 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseLIF: High-Performance Sparse LiDAR-Camera Fusion for 3D Object Detection
Mar 12, 2024Sparse 3D detectors have received significant attention since the query-based paradigm embraces low latency without explicit dense BEV feature construction. However, these detectors achieve worse performance than their dense counterparts. In this paper, we find the key to bridging the performance gap is to enhance the awareness of rich representations in two modalities. Here, we present a high-performance fully sparse detector for end-to-end multi-modality 3D object detection. The detector, termed SparseLIF, contains three key designs, which are (1) Perspective-Aware Query Generation (PAQG) to generate high-quality 3D queries with perspective priors, (2) RoI-Aware Sampling (RIAS) to further refine prior queries by sampling RoI features from each modality, (3) Uncertainty-Aware Fusion (UAF) to precisely quantify the uncertainty of each sensor modality and adaptively conduct final multi-modality fusion, thus achieving great robustness against sensor noises. By the time of submission (2024/03/08), SparseLIF achieves state-of-the-art performance on the nuScenes dataset, ranking 1st on both validation set and test benchmark, outperforming all state-of-the-art 3D object detectors by a notable margin. The source code will be released upon acceptance.
Semantic Invariant Multi-view Clustering with Fully Incomplete Information
May 22, 2023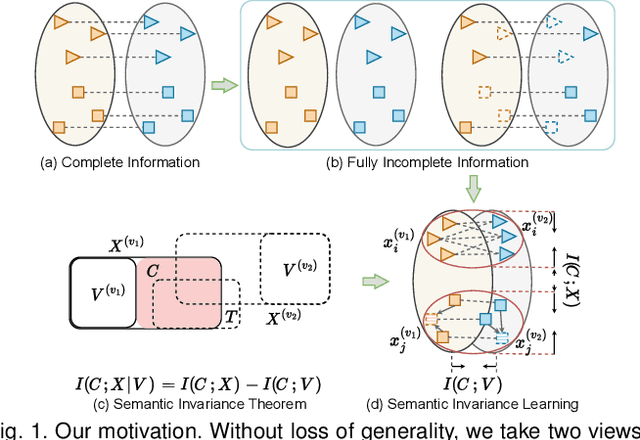
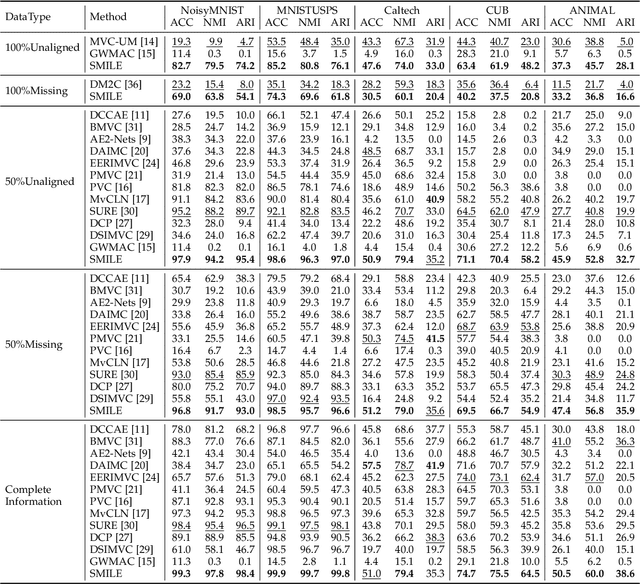
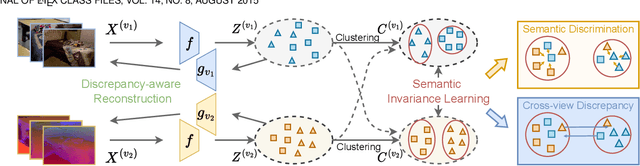
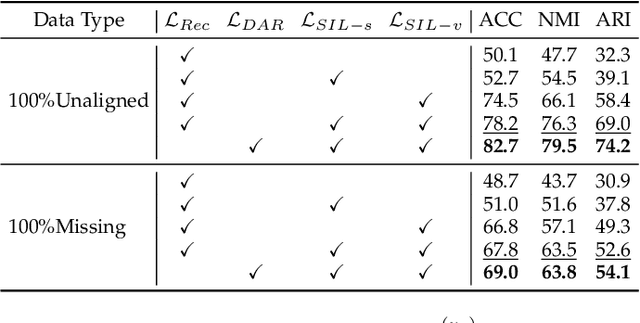
Robust multi-view learning with incomplete information has received significant attention due to issues such as incomplete correspondences and incomplete instances that commonly affect real-world multi-view applications. Existing approaches heavily rely on paired samples to realign or impute defective ones, but such preconditions cannot always be satisfied in practice due to the complexity of data collection and transmission. To address this problem, we present a novel framework called SeMantic Invariance LEarning (SMILE) for multi-view clustering with incomplete information that does not require any paired samples. To be specific, we discover the existence of invariant semantic distribution across different views, which enables SMILE to alleviate the cross-view discrepancy to learn consensus semantics without requiring any paired samples. The resulting consensus semantics remains unaffected by cross-view distribution shifts, making them useful for realigning/imputing defective instances and forming clusters. We demonstrate the effectiveness of SMILE through extensive comparison experiments with 13 state-of-the-art baselines on five benchmarks. Our approach improves the clustering accuracy of NoisyMNIST from 19.3\%/23.2\% to 82.7\%/69.0\% when the correspondences/instances are fully incomplete. We will release the code after acceptance.
Deep Fair Clustering via Maximizing and Minimizing Mutual Information
Sep 26, 2022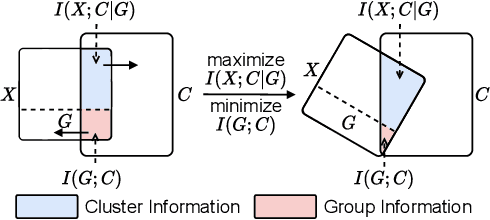
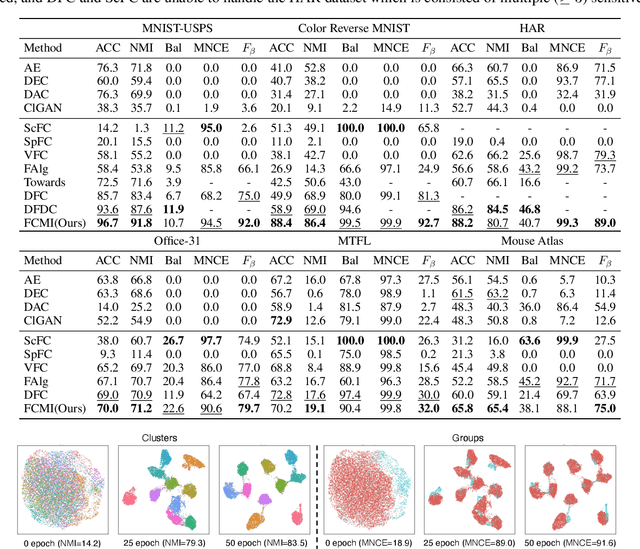
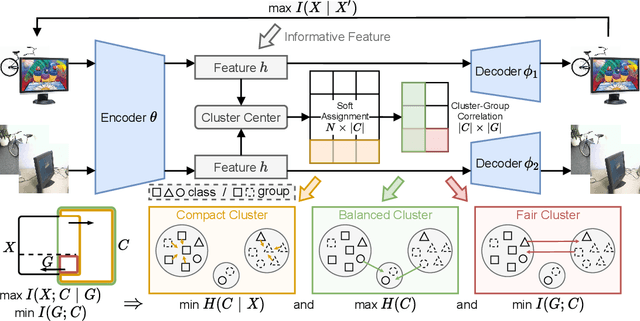
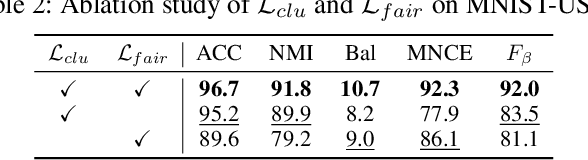
Fair clustering aims to divide data into distinct clusters, while preventing sensitive attributes (e.g., gender, race, RNA sequencing technique) from dominating the clustering. Although a number of works have been conducted and achieved huge success in recent, most of them are heuristical, and there lacks a unified theory for algorithm design. In this work, we fill this blank by developing a mutual information theory for deep fair clustering and accordingly designing a novel algorithm, dubbed FCMI. In brief, through maximizing and minimizing mutual information, FCMI is designed to achieve four characteristics highly expected by deep fair clustering, i.e., compact, balanced, and fair clusters, as well as informative features. Besides the contributions to theory and algorithm, another contribution of this work is proposing a novel fair clustering metric built upon information theory as well. Unlike existing evaluation metrics, our metric measures the clustering quality and fairness in a whole instead of separate manner. To verify the effectiveness of the proposed FCMI, we carry out experiments on six benchmarks including a single-cell RNA-seq atlas compared with 11 state-of-the-art methods in terms of five metrics. Code will be released after the acceptance.