 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rhythm In Anything: Audio-Prompted Drums Generation with Masked Language Modeling
Sep 19, 2025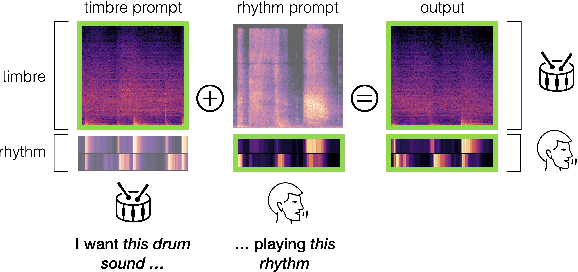
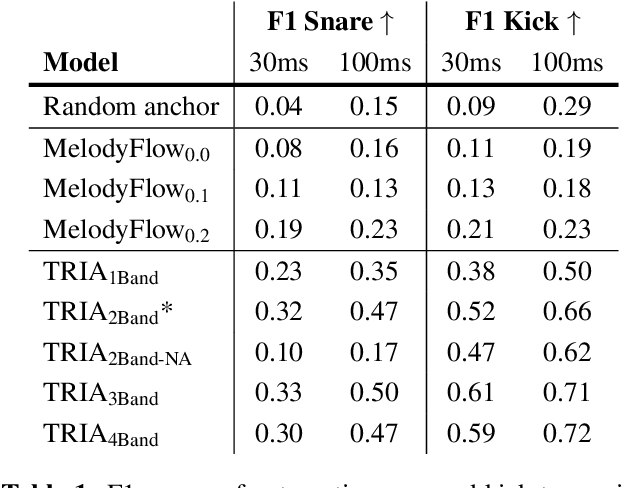
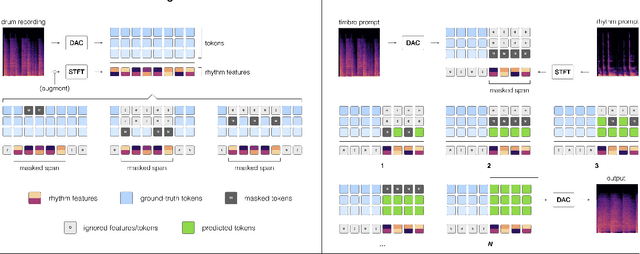
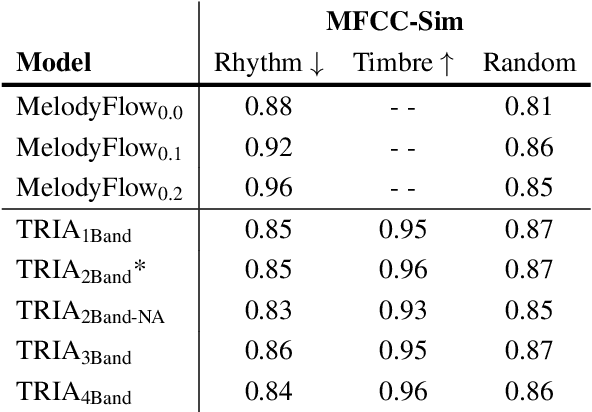
Musicians and nonmusicians alike use rhythmic sound gestures, such as tapping and beatboxing, to express drum patterns. While these gestures effectively communicate musical ideas, realizing these ideas as fully-produced drum recordings can be time-consuming, potentially disrupting many creative workflows. To bridge this gap, we present TRIA (The Rhythm In Anything), a masked transformer model for mapping rhythmic sound gestures to high-fidelity drum recordings. Given an audio prompt of the desired rhythmic pattern and a second prompt to represent drumkit timbre, TRIA produces audio of a drumkit playing the desired rhythm (with appropriate elaborations) in the desired timbre. Subjective and objective evaluations show that a TRIA model trained on less than 10 hours of publicly-available drum data can generate high-quality, faithful realizations of sound gestures across a wide range of timbres in a zero-shot manner.
Deep Audio Watermarks are Shallow: Limitations of Post-Hoc Watermarking Techniques for Speech
Apr 15, 2025In the audio modality, state-of-the-art watermarking methods leverage deep neural networks to allow the embedding of human-imperceptible signatures in generated audio. The ideal is to embed signatures that can be detected with high accuracy when the watermarked audio is altered via compression, filtering, or other transformations. Existing audio watermarking techniques operate in a post-hoc manner, manipulating "low-level" features of audio recordings after generation (e.g. through the addition of a low-magnitude watermark signal). We show that this post-hoc formulation makes existing audio watermarks vulnerable to transformation-based removal attacks. Focusing on speech audio, we (1) unify and extend existing evaluations of the effect of audio transformations on watermark detectability, and (2) demonstrate that state-of-the-art post-hoc audio watermarks can be removed with no knowledge of the watermarking scheme and minimal degradation in audio quality.
HARP 2.0: Expanding Hosted, Asynchronous, Remote Processing for Deep Learning in the DAW
Mar 04, 2025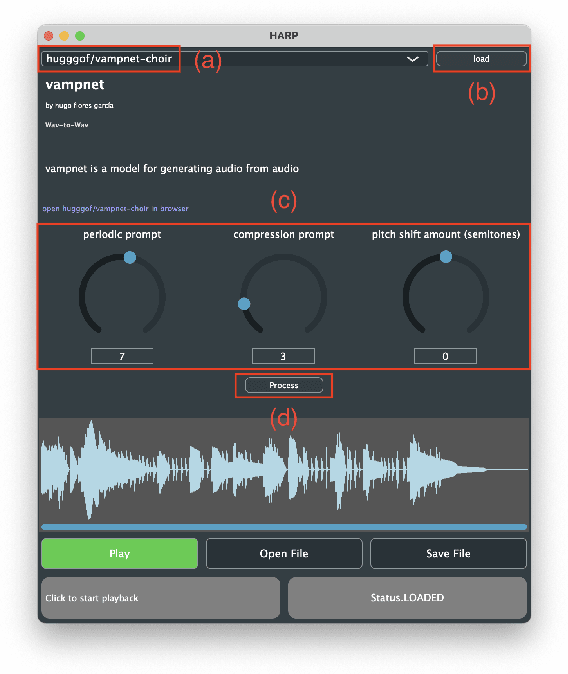
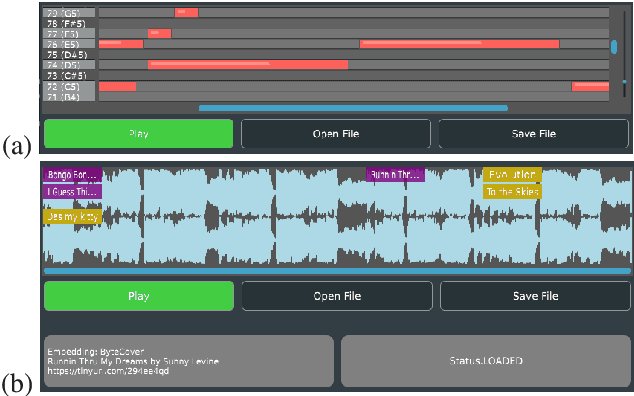
HARP 2.0 brings deep learning models to digital audio workstation (DAW) software through hosted, asynchronous, remote processing, allowing users to route audio from a plug-in interface through any compatible Gradio endpoint to perform arbitrary transformations. HARP renders endpoint-defined controls and processed audio in-plugin, meaning users can explore a variety of cutting-edge deep learning models without ever leaving the DAW. In the 2.0 release we introduce support for MIDI-based models and audio/MIDI labeling models, provide a streamlined pyharp Python API for model developers, and implement numerous interface and stability improvements. Through this work, we hope to bridge the gap between model developers and creatives, improving access to deep learning models by seamlessly integrating them into DAW workflows.
Code Drift: Towards Idempotent Neural Audio Codecs
Oct 14, 2024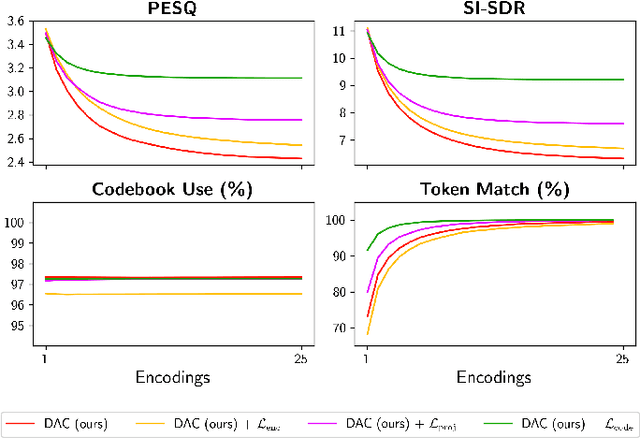
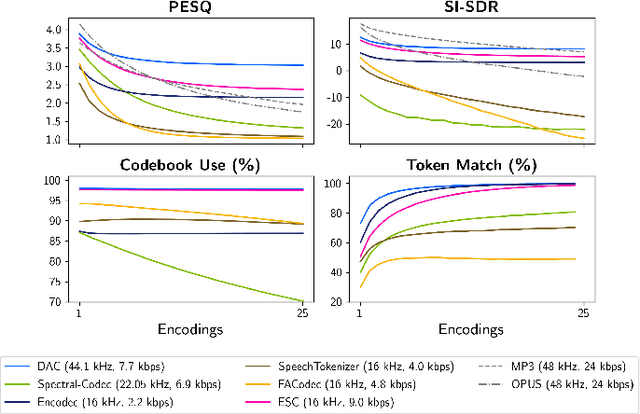
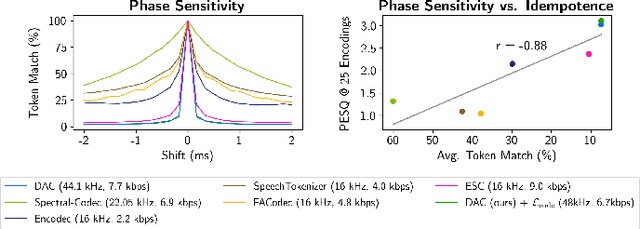
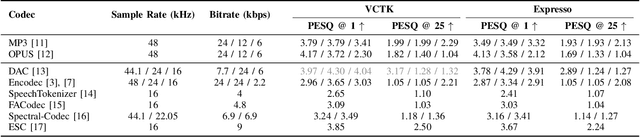
Neural codecs have demonstrated strong performance in high-fidelity compression of audio signals at low bitrates. The token-based representations produced by these codecs have proven particularly useful for generative modeling. While much research has focused on improvements in compression ratio and perceptual transparency, recent works have largely overlooked another desirable codec property -- idempotence, the stability of compressed outputs under multiple rounds of encoding. We find that state-of-the-art neural codecs exhibit varied degrees of idempotence, with some degrading audio outputs significantly after as few as three encodings. We investigate possible causes of low idempotence and devise a method for improving idempotence through fine-tuning a codec model. We then examine the effect of idempotence on a simple conditional generative modeling task, and find that increased idempotence can be achieved without negatively impacting downstream modeling performance -- potentially extending the usefulness of neural codecs for practical file compression and iterative generative modeling workflows.
Text2FX: Harnessing CLAP Embeddings for Text-Guided Audio Effects
Sep 27, 2024



This work introduces Text2FX, a method that leverages CLAP embeddings and differentiable digital signal processing to control audio effects, such as equalization and reverberation, using open-vocabulary natural language prompts (e.g., "make this sound in-your-face and bold"). Text2FX operates without retraining any models, relying instead on single-instance optimization within the existing embedding space. We show that CLAP encodes valuable information for controlling audio effects and propose two optimization approaches using CLAP to map text to audio effect parameters. While we demonstrate with CLAP, this approach is applicable to any shared text-audio embedding space. Similarly, while we demonstrate with equalization and reverberation, any differentiable audio effect may be controlled. We conduct a listener study with diverse text prompts and source audio to evaluate the quality and alignment of these methods with human perception.
Unsupervised Source Separation By Steering Pretrained Music Models
Oct 25, 2021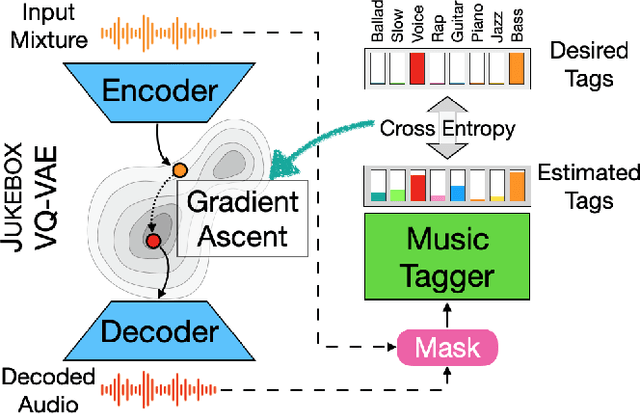
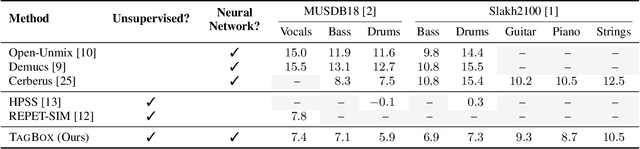
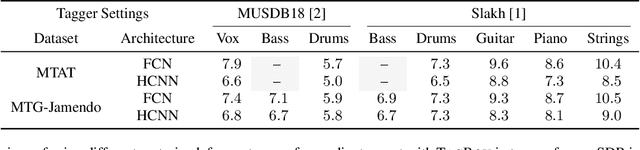
We showcase an unsupervised method that repurposes deep models trained for music generation and music tagging for audio source separation, without any retraining. An audio generation model is conditioned on an input mixture, producing a latent encoding of the audio used to generate audio. This generated audio is fed to a pretrained music tagger that creates source labels. The cross-entropy loss between the tag distribution for the generated audio and a predefined distribution for an isolated source is used to guide gradient ascent in the (unchanging) latent space of the generative model. This system does not update the weights of the generative model or the tagger, and only relies on moving through the generative model's latent space to produce separated sources. We use OpenAI's Jukebox as the pretrained generative model, and we couple it with four kinds of pretrained music taggers (two architectures and two tagging datasets). Experimental results on two source separation datasets, show this approach can produce separation estimates for a wider variety of sources than any tested supervised or unsupervised system. This work points to the vast and heretofore untapped potential of large pretrained music models for audio-to-audio tasks like source separation.