 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothing Structured Decomposable Circuits
Jun 01, 2019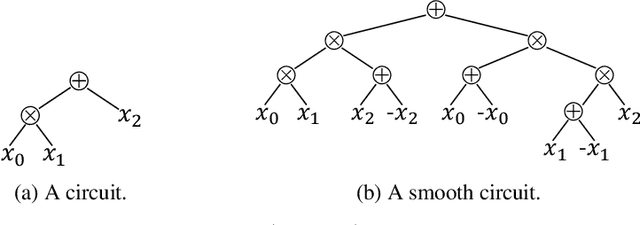

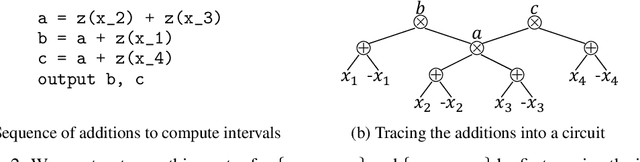

We study the task of smoothing a circuit, i.e., ensuring that all children of a plus-gate mention the same variables. Circuits serve as the building blocks of state-of-the-art inference algorithms on discrete probabilistic graphical models and probabilistic programs. They are also important for discrete density estimation algorithms. Many of these tasks require the input circuit to be smooth. However, smoothing has not been studied in its own right yet, and only a trivial quadratic algorithm is known. This paper studies efficient smoothing for structured decomposable circuits. We propose a near-linear time algorithm for this task and explore lower bounds for smoothing general circuits, using existing results on range-sum queries. Further, for the important special case of All-Marginals, we show a more efficient linear-time algorithm. We validate experimentally the performance of our methods.
Time-Space Tradeoffs for Learning from Small Test Spaces: Learning Low Degree Polynomial Functions
Aug 08, 2017We develop an extension of recently developed methods for obtaining time-space tradeoff lower bounds for problems of learning from random test samples to handle the situation where the space of tests is signficantly smaller than the space of inputs, a class of learning problems that is not handled by prior work. This extension is based on a measure of how matrices amplify the 2-norms of probability distributions that is more refined than the 2-norms of these matrices. As applications that follow from our new technique, we show that any algorithm that learns $m$-variate homogeneous polynomial functions of degree at most $d$ over $\mathbb{F}_2$ from evaluations on randomly chosen inputs either requires space $\Omega(mn)$ or $2^{\Omega(m)}$ time where $n=m^{\Theta(d)}$ is the dimension of the space of such functions. These bounds are asymptotically optimal since they match the tradeoffs achieved by natural learning algorithms for the problems.
New Limits for Knowledge Compilation and Applications to Exact Model Counting
Aug 19, 2015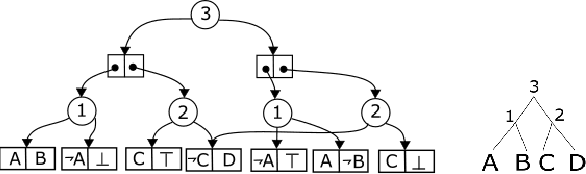


We show new limits on the efficiency of using current techniques to make exact probabilistic inference for large classes of natural problems. In particular we show new lower bounds on knowledge compilation to SDD and DNNF forms. We give strong lower bounds on the complexity of SDD representations by relating SDD size to best-partition communication complexity. We use this relationship to prove exponential lower bounds on the SDD size for representing a large class of problems that occur naturally as queries over probabilistic databases. A consequence is that for representing unions of conjunctive queries, SDDs are not qualitatively more concise than OBDDs. We also derive simple examples for which SDDs must be exponentially less concise than FBDDs. Finally, we derive exponential lower bounds on the sizes of DNNF representations using a new quasipolynomial simulation of DNNFs by nondeterministic FBDDs.
Symmetric Weighted First-Order Model Counting
Jun 01, 2015

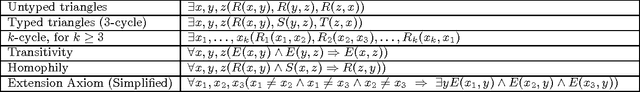
The FO Model Counting problem (FOMC) is the following: given a sentence $\Phi$ in FO and a number $n$, compute the number of models of $\Phi$ over a domain of size $n$; the Weighted variant (WFOMC) generalizes the problem by associating a weight to each tuple and defining the weight of a model to be the product of weights of its tuples. In this paper we study the complexity of the symmetric WFOMC, where all tuples of a given relation have the same weight. Our motivation comes from an important application, inference in Knowledge Bases with soft constraints, like Markov Logic Networks, but the problem is also of independent theoretical interest. We study both the data complexity, and the combined complexity of FOMC and WFOMC. For the data complexity we prove the existence of an FO$^{3}$ formula for which FOMC is #P$_1$-complete, and the existence of a Conjunctive Query for which WFOMC is #P$_1$-complete. We also prove that all $\gamma$-acyclic queries have polynomial time data complexity. For the combined complexity, we prove that, for every fragment FO$^{k}$, $k\geq 2$, the combined complexity of FOMC (or WFOMC) is #P-complete.
Lower Bounds for Exact Model Counting and Applications in Probabilistic Databases
Sep 26, 2013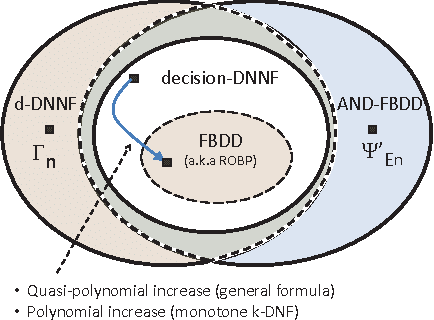
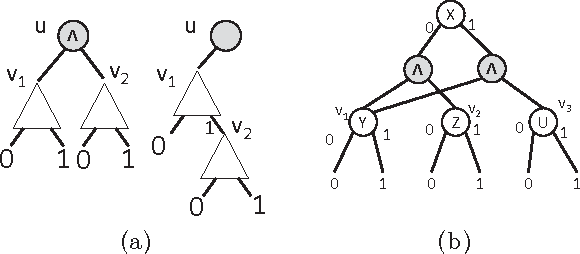
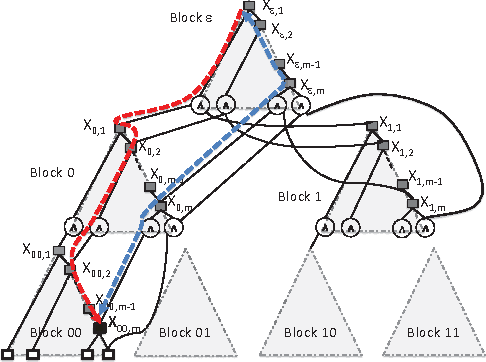

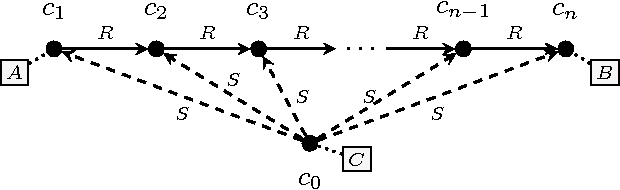
The best current methods for exactly computing the number of satisfying assignments, or the satisfying probability, of Boolean formulas can be seen, either directly or indirectly, as building 'decision-DNNF' (decision decomposable negation normal form) representations of the input Boolean formulas. Decision-DNNFs are a special case of 'd-DNNF's where 'd' stands for 'deterministic'. We show that any decision-DNNF can be converted into an equivalent 'FBDD' (free binary decision diagram) -- also known as a 'read-once branching program' (ROBP or 1-BP) -- with only a quasipolynomial increase in representation size in general, and with only a polynomial increase in size in the special case of monotone k-DNF formulas. Leveraging known exponential lower bounds for FBDDs, we then obtain similar exponential lower bounds for decision-DNNFs which provide lower bounds for the recent algorithms. We also separate the power of decision-DNNFs from d-DNNFs and a generalization of decision-DNNFs known as AND-FBDDs. Finally we show how these imply exponential lower bounds for natural problems associated with probabilistic databases.