 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-Based Analysis to Identify Speech Features Relevant in Predicting Alzheimer's Disease
Paper and Code
Oct 25, 2021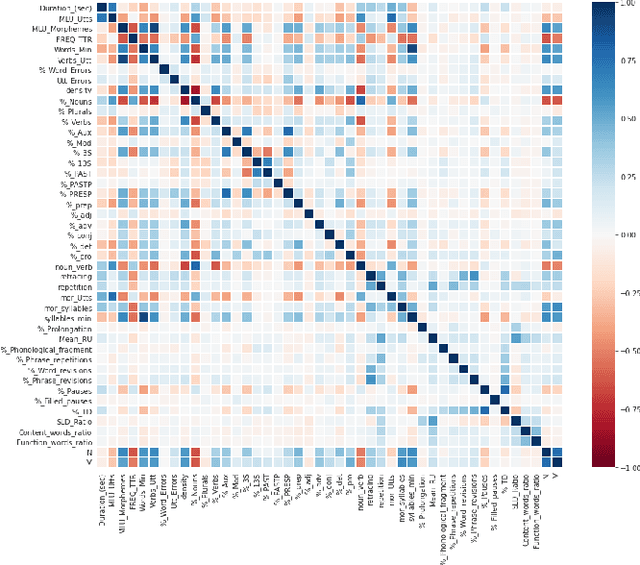
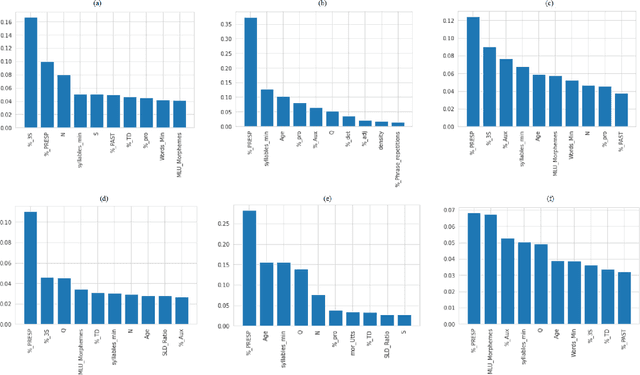
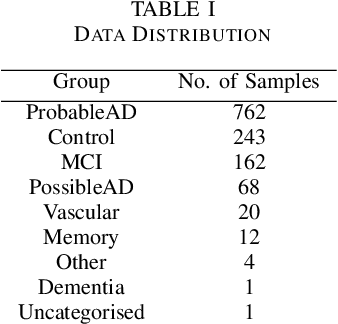

Alzheimer's disease (AD) is a neurodegenerative disease that affects nearly 50 million individuals across the globe and is one of the leading causes of deaths globally. It is projected that by 2050, the number of people affected by the disease would more than double. Consequently, the growing advancements in technology beg the question, can technology be used to predict Alzheimer's for a better and early diagnosis? In this paper, we focus on this very problem. Specifically, we have trained both ML models and neural networks to predict and classify participants based on their speech patterns. We computed a number of linguistic variables using DementiaBank's Pitt Corpus, a database consisting of transcripts of interviews with subjects suffering from multiple neurodegenerative diseases. We then trained both binary classifiers, as well as multiclass classifiers to distinguish AD from normal aging and other neurodegenerative diseases. We also worked on establishing the link between specific speech factors that can help determine the onset of AD. Confusion matrices and feature importance graphs have been plotted model-wise to compare the performances of our models. In both multiclass and binary classification, neural networks were found to outperform the other models with a testing accuracy of 76.44% and 92.05% respectively. For the feature importance, it was concluded that '%_PRESP' (present participle), '%_3S' (3rd person present tense markers) were two of the most important speech features for our classifiers in predicting AD.