 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Instructed Retrieval Models Really Support Exploration?
Jan 16, 2026Exploratory searches are characterized by under-specified goals and evolving query intents. In such scenarios, retrieval models that can capture user-specified nuances in query intent and adapt results accordingly are desirable -- instruction-following retrieval models promise such a capability. In this work, we evaluate instructed retrievers for the prevalent yet under-explored application of aspect-conditional seed-guided exploration using an expert-annotated test collection. We evaluate both recent LLMs fine-tuned for instructed retrieval and general-purpose LLMs prompted for ranking with the highly performant Pairwise Ranking Prompting. We find that the best instructed retrievers improve on ranking relevance compared to instruction-agnostic approaches. However, we also find that instruction following performance, crucial to the user experience of interacting with models, does not mirror ranking relevance improvements and displays insensitivity or counter-intuitive behavior to instructions. Our results indicate that while users may benefit from using current instructed retrievers over instruction-agnostic models, they may not benefit from using them for long-running exploratory sessions requiring greater sensitivity to instructions.
NxtPost: User to Post Recommendations in Facebook Groups
Feb 08, 2022

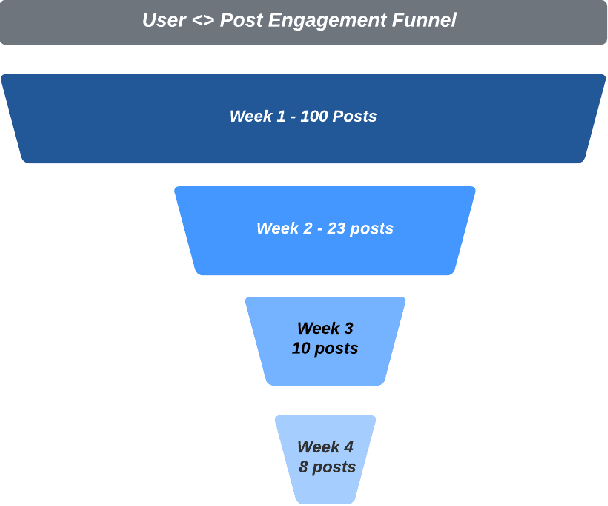

In this paper, we present NxtPost, a deployed user-to-post content-based sequential recommender system for Facebook Groups. Inspired by recent advances in NLP, we have adapted a Transformer-based model to the domain of sequential recommendation. We explore causal masked multi-head attention that optimizes both short and long-term user interests. From a user's past activities validated by defined safety process, NxtPost seeks to learn a representation for the user's dynamic content preference and to predict the next post user may be interested in. In contrast to previous Transformer-based methods, we do not assume that the recommendable posts have a fixed corpus. Accordingly, we use an external item/token embedding to extend a sequence-based approach to a large vocabulary. We achieve 49% abs. improvement in offline evaluation. As a result of NxtPost deployment, 0.6% more users are meeting new people, engaging with the community, sharing knowledge and getting support. The paper shares our experience in developing a personalized sequential recommender system, lessons deploying the model for cold start users, how to deal with freshness, and tuning strategies to reach higher efficiency in online A/B experiments.
ML-Based Analysis to Identify Speech Features Relevant in Predicting Alzheimer's Disease
Oct 25, 2021
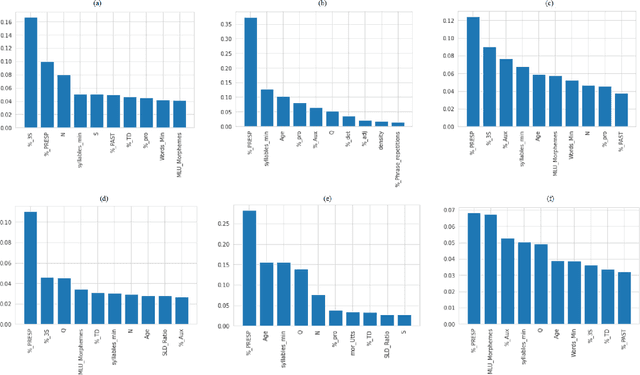

Alzheimer's disease (AD) is a neurodegenerative disease that affects nearly 50 million individuals across the globe and is one of the leading causes of deaths globally. It is projected that by 2050, the number of people affected by the disease would more than double. Consequently, the growing advancements in technology beg the question, can technology be used to predict Alzheimer's for a better and early diagnosis? In this paper, we focus on this very problem. Specifically, we have trained both ML models and neural networks to predict and classify participants based on their speech patterns. We computed a number of linguistic variables using DementiaBank's Pitt Corpus, a database consisting of transcripts of interviews with subjects suffering from multiple neurodegenerative diseases. We then trained both binary classifiers, as well as multiclass classifiers to distinguish AD from normal aging and other neurodegenerative diseases. We also worked on establishing the link between specific speech factors that can help determine the onset of AD. Confusion matrices and feature importance graphs have been plotted model-wise to compare the performances of our models. In both multiclass and binary classification, neural networks were found to outperform the other models with a testing accuracy of 76.44% and 92.05% respectively. For the feature importance, it was concluded that '%_PRESP' (present participle), '%_3S' (3rd person present tense markers) were two of the most important speech features for our classifiers in predicting AD.