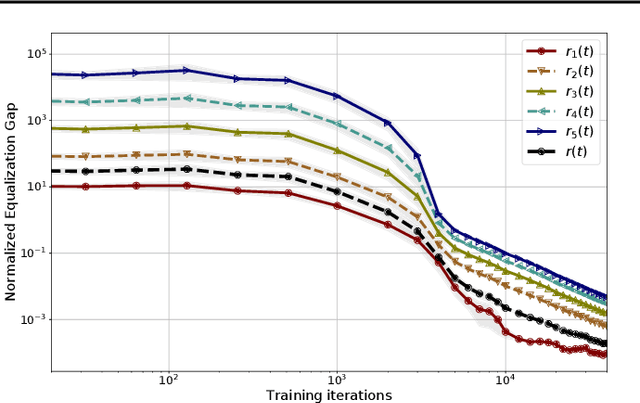
We give a formal and complete characterization of the explicit regularizer induced by dropout in deep linear networks with squared loss. We show that (a) the explicit regularizer is composed of an $\ell_2$-path regularizer and other terms that are also re-scaling invariant, (b) the convex envelope of the induced regularizer is the squared nuclear norm of the network map, and (c) for a sufficiently large dropout rate, we characterize the global optima of the dropout objective. We validate our theoretical findings with empirical results.
Streaming Kernel PCA with $\tilde{O}$ Random Features
Aug 02, 2018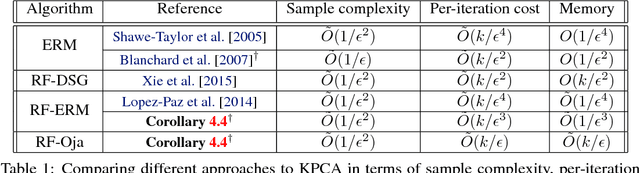
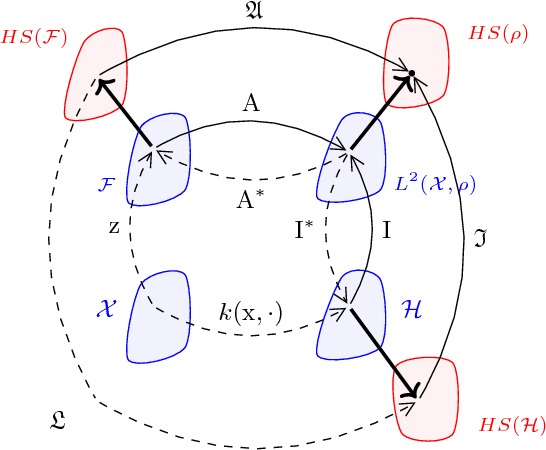
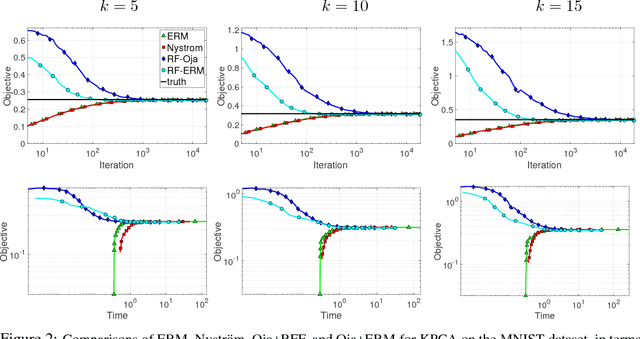

We study the statistical and computational aspects of kernel principal component analysis using random Fourier features and show that under mild assumptions, $O(\sqrt{n} \log n)$ features suffices to achieve $O(1/\epsilon^2)$ sample complexity. Furthermore, we give a memory efficient streaming algorithm based on classical Oja's algorithm that achieves this rate.
On the Implicit Bias of Dropout
Jun 26, 2018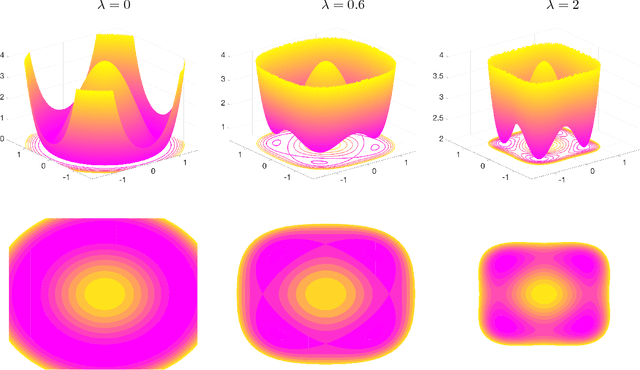
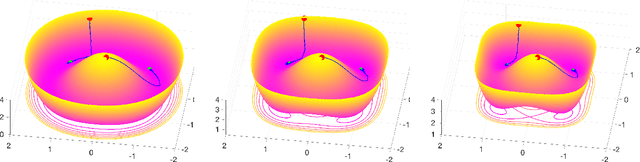

Algorithmic approaches endow deep learning systems with implicit bias that helps them generalize even in over-parametrized settings. In this paper, we focus on understanding such a bias induced in learning through dropout, a popular technique to avoid overfitting in deep learning. For single hidden-layer linear neural networks, we show that dropout tends to make the norm of incoming/outgoing weight vectors of all the hidden nodes equal. In addition, we provide a complete characterization of the optimization landscape induced by dropout.
Understanding Deep Neural Networks with Rectified Linear Units
Feb 28, 2018
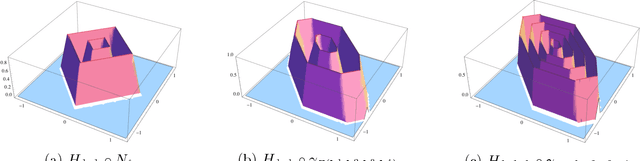
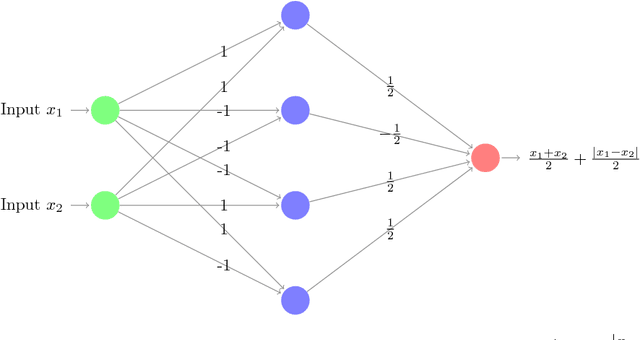
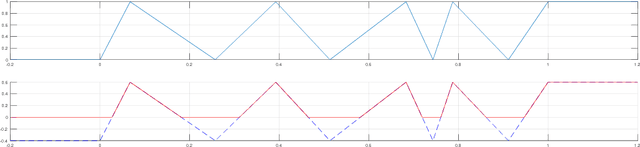
In this paper we investigate the family of functions representable by deep neural networks (DNN) with rectified linear units (ReLU). We give an algorithm to train a ReLU DNN with one hidden layer to *global optimality* with runtime polynomial in the data size albeit exponential in the input dimension. Further, we improve on the known lower bounds on size (from exponential to super exponential) for approximating a ReLU deep net function by a shallower ReLU net. Our gap theorems hold for smoothly parametrized families of "hard" functions, contrary to countable, discrete families known in the literature. An example consequence of our gap theorems is the following: for every natural number $k$ there exists a function representable by a ReLU DNN with $k^2$ hidden layers and total size $k^3$, such that any ReLU DNN with at most $k$ hidden layers will require at least $\frac{1}{2}k^{k+1}-1$ total nodes. Finally, for the family of $\mathbb{R}^n\to \mathbb{R}$ DNNs with ReLU activations, we show a new lowerbound on the number of affine pieces, which is larger than previous constructions in certain regimes of the network architecture and most distinctively our lowerbound is demonstrated by an explicit construction of a *smoothly parameterized* family of functions attaining this scaling. Our construction utilizes the theory of zonotopes from polyhedral theory.
* The poly(data) exact training algorithm has been improved to now be applicable to any single hidden layer R^n-> R ReLU DNN and there is a cleaner pseudocode for it given on page 8. Also now on page 7 there is a more precise description about when and how the Zonotope construction improves on the Theorem 4 of this paper, arXiv:1402.1869
Stochastic Approximation for Canonical Correlation Analysis
Feb 26, 2018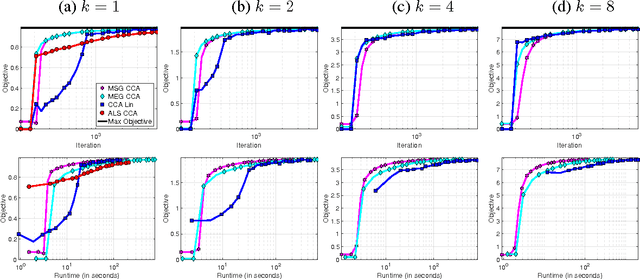
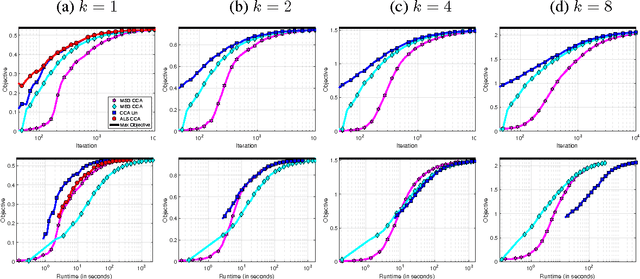
We propose novel first-order stochastic approximation algorithms for canonical correlation analysis (CCA). Algorithms presented are instances of inexact matrix stochastic gradient (MSG) and inexact matrix exponentiated gradient (MEG), and achieve $\epsilon$-suboptimality in the population objective in $\operatorname{poly}(\frac{1}{\epsilon})$ iterations. We also consider practical variants of the proposed algorithms and compare them with other methods for CCA both theoretically and empirically.