 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX-Agents
Jan 20, 2026We introduce the AI Productivity Index for Agents (APEX-Agents), a benchmark for assessing whether AI agents can execute long-horizon, cross-application tasks created by investment banking analysts, management consultants, and corporate lawyers. APEX-Agents requires agents to navigate realistic work environments with files and tools. We test eight agents for the leaderboard using Pass@1. Gemini 3 Flash (Thinking=High) achieves the highest score of 24.0%, followed by GPT-5.2 (Thinking=High), Claude Opus 4.5 (Thinking=High), and Gemini 3 Pro (Thinking=High). We open source the APEX-Agents benchmark (n=480) with all prompts, rubrics, gold outputs, files, and metadata. We also open-source Archipelago, our infrastructure for agent execution and evaluation.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
Nemotron-4 15B Technical Report
Feb 27, 2024



We introduce Nemotron-4 15B, a 15-billion-parameter large multilingual language model trained on 8 trillion text tokens. Nemotron-4 15B demonstrates strong performance when assessed on English, multilingual, and coding tasks: it outperforms all existing similarly-sized open models on 4 out of 7 downstream evaluation areas and achieves competitive performance to the leading open models in the remaining ones. Specifically, Nemotron-4 15B exhibits the best multilingual capabilities of all similarly-sized models, even outperforming models over four times larger and those explicitly specialized for multilingual tasks.
DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations
Jun 11, 2020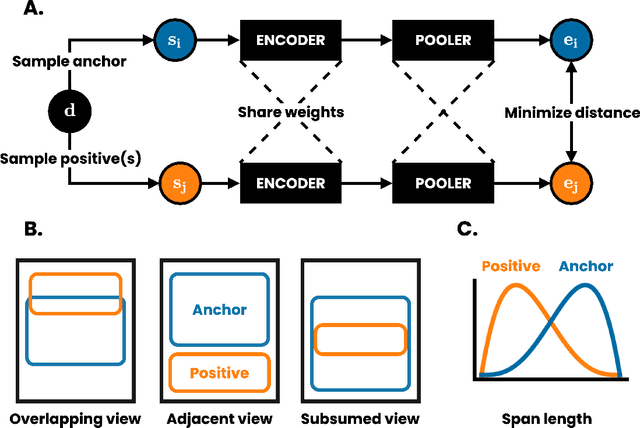
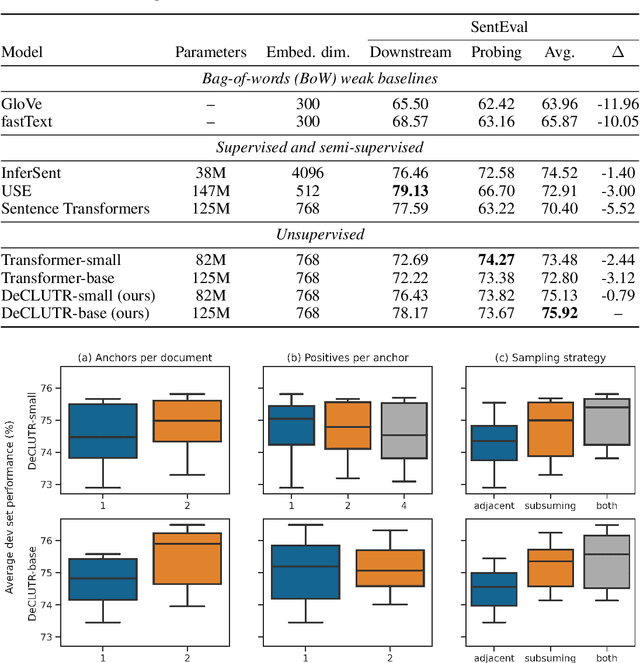
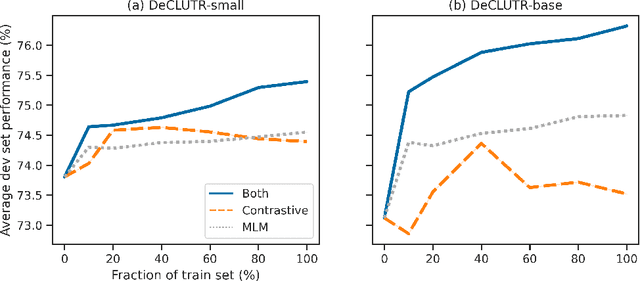
We present DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations, a self-supervised method for learning universal sentence embeddings that transfer to a wide variety of natural language processing (NLP) tasks. Our objective leverages recent advances in deep metric learning (DML) and has the advantage of being conceptually simple and easy to implement, requiring no specialized architectures or labelled training data. We demonstrate that our objective can be used to pretrain transformers to state-of-the-art performance on SentEval, a popular benchmark for evaluating universal sentence embeddings, outperforming existing supervised, semi-supervised and unsupervised methods. We perform extensive ablations to determine which factors contribute to the quality of the learned embeddings. Our code will be publicly available and can be easily adapted to new datasets or used to embed unseen text.