 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: AI Competitions Provide the Gold Standard for Empirical Rigor in GenAI Evaluation
May 01, 2025In this position paper, we observe that empirical evaluation in Generative AI is at a crisis point since traditional ML evaluation and benchmarking strategies are insufficient to meet the needs of evaluating modern GenAI models and systems. There are many reasons for this, including the fact that these models typically have nearly unbounded input and output spaces, typically do not have a well defined ground truth target, and typically exhibit strong feedback loops and prediction dependence based on context of previous model outputs. On top of these critical issues, we argue that the problems of {\em leakage} and {\em contamination} are in fact the most important and difficult issues to address for GenAI evaluations. Interestingly, the field of AI Competitions has developed effective measures and practices to combat leakage for the purpose of counteracting cheating by bad actors within a competition setting. This makes AI Competitions an especially valuable (but underutilized) resource. Now is time for the field to view AI Competitions as the gold standard for empirical rigor in GenAI evaluation, and to harness and harvest their results with according value.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Predicting Severe Sepsis Using Text from the Electronic Health Record
Nov 30, 2017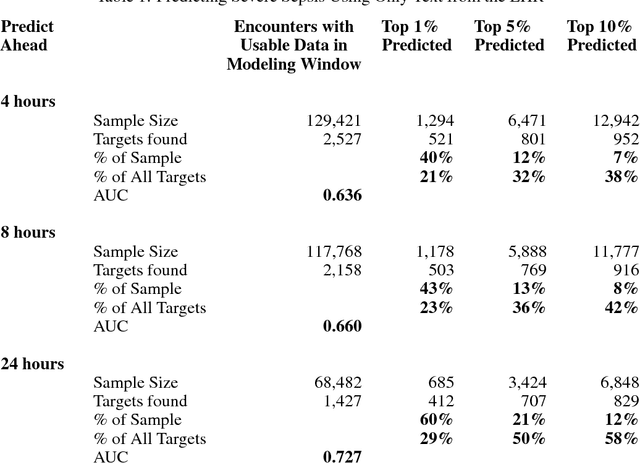
Employing a machine learning approach we predict, up to 24 hours prior, a diagnosis of severe sepsis. Strongly predictive models are possible that use only text reports from the Electronic Health Record (EHR), and omit structured numerical data. Unstructured text alone gives slightly better performance than structured data alone, and the combination further improves performance. We also discuss advantages of using unstructured EHR text for modeling, as compared to structured EHR data.