 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations
Jun 11, 2020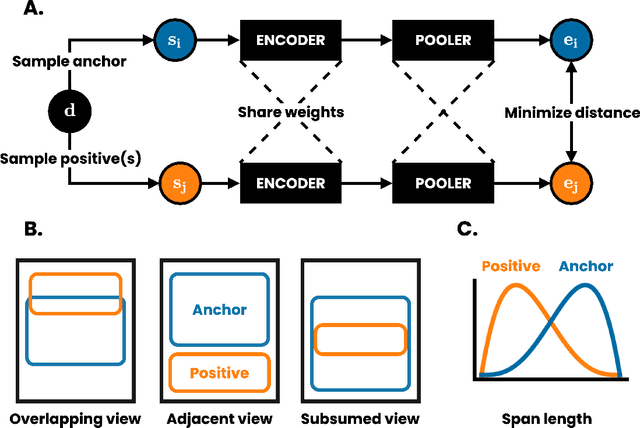
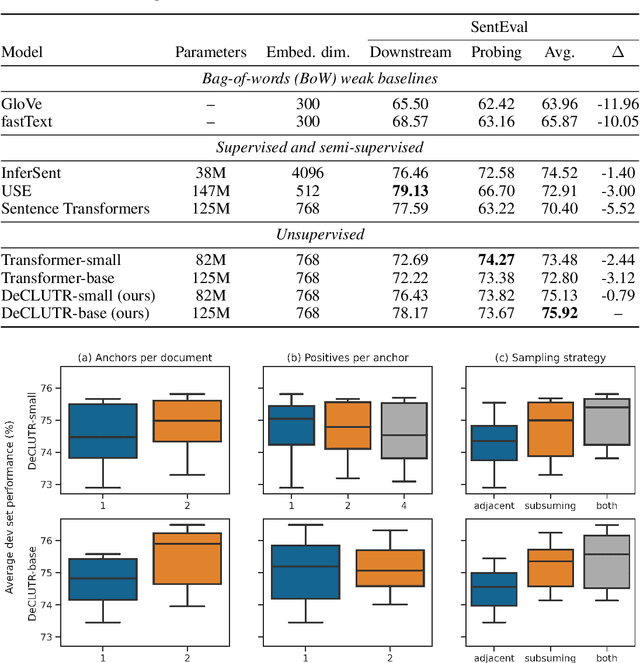
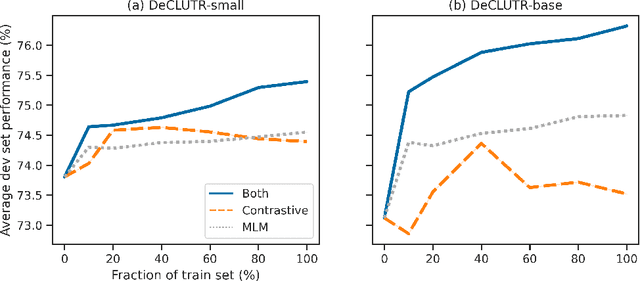
We present DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations, a self-supervised method for learning universal sentence embeddings that transfer to a wide variety of natural language processing (NLP) tasks. Our objective leverages recent advances in deep metric learning (DML) and has the advantage of being conceptually simple and easy to implement, requiring no specialized architectures or labelled training data. We demonstrate that our objective can be used to pretrain transformers to state-of-the-art performance on SentEval, a popular benchmark for evaluating universal sentence embeddings, outperforming existing supervised, semi-supervised and unsupervised methods. We perform extensive ablations to determine which factors contribute to the quality of the learned embeddings. Our code will be publicly available and can be easily adapted to new datasets or used to embed unseen text.