 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Autonomous Driving with Small-Scale Cars: A Survey of Recent Development
Apr 09, 2024While engaging with the unfolding revolution in autonomous driving, a challenge presents itself, how can we effectively raise awareness within society about this transformative trend? While full-scale autonomous driving vehicles often come with a hefty price tag, the emergence of small-scale car platforms offers a compelling alternative. These platforms not only serve as valuable educational tools for the broader public and young generations but also function as robust research platforms, contributing significantly to the ongoing advancements in autonomous driving technology. This survey outlines various small-scale car platforms, categorizing them and detailing the research advancements accomplished through their usage. The conclusion provides proposals for promising future directions in the field.
Self-organized arrival system for urban air mobility
Apr 04, 2024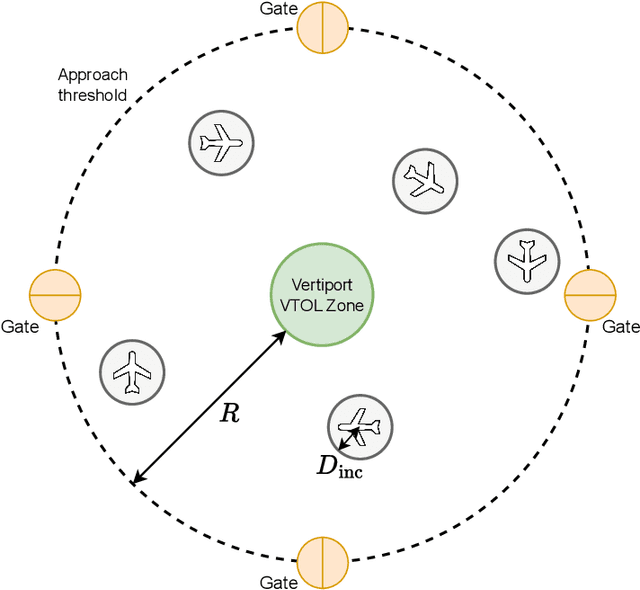

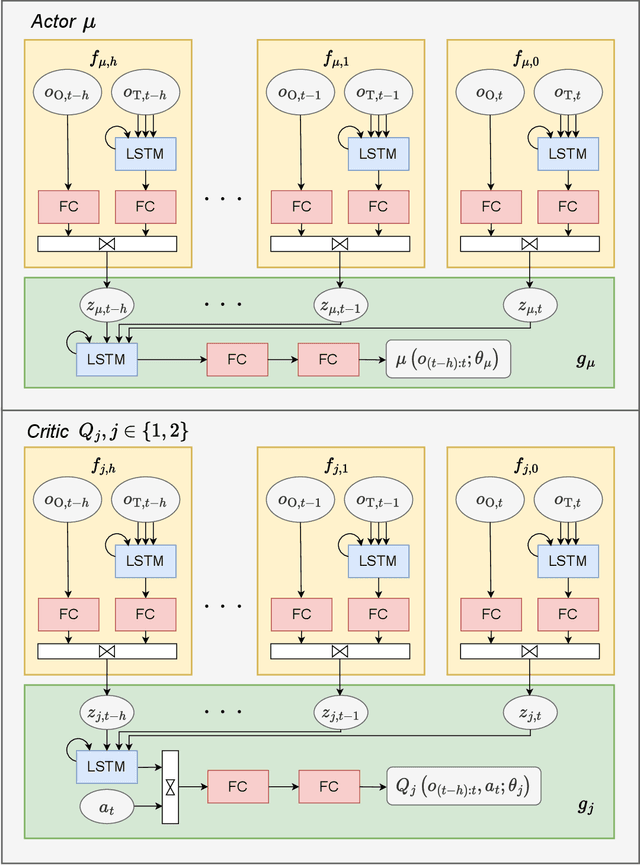
Urban air mobility is an innovative mode of transportation in which electric vertical takeoff and landing (eVTOL) vehicles operate between nodes called vertiports. We outline a self-organized vertiport arrival system based on deep reinforcement learning. The airspace around the vertiport is assumed to be circular, and the vehicles can freely operate inside. Each aircraft is considered an individual agent and follows a shared policy, resulting in decentralized actions that are based on local information. We investigate the development of the reinforcement learning policy during training and illustrate how the algorithm moves from suboptimal local holding patterns to a safe and efficient final policy. The latter is validated in simulation-based scenarios and also deployed on small-scale unmanned aerial vehicles to showcase its real-world usability.
Two-step dynamic obstacle avoidance
Nov 28, 2023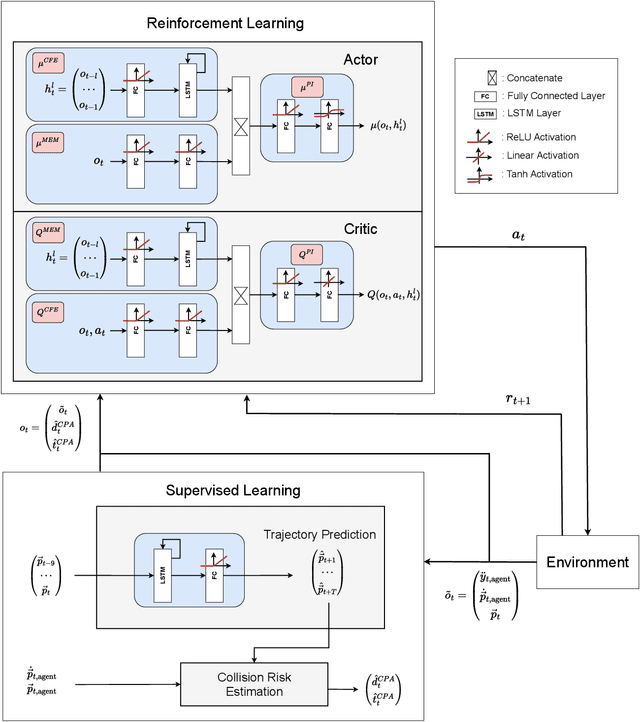
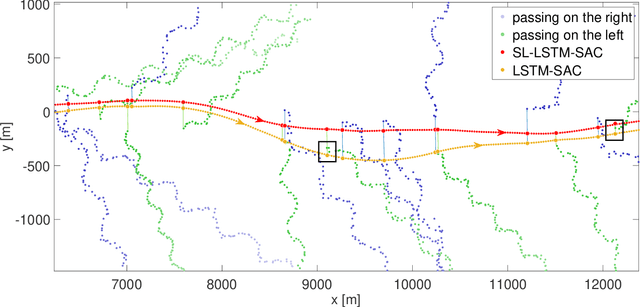


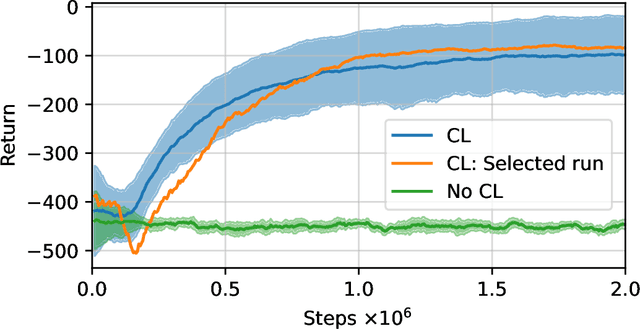
Dynamic obstacle avoidance (DOA) is a fundamental challenge for any autonomous vehicle, independent of whether it operates in sea, air, or land. This paper proposes a two-step architecture for handling DOA tasks by combining supervised and reinforcement learning (RL). In the first step, we introduce a data-driven approach to estimate the collision risk of an obstacle using a recurrent neural network, which is trained in a supervised fashion and offers robustness to non-linear obstacle movements. In the second step, we include these collision risk estimates into the observation space of an RL agent to increase its situational awareness.~We illustrate the power of our two-step approach by training different RL agents in a challenging environment that requires to navigate amid multiple obstacles. The non-linear movements of obstacles are exemplarily modeled based on stochastic processes and periodic patterns, although our architecture is suitable for any obstacle dynamics. The experiments reveal that integrating our collision risk metrics into the observation space doubles the performance in terms of reward, which is equivalent to halving the number of collisions in the considered environment. Furthermore, we show that the architecture's performance improvement is independent of the applied RL algorithm.
2-Level Reinforcement Learning for Ships on Inland Waterways
Jul 25, 2023



This paper proposes a realistic modularized framework for controlling autonomous surface vehicles (ASVs) on inland waterways (IWs) based on deep reinforcement learning (DRL). The framework comprises two levels: a high-level local path planning (LPP) unit and a low-level path following (PF) unit, each consisting of a DRL agent. The LPP agent is responsible for planning a path under consideration of nearby vessels, traffic rules, and the geometry of the waterway. We thereby leverage a recently proposed spatial-temporal recurrent neural network architecture, which is transferred to continuous action spaces. The PF agent is responsible for low-level actuator control while accounting for shallow water influences on the marine craft and the environmental forces winds, waves, and currents. Both agents are thoroughly validated in simulation, employing the lower Elbe in northern Germany as an example case and using real AIS trajectories to model the behavior of other ships.
Vision-based DRL Autonomous Driving Agent with Sim2Real Transfer
May 19, 2023To achieve fully autonomous driving, vehicles must be capable of continuously performing various driving tasks, including lane keeping and car following, both of which are fundamental and well-studied driving ones. However, previous studies have mainly focused on individual tasks, and car following tasks have typically relied on complete leader-follower information to attain optimal performance. To address this limitation, we propose a vision-based deep reinforcement learning (DRL) agent that can simultaneously perform lane keeping and car following maneuvers. To evaluate the performance of our DRL agent, we compare it with a baseline controller and use various performance metrics for quantitative analysis. Furthermore, we conduct a real-world evaluation to demonstrate the Sim2Real transfer capability of the trained DRL agent. To the best of our knowledge, our vision-based car following and lane keeping agent with Sim2Real transfer capability is the first of its kind.
A Platform-Agnostic Deep Reinforcement Learning Framework for Effective Sim2Real Transfer in Autonomous Driving
Apr 14, 2023Deep Reinforcement Learning (DRL) has shown remarkable success in solving complex tasks across various research fields. However, transferring DRL agents to the real world is still challenging due to the significant discrepancies between simulation and reality. To address this issue, we propose a robust DRL framework that leverages platform-dependent perception modules to extract task-relevant information and train a lane-following and overtaking agent in simulation. This framework facilitates the seamless transfer of the DRL agent to new simulated environments and the real world with minimal effort. We evaluate the performance of the agent in various driving scenarios in both simulation and the real world, and compare it to human players and the PID baseline in simulation. Our proposed framework significantly reduces the gaps between different platforms and the Sim2Real gap, enabling the trained agent to achieve similar performance in both simulation and the real world, driving the vehicle effectively.
Enhanced method for reinforcement learning based dynamic obstacle avoidance by assessment of collision risk
Dec 08, 2022

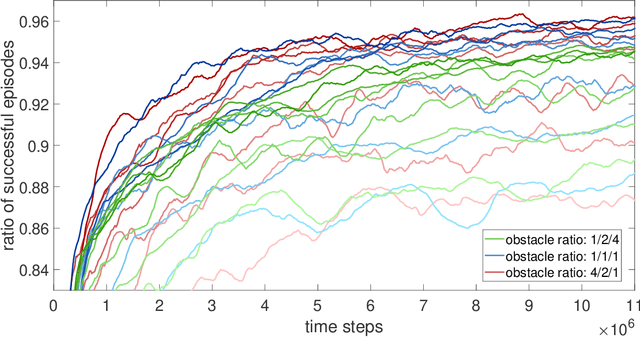

In the field of autonomous robots, reinforcement learning (RL) is an increasingly used method to solve the task of dynamic obstacle avoidance for mobile robots, autonomous ships, and drones. A common practice to train those agents is to use a training environment with random initialization of agent and obstacles. Such approaches might suffer from a low coverage of high-risk scenarios in training, leading to impaired final performance of obstacle avoidance. This paper proposes a general training environment where we gain control over the difficulty of the obstacle avoidance task by using short training episodes and assessing the difficulty by two metrics: The number of obstacles and a collision risk metric. We found that shifting the training towards a greater task difficulty can massively increase the final performance. A baseline agent, using a traditional training environment based on random initialization of agent and obstacles and longer training episodes, leads to a significantly weaker performance. To prove the generalizability of the proposed approach, we designed two realistic use cases: A mobile robot and a maritime ship under the threat of approaching obstacles. In both applications, the previous results can be confirmed, which emphasizes the general usability of the proposed approach, detached from a specific application context and independent of the agent's dynamics. We further added Gaussian noise to the sensor signals, resulting in only a marginal degradation of performance and thus indicating solid robustness of the trained agent.
Spatial-temporal recurrent reinforcement learning for autonomous ships
Nov 02, 2022The paper proposes a spatial-temporal recurrent neural network architecture for Deep $Q$-Networks to steer an autonomous ship. The network design allows handling an arbitrary number of surrounding target ships while offering robustness to partial observability. Further, a state-of-the-art collision risk metric is proposed to enable an easier assessment of different situations by the agent. The COLREG rules of maritime traffic are explicitly considered in the design of the reward function. The final policy is validated on a custom set of newly created single-ship encounters called "Around the Clock" problems and the commonly chosen Imazu (1987) problems, which include 18 multi-ship scenarios. Additionally, the framework shows robustness when deployed simultaneously in multi-agent scenarios. The proposed network architecture is compatible with other deep reinforcement learning algorithms, including actor-critic frameworks.
Vessel-following model for inland waterways based on deep reinforcement learning
Jul 07, 2022
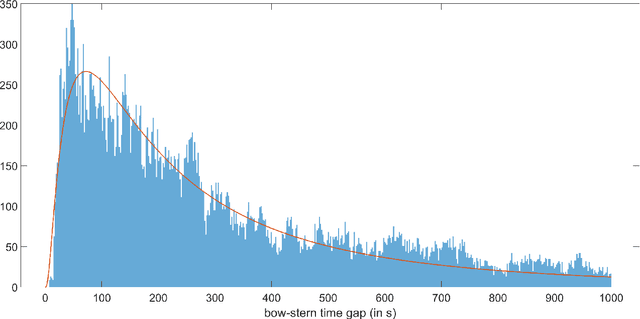
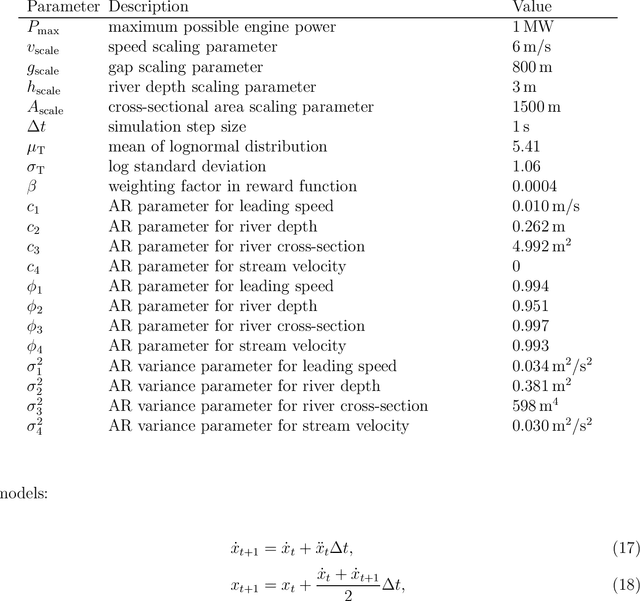
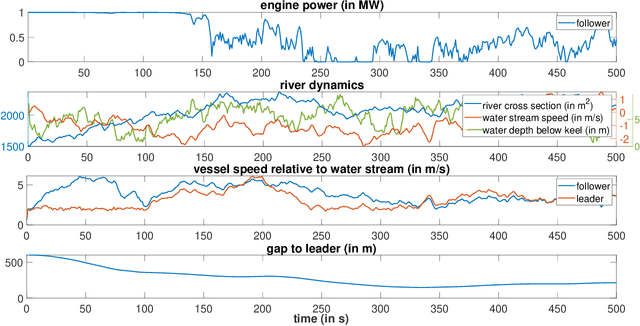
While deep reinforcement learning (RL) has been increasingly applied in designing car-following models in the last years, this study aims at investigating the feasibility of RL-based vehicle-following for complex vehicle dynamics and strong environmental disturbances. As a use case, we developed an inland waterways vessel-following model based on realistic vessel dynamics, which considers environmental influences, such as varying stream velocity and river profile. We extracted natural vessel behavior from anonymized AIS data to formulate a reward function that reflects a realistic driving style next to comfortable and safe navigation. Aiming at high generalization capabilities, we propose an RL training environment that uses stochastic processes to model leading trajectory and river dynamics. To validate the trained model, we defined different scenarios that have not been seen in training, including realistic vessel-following on the Middle Rhine. Our model demonstrated safe and comfortable driving in all scenarios, proving excellent generalization abilities. Furthermore, traffic oscillations could effectively be dampened by deploying the trained model on a sequence of following vessels.
Two-Sample Testing in Reinforcement Learning
Jan 20, 2022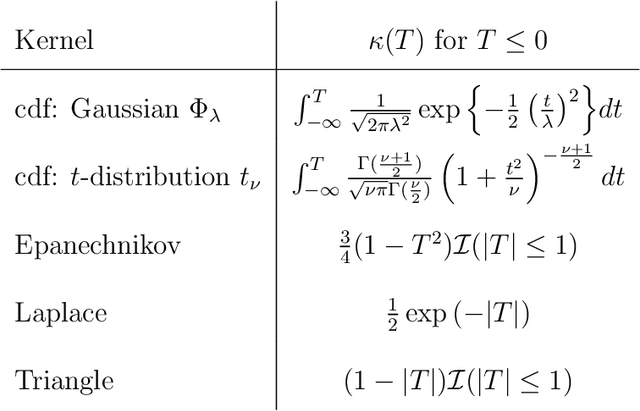
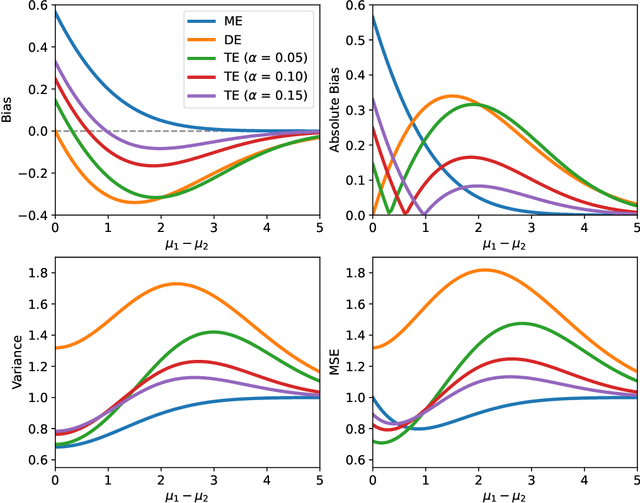
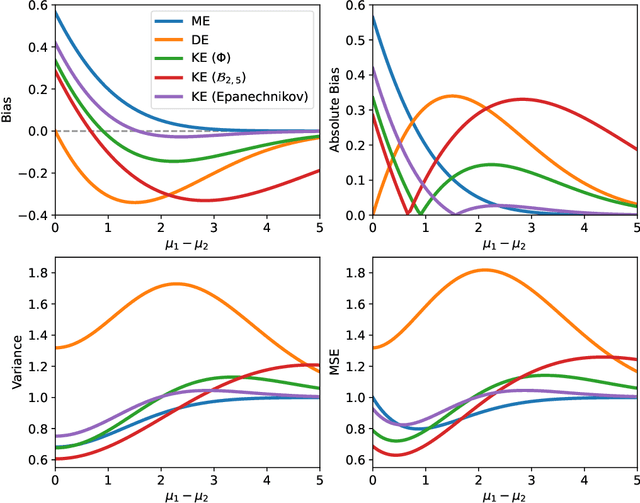
Value-based reinforcement-learning algorithms have shown strong performances in games, robotics, and other real-world applications. The most popular sample-based method is $Q$-Learning. A $Q$-value is the expected return for a state-action pair when following a particular policy, and the algorithm subsequently performs updates by adjusting the current $Q$-value towards the observed reward and the maximum of the $Q$-values of the next state. The procedure introduces maximization bias, and solutions like Double $Q$-Learning have been considered. We frame the bias problem statistically and consider it an instance of estimating the maximum expected value (MEV) of a set of random variables. We propose the $T$-Estimator (TE) based on two-sample testing for the mean. The TE flexibly interpolates between over- and underestimation by adjusting the level of significance of the underlying hypothesis tests. A generalization termed $K$-Estimator (KE) obeys the same bias and variance bounds as the TE while relying on a nearly arbitrary kernel function. Using the TE and the KE, we introduce modifications of $Q$-Learning and its neural network analog, the Deep $Q$-Network. The proposed estimators and algorithms are thoroughly tested and validated on a diverse set of tasks and environments, illustrating the performance potential of the TE and KE.