 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVessel-following model for inland waterways based on deep reinforcement learning
Jul 07, 2022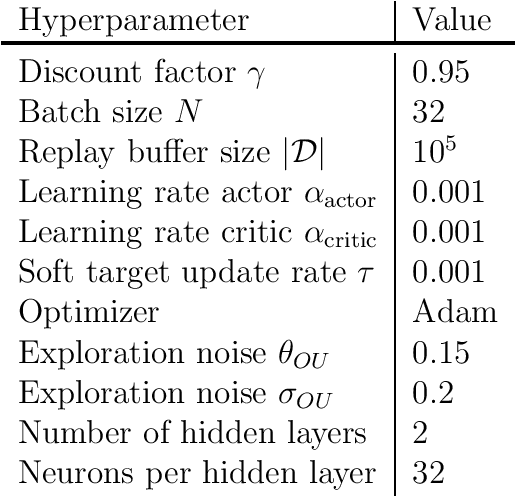
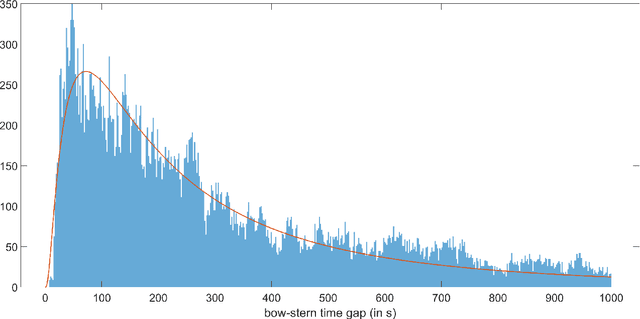
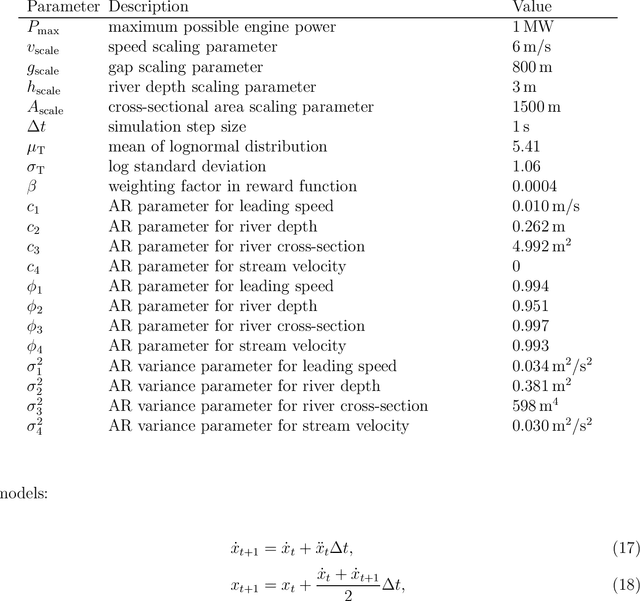
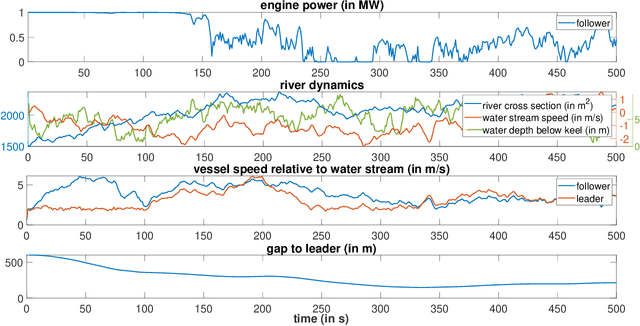
While deep reinforcement learning (RL) has been increasingly applied in designing car-following models in the last years, this study aims at investigating the feasibility of RL-based vehicle-following for complex vehicle dynamics and strong environmental disturbances. As a use case, we developed an inland waterways vessel-following model based on realistic vessel dynamics, which considers environmental influences, such as varying stream velocity and river profile. We extracted natural vessel behavior from anonymized AIS data to formulate a reward function that reflects a realistic driving style next to comfortable and safe navigation. Aiming at high generalization capabilities, we propose an RL training environment that uses stochastic processes to model leading trajectory and river dynamics. To validate the trained model, we defined different scenarios that have not been seen in training, including realistic vessel-following on the Middle Rhine. Our model demonstrated safe and comfortable driving in all scenarios, proving excellent generalization abilities. Furthermore, traffic oscillations could effectively be dampened by deploying the trained model on a sequence of following vessels.
Formulation and validation of a car-following model based on deep reinforcement learning
Sep 29, 2021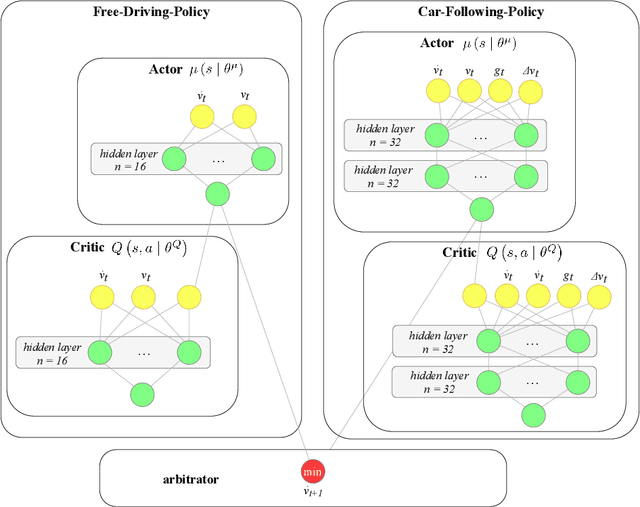
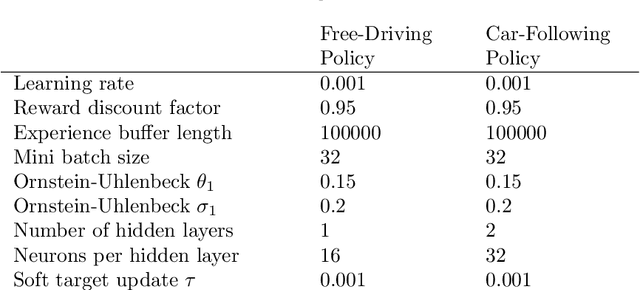
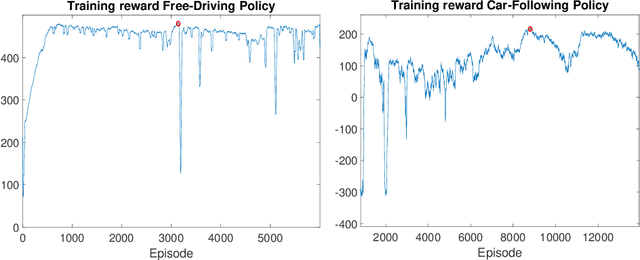

We propose and validate a novel car following model based on deep reinforcement learning. Our model is trained to maximize externally given reward functions for the free and car-following regimes rather than reproducing existing follower trajectories. The parameters of these reward functions such as desired speed, time gap, or accelerations resemble that of traditional models such as the Intelligent Driver Model (IDM) and allow for explicitly implementing different driving styles. Moreover, they partially lift the black-box nature of conventional neural network models. The model is trained on leading speed profiles governed by a truncated Ornstein-Uhlenbeck process reflecting a realistic leader's kinematics. This allows for arbitrary driving situations and an infinite supply of training data. For various parameterizations of the reward functions, and for a wide variety of artificial and real leader data, the model turned out to be unconditionally string stable, comfortable, and crash-free. String stability has been tested with a platoon of five followers following an artificial and a real leading trajectory. A cross-comparison with the IDM calibrated to the goodness-of-fit of the relative gaps showed a higher reward compared to the traditional model and a better goodness-of-fit.