 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-Based Analysis to Identify Speech Features Relevant in Predicting Alzheimer's Disease
Oct 25, 2021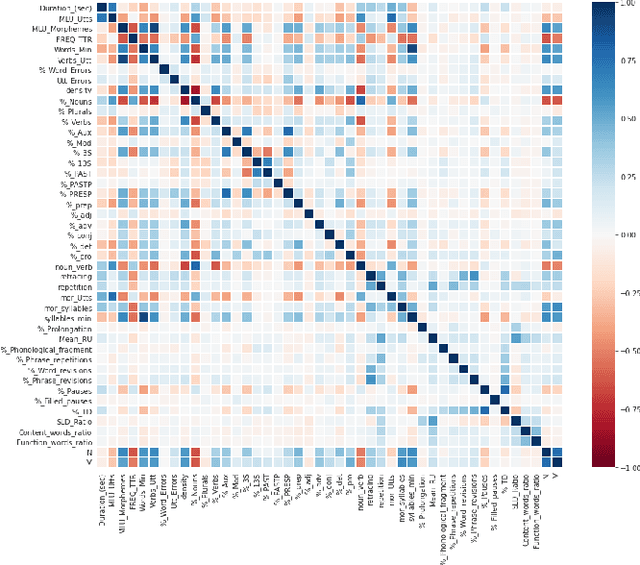
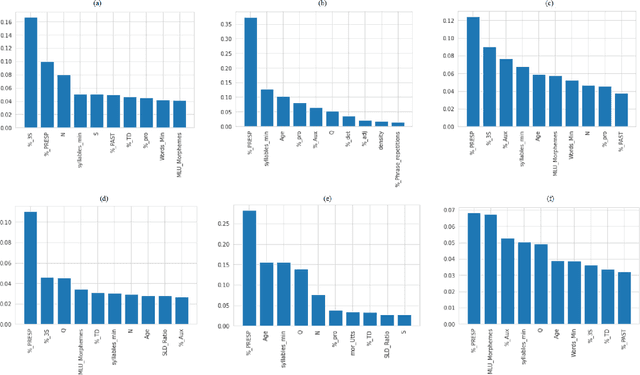

Alzheimer's disease (AD) is a neurodegenerative disease that affects nearly 50 million individuals across the globe and is one of the leading causes of deaths globally. It is projected that by 2050, the number of people affected by the disease would more than double. Consequently, the growing advancements in technology beg the question, can technology be used to predict Alzheimer's for a better and early diagnosis? In this paper, we focus on this very problem. Specifically, we have trained both ML models and neural networks to predict and classify participants based on their speech patterns. We computed a number of linguistic variables using DementiaBank's Pitt Corpus, a database consisting of transcripts of interviews with subjects suffering from multiple neurodegenerative diseases. We then trained both binary classifiers, as well as multiclass classifiers to distinguish AD from normal aging and other neurodegenerative diseases. We also worked on establishing the link between specific speech factors that can help determine the onset of AD. Confusion matrices and feature importance graphs have been plotted model-wise to compare the performances of our models. In both multiclass and binary classification, neural networks were found to outperform the other models with a testing accuracy of 76.44% and 92.05% respectively. For the feature importance, it was concluded that '%_PRESP' (present participle), '%_3S' (3rd person present tense markers) were two of the most important speech features for our classifiers in predicting AD.
Age and Gender Prediction using Deep CNNs and Transfer Learning
Oct 25, 2021

The last decade or two has witnessed a boom of images. With the increasing ubiquity of cameras and with the advent of selfies, the number of facial images available in the world has skyrocketed. Consequently, there has been a growing interest in automatic age and gender prediction of a person using facial images. We in this paper focus on this challenging problem. Specifically, this paper focuses on age estimation, age classification and gender classification from still facial images of an individual. We train different models for each problem and we also draw comparisons between building a custom CNN (Convolutional Neural Network) architecture and using various CNN architectures as feature extractors, namely VGG16 pre-trained on VGGFace, Res-Net50 and SE-ResNet50 pre-trained on VGGFace2 dataset and training over those extracted features. We also provide baseline performance of various machine learning algorithms on the feature extraction which gave us the best results. It was observed that even simple linear regression trained on such extracted features outperformed training CNN, ResNet50 and ResNeXt50 from scratch for age estimation.
* 12 pages, 2 figures, 11 tables
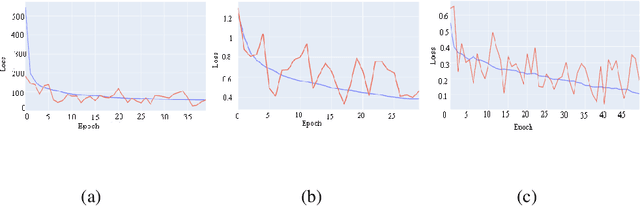
Deep Neural Networks on EEG Signals to Predict Auditory Attention Score Using Gramian Angular Difference Field
Oct 24, 2021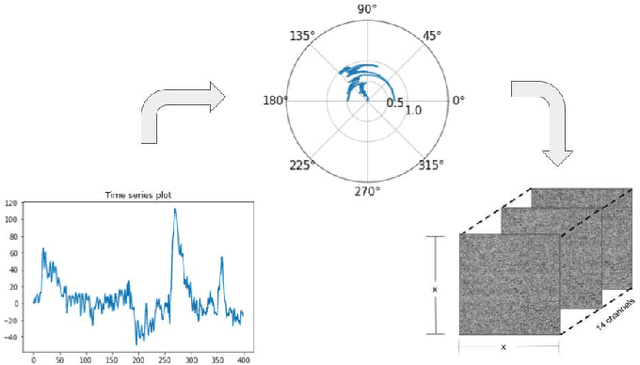
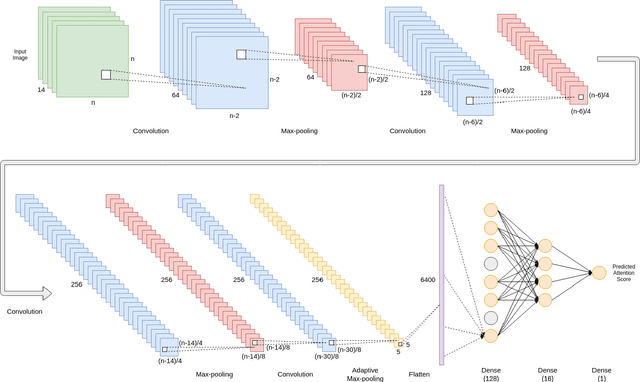
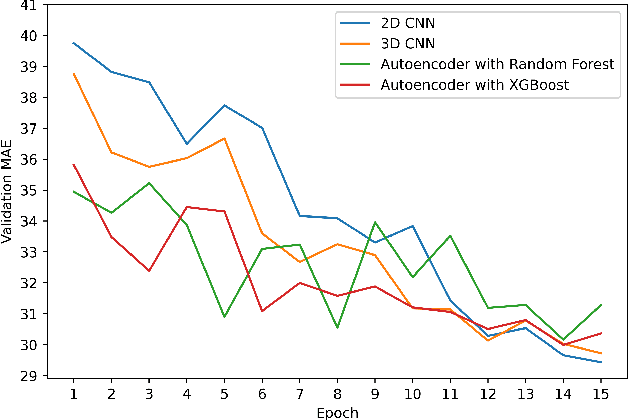

Auditory attention is a selective type of hearing in which people focus their attention intentionally on a specific source of a sound or spoken words whilst ignoring or inhibiting other auditory stimuli. In some sense, the auditory attention score of an individual shows the focus the person can have in auditory tasks. The recent advancements in deep learning and in the non-invasive technologies recording neural activity beg the question, can deep learning along with technologies such as electroencephalography (EEG) be used to predict the auditory attention score of an individual? In this paper, we focus on this very problem of estimating a person's auditory attention level based on their brain's electrical activity captured using 14-channeled EEG signals. More specifically, we deal with attention estimation as a regression problem. The work has been performed on the publicly available Phyaat dataset. The concept of Gramian Angular Difference Field (GADF) has been used to convert time-series EEG data into an image having 14 channels, enabling us to train various deep learning models such as 2D CNN, 3D CNN, and convolutional autoencoders. Their performances have been compared amongst themselves as well as with the work done previously. Amongst the different models we tried, 2D CNN gave the best performance. It outperformed the existing methods by a decent margin of 0.22 mean absolute error (MAE).