 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-step dynamic obstacle avoidance
Nov 28, 2023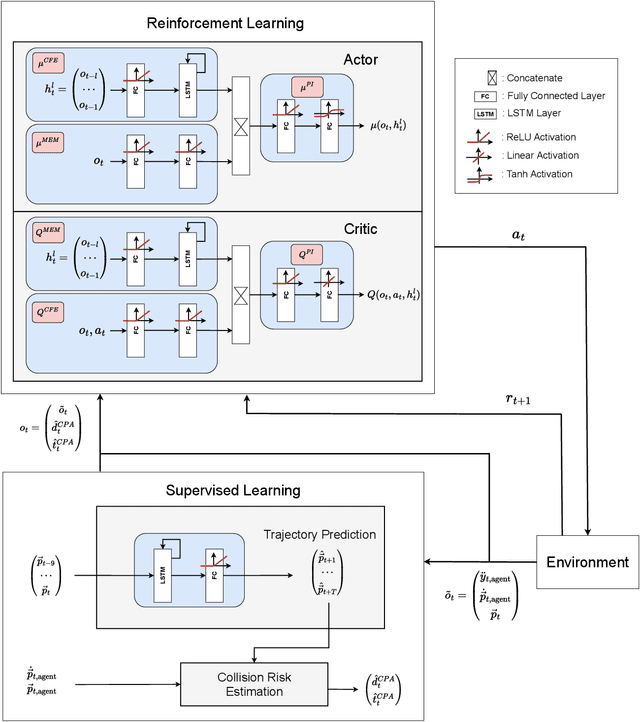


Dynamic obstacle avoidance (DOA) is a fundamental challenge for any autonomous vehicle, independent of whether it operates in sea, air, or land. This paper proposes a two-step architecture for handling DOA tasks by combining supervised and reinforcement learning (RL). In the first step, we introduce a data-driven approach to estimate the collision risk of an obstacle using a recurrent neural network, which is trained in a supervised fashion and offers robustness to non-linear obstacle movements. In the second step, we include these collision risk estimates into the observation space of an RL agent to increase its situational awareness.~We illustrate the power of our two-step approach by training different RL agents in a challenging environment that requires to navigate amid multiple obstacles. The non-linear movements of obstacles are exemplarily modeled based on stochastic processes and periodic patterns, although our architecture is suitable for any obstacle dynamics. The experiments reveal that integrating our collision risk metrics into the observation space doubles the performance in terms of reward, which is equivalent to halving the number of collisions in the considered environment. Furthermore, we show that the architecture's performance improvement is independent of the applied RL algorithm.
Enhanced method for reinforcement learning based dynamic obstacle avoidance by assessment of collision risk
Dec 08, 2022

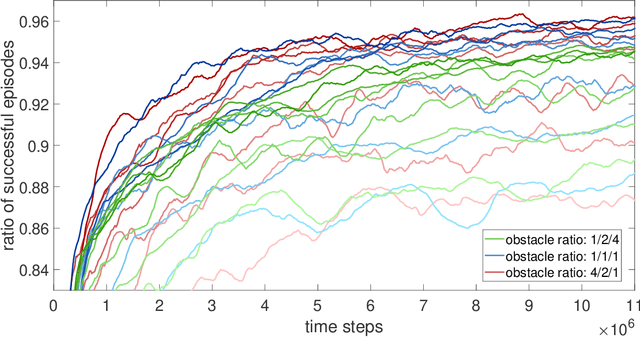

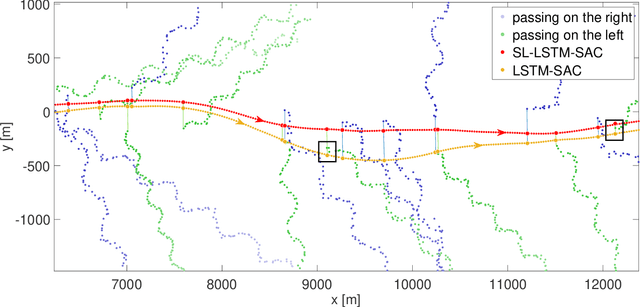
In the field of autonomous robots, reinforcement learning (RL) is an increasingly used method to solve the task of dynamic obstacle avoidance for mobile robots, autonomous ships, and drones. A common practice to train those agents is to use a training environment with random initialization of agent and obstacles. Such approaches might suffer from a low coverage of high-risk scenarios in training, leading to impaired final performance of obstacle avoidance. This paper proposes a general training environment where we gain control over the difficulty of the obstacle avoidance task by using short training episodes and assessing the difficulty by two metrics: The number of obstacles and a collision risk metric. We found that shifting the training towards a greater task difficulty can massively increase the final performance. A baseline agent, using a traditional training environment based on random initialization of agent and obstacles and longer training episodes, leads to a significantly weaker performance. To prove the generalizability of the proposed approach, we designed two realistic use cases: A mobile robot and a maritime ship under the threat of approaching obstacles. In both applications, the previous results can be confirmed, which emphasizes the general usability of the proposed approach, detached from a specific application context and independent of the agent's dynamics. We further added Gaussian noise to the sensor signals, resulting in only a marginal degradation of performance and thus indicating solid robustness of the trained agent.
Vessel-following model for inland waterways based on deep reinforcement learning
Jul 07, 2022
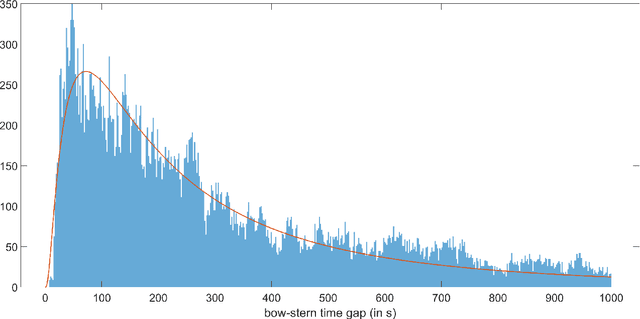
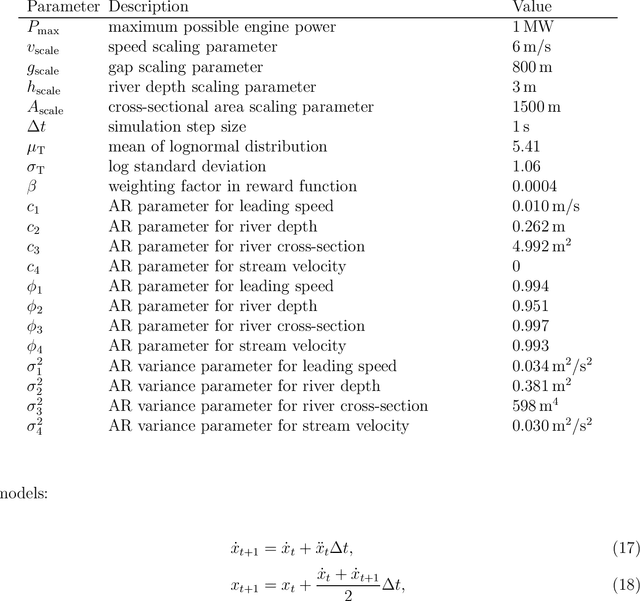
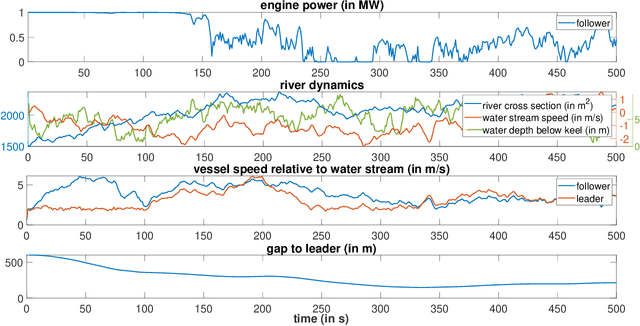
While deep reinforcement learning (RL) has been increasingly applied in designing car-following models in the last years, this study aims at investigating the feasibility of RL-based vehicle-following for complex vehicle dynamics and strong environmental disturbances. As a use case, we developed an inland waterways vessel-following model based on realistic vessel dynamics, which considers environmental influences, such as varying stream velocity and river profile. We extracted natural vessel behavior from anonymized AIS data to formulate a reward function that reflects a realistic driving style next to comfortable and safe navigation. Aiming at high generalization capabilities, we propose an RL training environment that uses stochastic processes to model leading trajectory and river dynamics. To validate the trained model, we defined different scenarios that have not been seen in training, including realistic vessel-following on the Middle Rhine. Our model demonstrated safe and comfortable driving in all scenarios, proving excellent generalization abilities. Furthermore, traffic oscillations could effectively be dampened by deploying the trained model on a sequence of following vessels.
Missing Velocity in Dynamic Obstacle Avoidance based on Deep Reinforcement Learning
Dec 28, 2021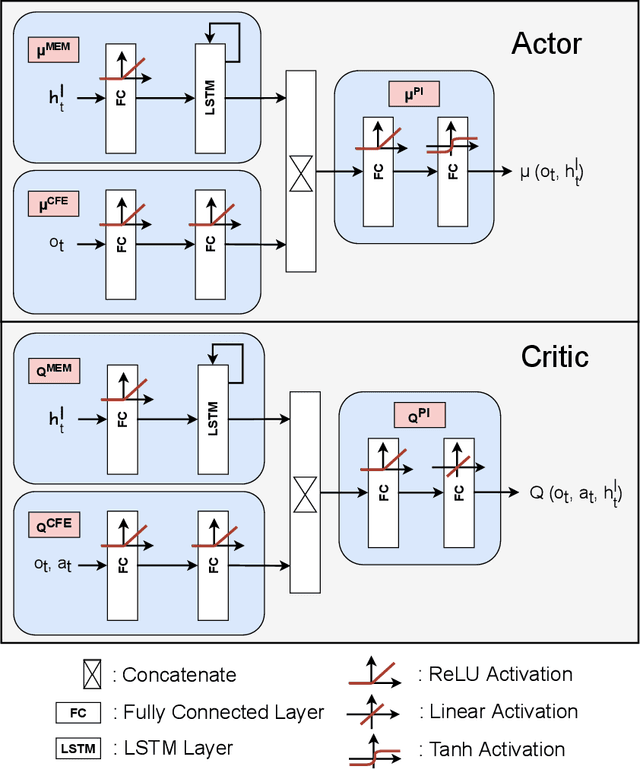

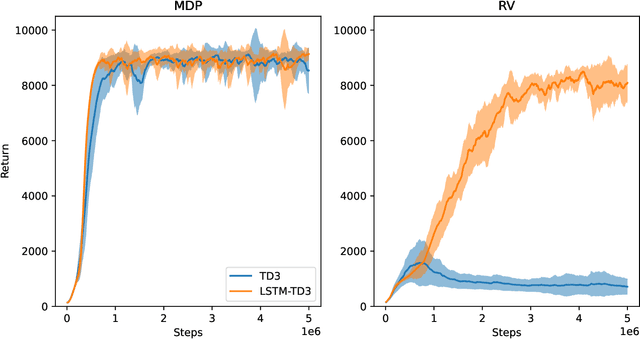

We introduce a novel approach to dynamic obstacle avoidance based on Deep Reinforcement Learning by defining a traffic type independent environment with variable complexity. Filling a gap in the current literature, we thoroughly investigate the effect of missing velocity information on an agent's performance in obstacle avoidance tasks. This is a crucial issue in practice since several sensors yield only positional information of objects or vehicles. We evaluate frequently-applied approaches in scenarios of partial observability, namely the incorporation of recurrency in the deep neural networks and simple frame-stacking. For our analysis, we rely on state-of-the-art model-free deep RL algorithms. The lack of velocity information is found to significantly impact the performance of an agent. Both approaches - recurrency and frame-stacking - cannot consistently replace missing velocity information in the observation space. However, in simplified scenarios, they can significantly boost performance and stabilize the overall training procedure.
Formulation and validation of a car-following model based on deep reinforcement learning
Sep 29, 2021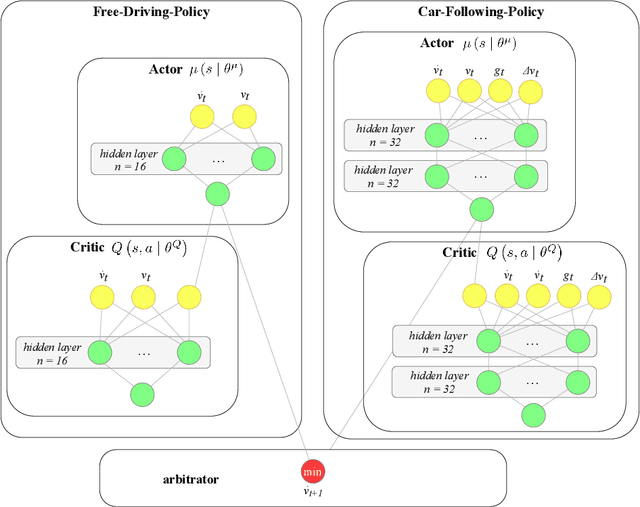
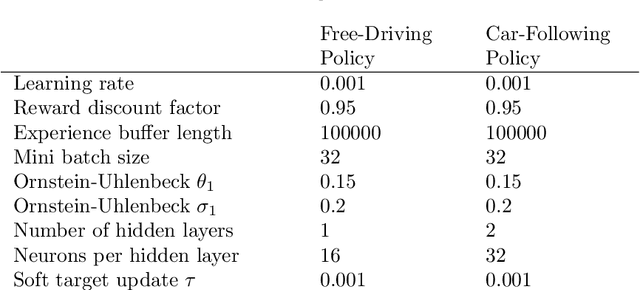
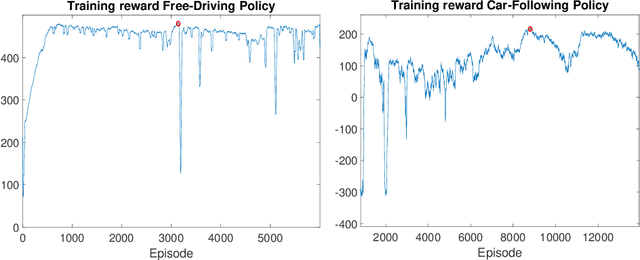

We propose and validate a novel car following model based on deep reinforcement learning. Our model is trained to maximize externally given reward functions for the free and car-following regimes rather than reproducing existing follower trajectories. The parameters of these reward functions such as desired speed, time gap, or accelerations resemble that of traditional models such as the Intelligent Driver Model (IDM) and allow for explicitly implementing different driving styles. Moreover, they partially lift the black-box nature of conventional neural network models. The model is trained on leading speed profiles governed by a truncated Ornstein-Uhlenbeck process reflecting a realistic leader's kinematics. This allows for arbitrary driving situations and an infinite supply of training data. For various parameterizations of the reward functions, and for a wide variety of artificial and real leader data, the model turned out to be unconditionally string stable, comfortable, and crash-free. String stability has been tested with a platoon of five followers following an artificial and a real leading trajectory. A cross-comparison with the IDM calibrated to the goodness-of-fit of the relative gaps showed a higher reward compared to the traditional model and a better goodness-of-fit.